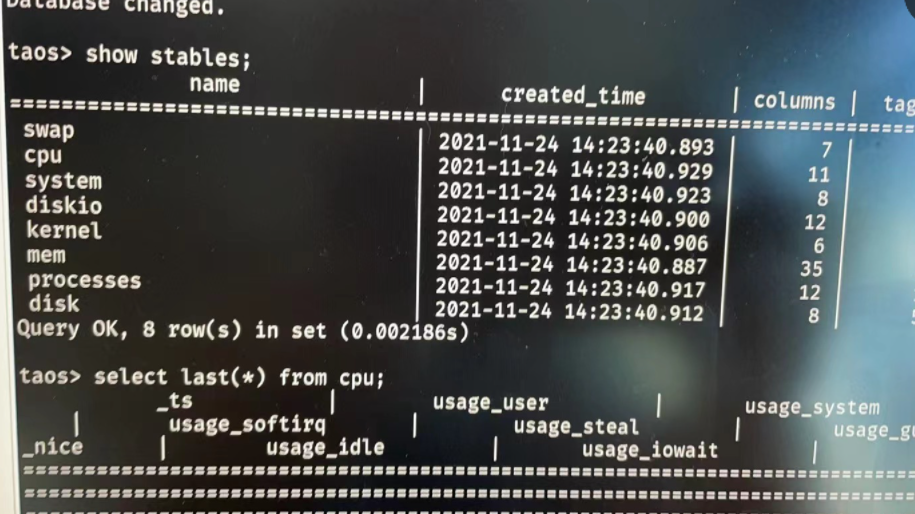
全文字数2465,预计阅读10min
一.前言
出于对技术选型的验证评估,我们想搭建一个容器化的Tdengine集群。但是官方文档说不建议在生产环境中部署容器化集群。问了下技术人员,回复说容器化的部署会损失部分性能,具体损失百分之多少,由于docker资源是灵活分配的,不好做标准评估。所以先搭建一个物理集群,熟悉一下集群配置的具体流程,为容器化的集群应用做准备。
二.集群相关概念介绍
1.什么是FQDN
FQDN(fully qualified domain name,完全限定域名)是internet上特定计算机或主机的完整域名。FQDN由两部分组成:主机名和域名。集群的每个节点是由End Point来唯一标识的,End Point是由FQDN外加Port组成,比如 h1.taosdata.com:6030。这样当IP发生变化的时候,我们依然可以使用FQDN来动态找到节点,不需要更改集群的任何配置。 当然如果本地配置了DNS服务器,就不用配置FQDN了。
2.新加入集群的dnode,配置项需要注意什么?
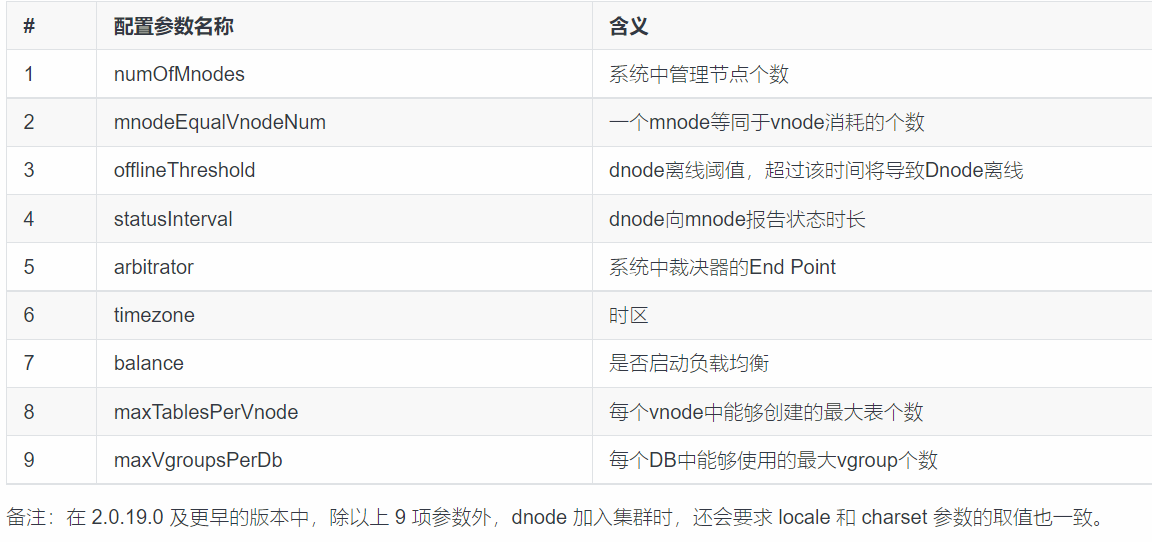
加入到集群中的数据节点dnode,涉及集群相关的下表11项参数必须完全相同。新节点要加入集群前,需先清理/var/lib/taos的数据。注意两个独立的集群是无法合并为一个新的集群的。
3.什么是dnode、vnode、vgroup、Mnode?
