
一. nn.Module
nn.Module 是torch.nn提供的一个类,是pytorch中自定义网络的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类定义网络的时候非常简单。
当我们自定义网络的时候,有两个方法需要特别注意:
__init__需要调用super方法,继承父类的属性和方法farward方法必须实现,用来定义我们的网络的向前计算的过程
用前面的y = wx+b的模型举例如下:
from torch import nn
class Lr(nn.Module):
def __init__(self):
#继承父类init的参数
super(Lr, self).__init__()
# 输入的特征数量,输出的特征数量
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
注意:
nn.Linear为torch预定义好的线性模型,也被称为全链接层,传入的参数为输入的数量,输出的数量(in_features, out_features),是不算(batch_size的列数)nn.Module定义了__call__方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数调用,实际上调用的是forward方法并传入参数
# 实例化模型
model = Lr()
# 传入数据,计算结果
predict = model(x)
二. 优化器类
优化器(optimizer),可以理解为torch为我们封装的用来进行更新参数的方法,比如常见的随机梯度下降(stochastic gradient descent,SGD)
优化器类都是由torch.optim提供的,例如
torch.optim.SGD(参数,学习率)torch.optim.Adam(参数,学习率)
注意:
- 参数可以使用
model.parameters()来获取,获取模型中所有requires_grad=True的参数 - 优化类的使用方法
- 实例化
- 所有参数的梯度,将其值置为0
- 反向传播计算梯度
- 更新参数值
示例如下:
optimizer = optim.SGD(model.parameters(), lr=1e-3) #1. 实例化
optimizer.zero_grad() #2. 梯度置为0
loss.backward() #3. 计算梯度
optimizer.step() #4. 更新参数的值
三. 损失函数
前面的例子是一个回归问题,torch中也预测了很多损失函数
- 均方误差:
nn.MSELoss(),常用于回归问题 - 交叉熵损失:
nn.CrossEntropyLoss(),常用于分类问题
使用方法:
model = Lr() #1. 实例化模型
criterion = nn.MSELoss() #2. 实例化损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) #3. 实例化优化器类
for i in range(100):
y_predict = model(x_true) #4. 向前计算预测值
loss = criterion(y_true,y_predict) #5. 调用损失函数传入真实值和预测值,得到损失结果
optimizer.zero_grad() #5. 当前循环参数梯度置为0
loss.backward() #6. 计算梯度
optimizer.step() #7. 更新参数的值
四. 线性回归完整代码
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
out = self.linear(x)
return out
# 2. 实例化模型,loss,和优化器
model = Lr()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#3. 训练模型
for i in range(30000):
out = model(x) #3.1 获取预测值
loss = criterion(y,out) #3.2 计算损失
optimizer.zero_grad() #3.3 梯度归零
loss.backward() #3.4 计算梯度
optimizer.step() # 3.5 更新梯度
if (i+1) % 20 == 0:
print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))
