
一.openvino-dev介绍
众所周知,OpenVINO™ 工具包是一个用于优化和部署人工智能推理的开源工具包。可用于开发基于深度学习任务的应用和解决方案,例如:模拟人类视觉、自动语音识别、自然语言处理、推荐系统等。它提供高性能和丰富的部署选项,从边缘到云端。
OpenVINO™ Development Tools(简称Openvino-dev)使您能够从 Open Model Zoo 下载模型,将您自己的模型转换为 OpenVINO IR,以及优化和调整预训练的深度学习模型。openvino-dev软件包将OpenVINO™ Runtime安装为依赖项,它是运行深度学习模型的引擎,并包含一组库,可轻松将推理集成到您的应用程序中,而不必像以前那样下载体积比较大的源文件编译包,目前支持的最新版本为2022.3.0。
二.系统要求
由于新的安装方式依赖于python环境,所以对python的版本有所要求。大家可以按下图对应版本检查环境是否一致。
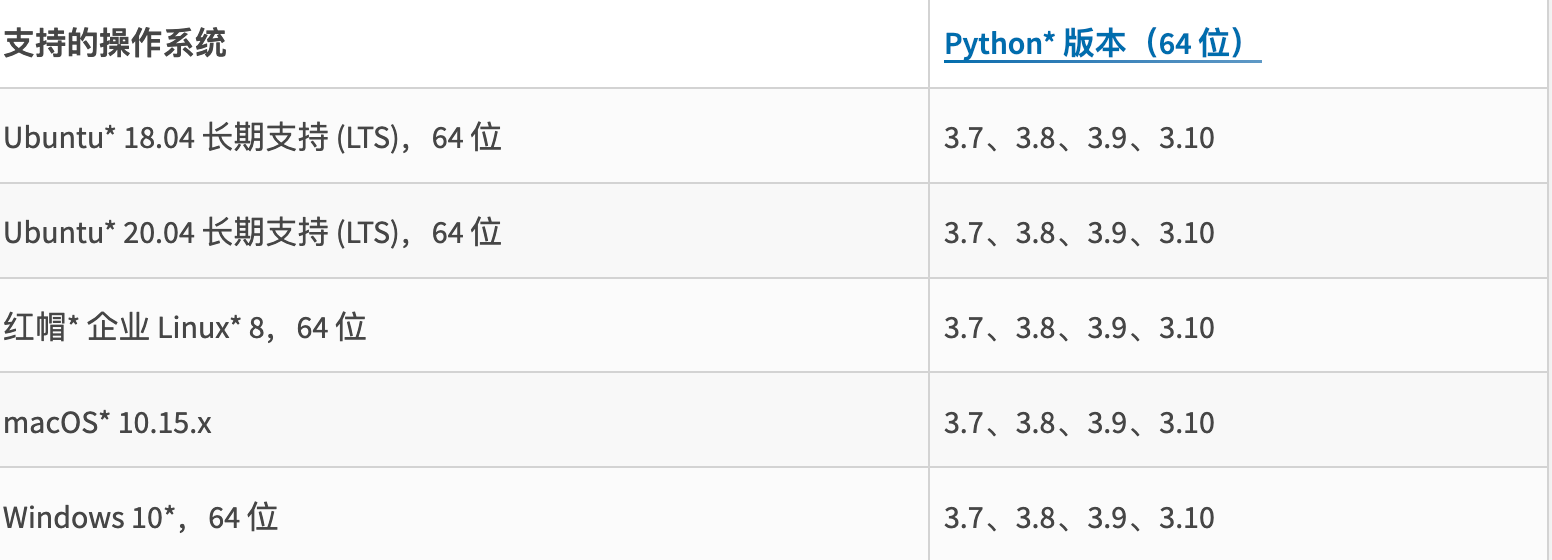
在 Windows* 上安装也需要C++ 库。要安装它,可以下载 Visual Studio Redistributable 文件 (.exe)。
三.安装openvino-dev
步骤1:
我们通常使用虚拟环境来避免依赖冲突,要创建虚拟环境,请使用下列命令:
sudo apt install python3-venv
python3 -m venv openvino_env
步骤2:
激活虚拟环境
# On Linux and macOS:
source openvino_env/bin/activate