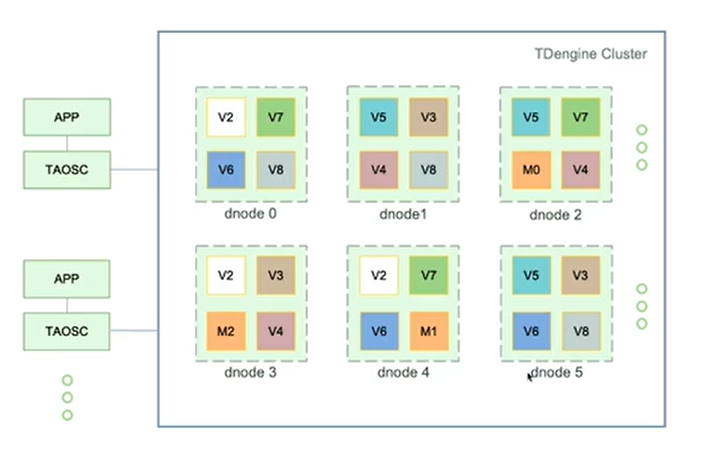
dnode:代表一个tdengine实例,一个物理节点可以创建一个或多个dnode,一般只创建一个。通过将dnode进行虚拟化拆分为vnode和Mnode
vnode:负责存储实际数据,一个dnode中有多个vnode,可以设置副本数
vgroup: 虚拟节点组,实现副本的管理。一个vgroup可以包含多个vnode。同一个vgroup组当中的vnode的数据是实时同步的。
Mnode:TDengine集群是由Mnode (taosd的一个模块,管理节点) 负责管理的,一个系统是必须有至少一个Mnode的,但可以有多个副本数。
APP通过taosc只要访问集群任意节点,就可以访问整个集群。
4.vnode的高可用
TDengine通过多副本的机制来提供系统的高可用性。vnode的副本数是与DB关联的,一个集群里可以有多个DB。创建数据库时,通过参数replica 指定副本数(默认为1)。replica大于等于2,才具有高可用,且副本数不能超出节点的个数。
5.Mnode的高可用
Mnode副本数由系统配置参数numOfMnodes决定,有效范围为1-3。为保证元数据的强一致性,Mnode副本之间是通过同步的方式进行数据复制的。
当集群中第一个数据节点启动时,该数据节点一定会运行一个Mnode实例,否则该数据节点dnode无法正常工作。如果numOfMnodes配置为2,启动第二个dnode时,该dnode也将运行一个Mnode实例。为保证Mnode服务的高可用性,numOfMnodes必须设置为2或更大。
注意:
一个tdengine高可用系统,无论是vnode还是Mnode, 都必须配置多个副本。目前官方推荐的配置方式为双副本加Arbitrator,这样可以提升系统的可用性。
6.负载均衡
有三种情况,将触发负载均衡,而且都无需人工干预。
- 当一个新数据节点添加进集群时,系统将自动触发负载均衡,一些节点上的数据将被自动转移到新数据节点上,无需任何人工干预。
- 当一个数据节点从集群中移除时,系统将自动把该数据节点上的数据转移到其他数据节点,无需任何人工干预。
- 如果一个数据节点过热(数据量过大),系统将自动进行负载均衡,将该数据节点的一些vnode自动挪到其他节点。
7.Arbitrator
副本数为偶数时,比如当一个 vnode group 里一半或超过一半的 vnode 不工作时,是无法从中选出 master 的。为了解决这个问题引入了arb,可以防止split brain情形。
arb的原理是模拟一个 vnode 或 Mnode 在工作,但只简单的负责网络连接,不处理任何数据插入或访问。只要包含 Arbitrator 在内,超过半数的 vnode 或 Mnode 工作,那么该 vnode group 或 Mnode 组就可以正常的提供数据插入或查询服务。比如对于副本数为 2 的情形,如果一个节点 A 离线,但另外一个节点 B 正常,而且能连接到 Arbitrator,那么节点 B 就能正常工作。
三.规划物理节点
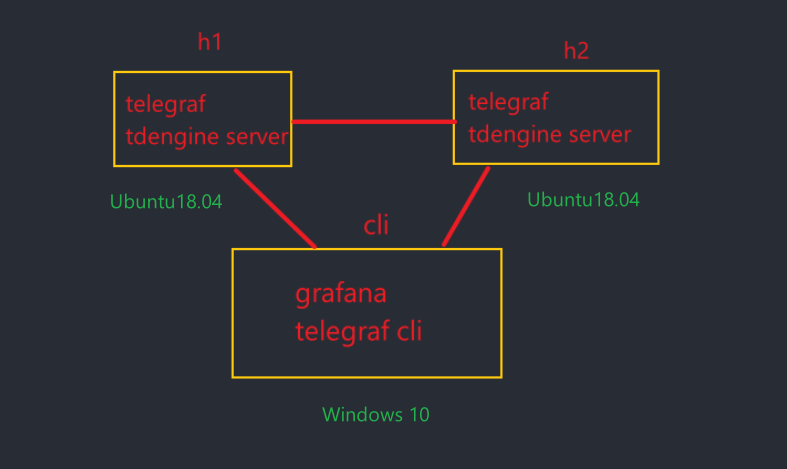
这里我用两台机器做数据的采集和存储,用FQDN(Fully Qualified Domain Name,完全限定域名)来进行节点之间的通信。应用端无需配置集群节点IP/FQDN地址,而仅配置firstEP实现集群寻址。