print(list(model.parameters()))
#4. 模型评估
model.eval() #设置模型为评估模式,即预测模式
predict = model(x)
predict = predict.data.numpy()
plt.scatter(x.data.numpy(),y.data.numpy(),c="r")
plt.plot(x.data.numpy(),predict)
plt.show()
输出如下:
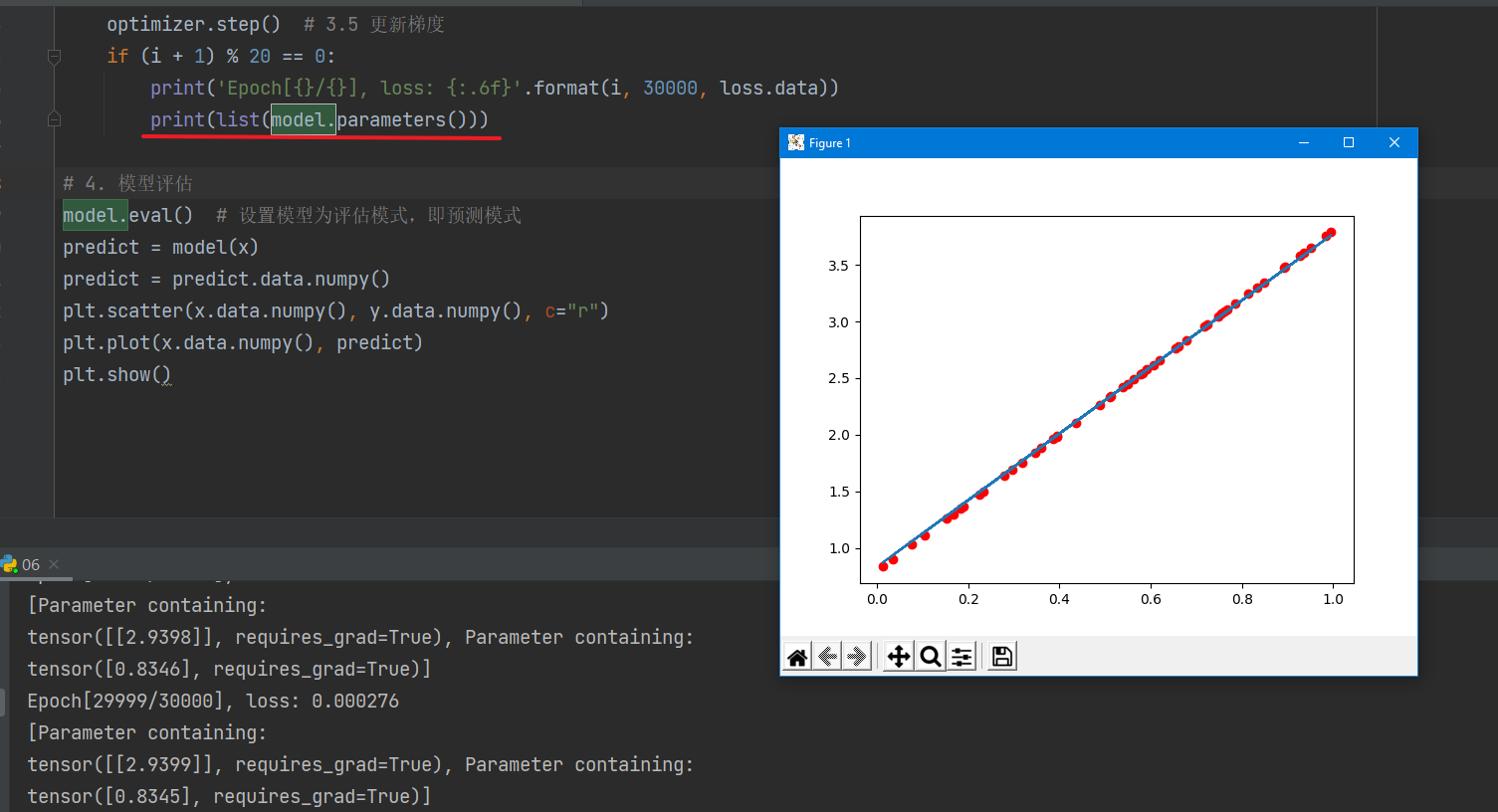
注意:
model.eval()表示设置模型为评估模式,即预测模式
model.train(mode=True) 表示设置模型为训练模式
在当前的线性回归中,上述并无区别
但是在其他的一些模型中,训练的参数和预测的参数会不相同,到时候就需要具体告诉程序我们是在进行训练还是预测,比如模型中存在Dropout,BatchNorm的时候
五.在GPU上运行代码
当模型太大,或者参数太多的情况下,为了加快训练速度,经常会使用GPU来进行训练。
此时我们的代码需要稍作调整:
- 判断GPU是否可用
torch.cuda.is_available()
torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
>>device(type='cuda', index=0) #使用gpu
>>device(type='cpu') #使用cpu
- 把模型参数和input数据转化为cuda的支持类型
model.to(device)
x_true.to(device)
- 在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者torch的cpu的tensor类型
predict = predict.cpu().detach().numpy()
detach()的效果和data的相似,但是detach()是深拷贝,data是取值,是浅拷贝
修改之后的代码如下:
import torch
from torch import nn
from torch import optim
import numpy as np
from matplotlib import pyplot as plt
import time
# 1. 定义数据
x = torch.rand([50,1])
y = x*3 + 0.8
#2 .定义模型
class Lr(nn.Module):
def __init__(self):
super(Lr,self).__init__()
self.linear = nn.Linear(1,1)
def forward(self, x):
out = self.linear(x)
return out
# 2. 实例化模型,loss,和优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x,y = x.to(device),y.to(device)
model = Lr().to(device)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
#3. 训练模型
for i in range(300):
out = model(x)
loss = criterion(y,out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 20 == 0:
print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data))
#4. 模型评估
model.eval() #
predict = model(x)
predict = predict.cpu().detach().numpy() #转化为numpy数组
plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c="r")
plt.plot(x.cpu().data.numpy(),predict,)
plt.show()
在GPU执行程序:
-
1.自定义的参数和数据,需要转化为cuda支持的tensor
-
2.model需要转化为cuda支持的model
-
3.执行的结果需要和cpu的tensor计算的时候,
tensor.cpu()可以把cuda的tensor转化为cpu的tensor