# On Windows:
openvino_env\Scripts\activate
步骤3:
这里有两种方式安装openvino-dev,默认安装方式如下:
python3 -m pip install --upgrade pip
pip3 install openvino-dev
还可以为特定框架安装组件:
pip install openvino-dev[extras]
# extras : caffe、kaldi、mxnet、onnx、pytorch、tensorflow、tensorflow2
e.g.:
pip install openvino-dev[pytorch,onnx,caffee]
openvino-dev软件包默认安装以下组件:
| Parameter | Cmd |
|---|---|
| Model Optimizer | mo |
| Benchmark Tool | benchmark_app |
| Accuracy Checker | accuracy_check |
| Annotation Converter | convert_annotation |
| Post-Training Optimization Tool | pot |
| Model Downloader and other Open Model Zoo tools | omz_downloader、omz_converter、omz_quantizer、omz_info_dumper |
四.下载、优化和量化yolov4模型
现在我们安装好了openvino-dev的环境,接下来我们尝试使用上述表格提到的工具演示一下如何下载、优化和量化yolov4模型。
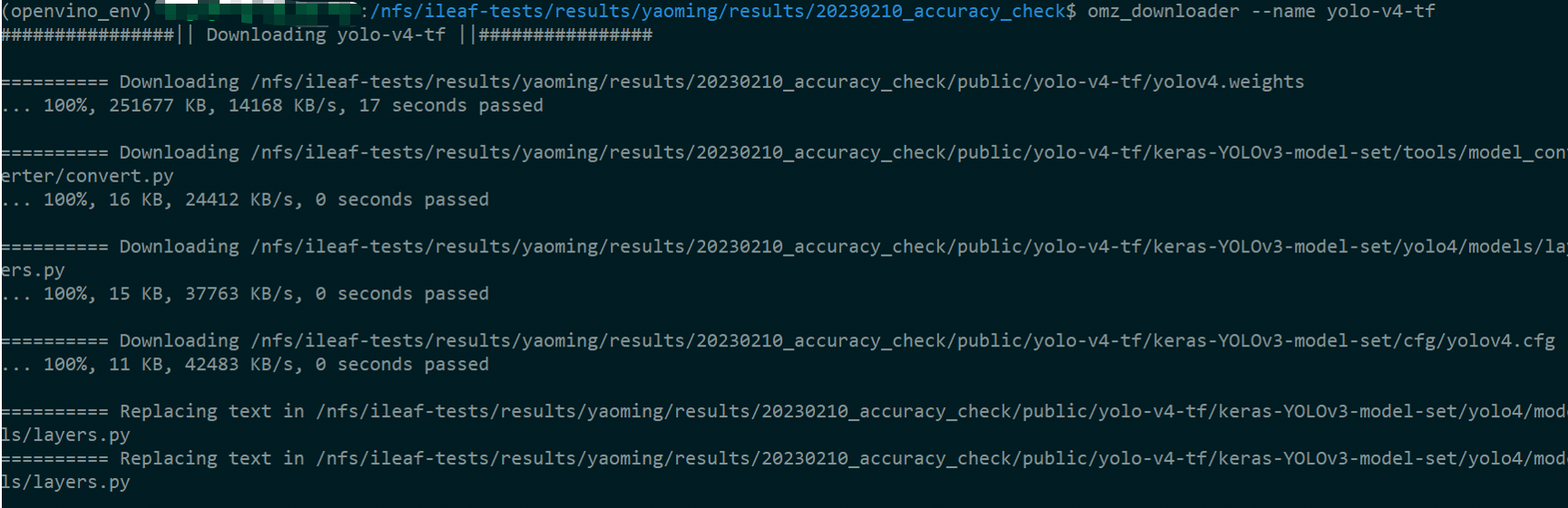
1.使用模型下载器下载yolov4
omz_downloader --name yolo-v4-tf
下图可以看到在当前路径下会生成public文件夹,yolo-v4-tf的模型信息会存放在该文件夹下。
2.使用模型优化器来优化模型
由于该模型是tensorflow2转换过来的,所以我们需要安装一下相关的requirements_tf2.txt环境。转换成功后会自动生成FP32、FP16两种格式的IR文件。
git clone https://github.com/openvinotoolkit/openvino.git
cd openvino/tools/mo
python -m pip install -r requirements_tf2.txt
cd ../../../
omz_converter --name yolo-v4-tf -d ./ -o ./ --mo openvino/tools/mo/openvino/tools/mo/mo.py
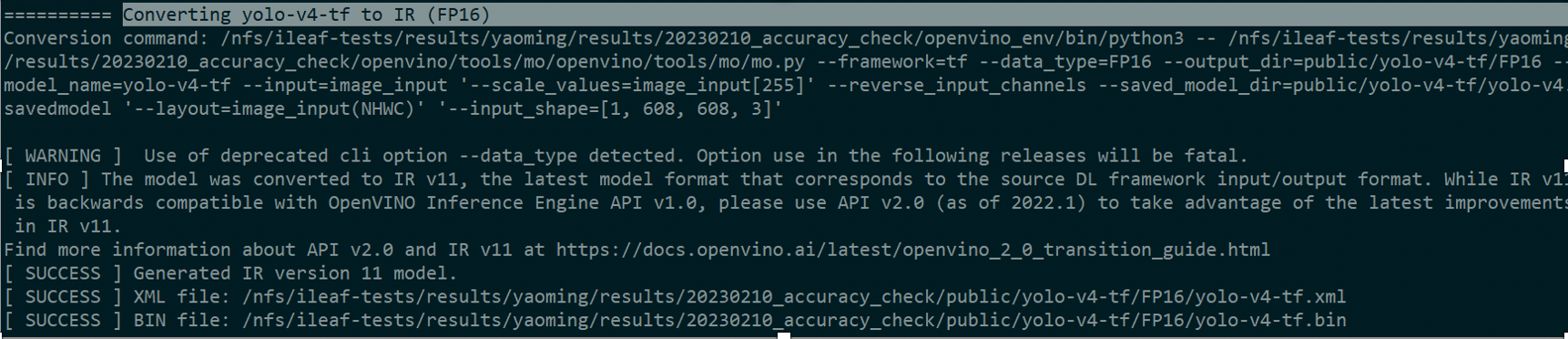
如下图,我们在FP16的文件夹可以找到相关转换好的模型文件。

3.量化模型
针对训练后优化的需要,OpenVINO 提供了支持统一整数量化方法的训练后优化工具(POT)。此方法允许在推理时间内将权重和激活从浮点精度移动到整数精度(例如,8 位)。它有助于减少模型大小、内存占用和延迟,并使用整数算法提高计算效率。在量化过程中,当将包含量化信息的附加操作插入到模型中时,模型会经历转换过程。到整数算术的实际转换发生在模型推理时。
POT 提供了两种可以使用的量化方法:Default Quantization 和 Accuracy-aware Quantization。
默认量化使用未注释的数据集来执行量化。它使用具有代表性的数据集项来估计网络中激活值的范围,然后对网络进行量化。建议首先使用此方法,因为在大多数情况下它会产生快速且准确的模型,接下来演示的就是该方法。
精度感知量化是一种高级方法,它通过不量化某些网络层来将模型精度保持在预定义范围内。它使用速度和准确性之间的权衡来满足用户指定的要求。此方法需要带注释的数据集,并且可能需要更多时间进行量化。
pot -q default -m public/yolo-v4-tf/FP16/yolo-v4-tf.xml -w public/yolo-v4-tf/FP16/yolo-v4-tf.bin --name yolov4_int8 --output-dir ./ --engine simplified --data-source val2017/
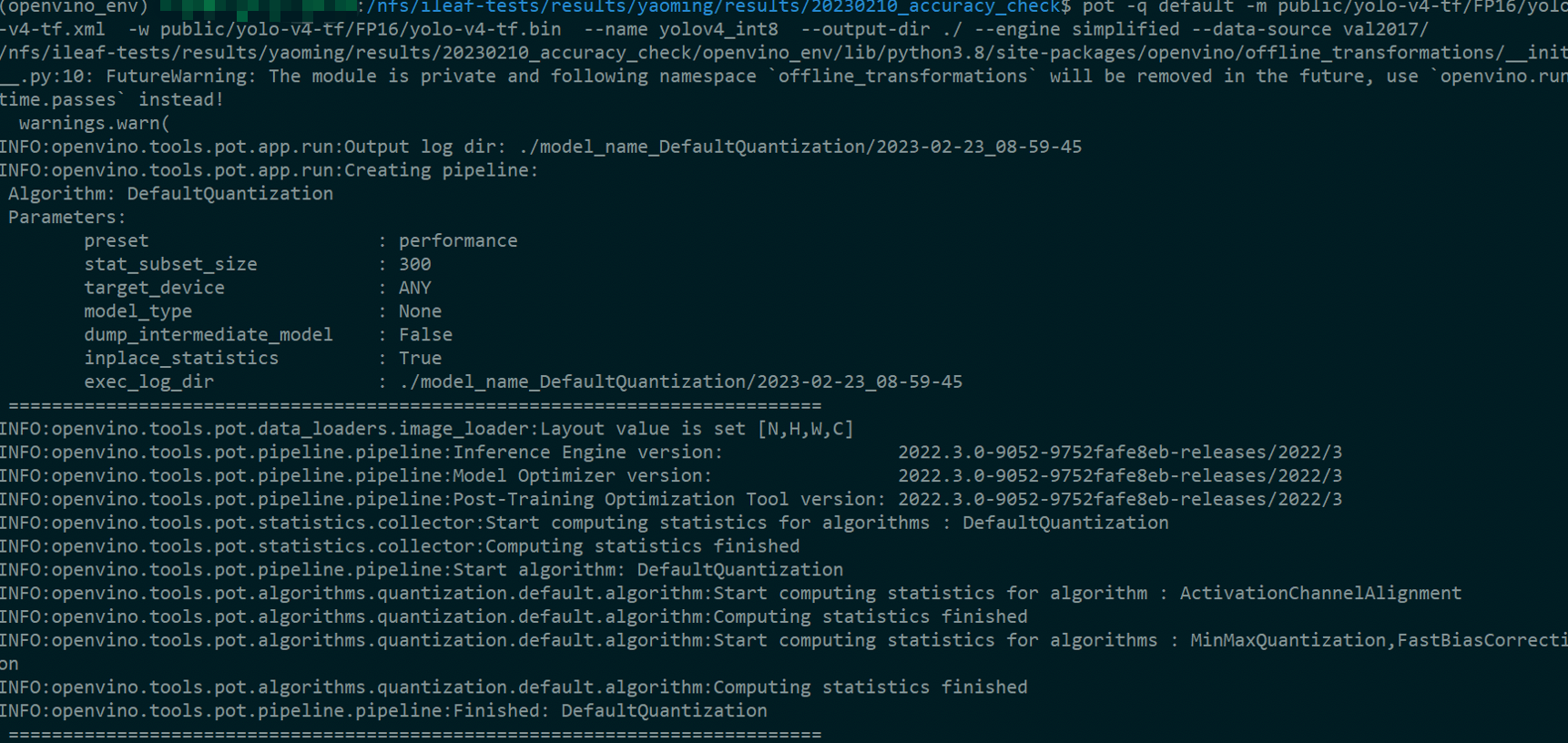
如下图,我们在该路径下可以找到量化完成的模型文件。

虽然训练后量化可以使您的模型运行得更快并占用更少的内存,但它可能会导致准确性略有下降。这时候可以使用前面提到的Accuracy Checker工具对模型进行准确度检查,以判断是否符合我们的要求,如果大家对这块感兴趣,之后可以单独介绍,这里先不赘述。