四.运行环境
在h1、h2节点部署了telegref、tdengine采集存储数据,在cli端部署了tdengine的客户端程序和grafana,便于数据的展示。
五.搭建过程
1.检查环境
- 清理环境
如果搭建集群的物理节点中,存有之前的测试数据、装过1.X的版本,或者装过其他版本的TDengine,请先将其删除,并清空所有数据(rm -rf /var/lib/taos/*)。
- 关闭防火墙,开启对应的端口
关闭所有物理节点的防火墙,至少保证端口:6030 - 6042的TCP和UDP端口都是开放的
- 服务器的时钟同步
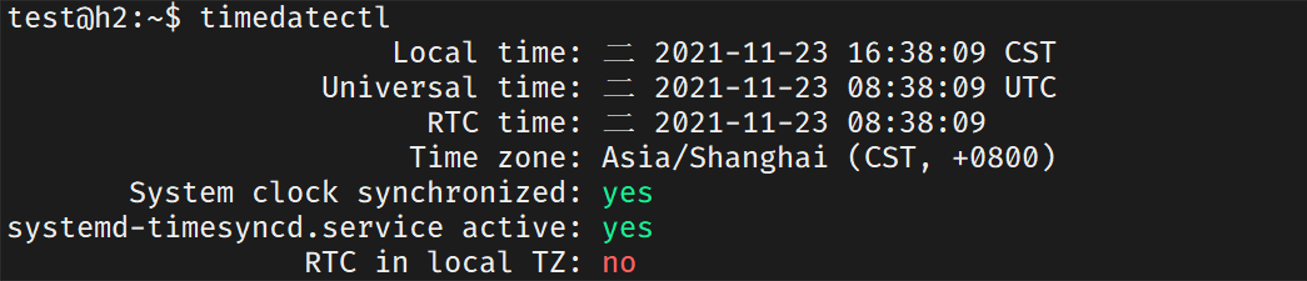
Ubuntu的默认安装现在使用timesyncd而不是ntpd。各节点终端输入timedatectl将打印出本地时间,通用时间(如果您没有从UTC时区切换,可能与本地时间相同),以及一些网络时间状态信息。要确保每个节点都开启同步。
System clock synchronized:
yes表示时间已成功同步,
systemd-timesyncd.service active: yes表示已启用并运行timesyncd
2.配置节点的FQDN解析
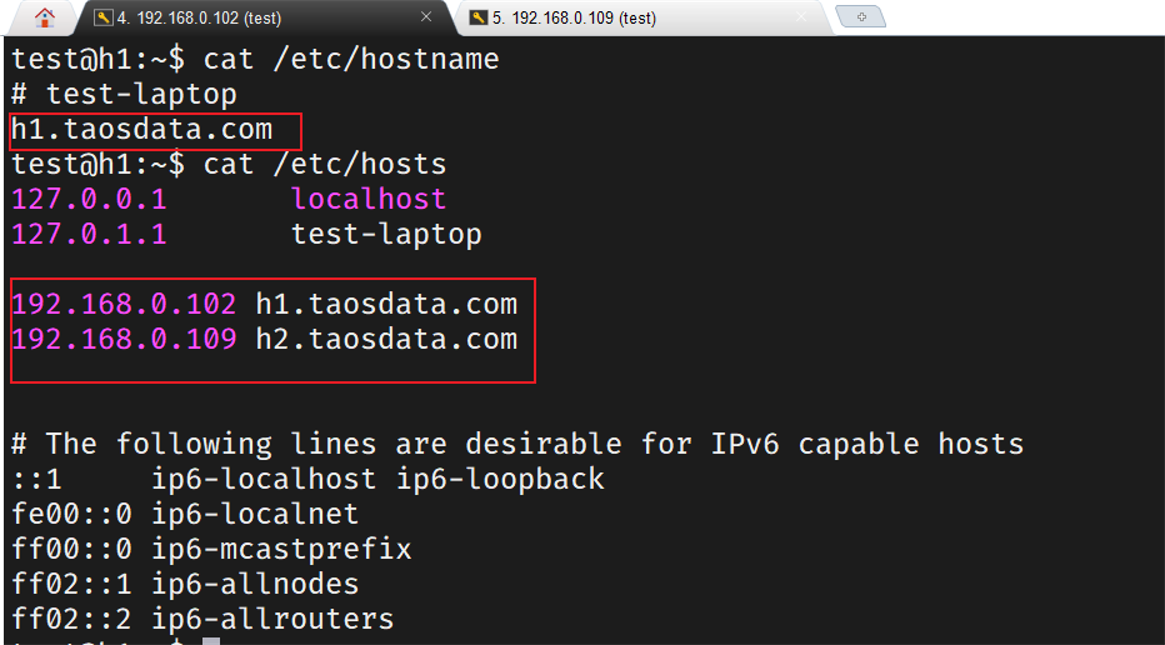
规划集群所有物理节点的FQDN,将规划好的FQDN分别添加到每个物理节点的/etc/hostname;修改每个物理节点的/etc/hosts,将所有集群物理节点的IP与FQDN的对应添加好。
配置h1节点
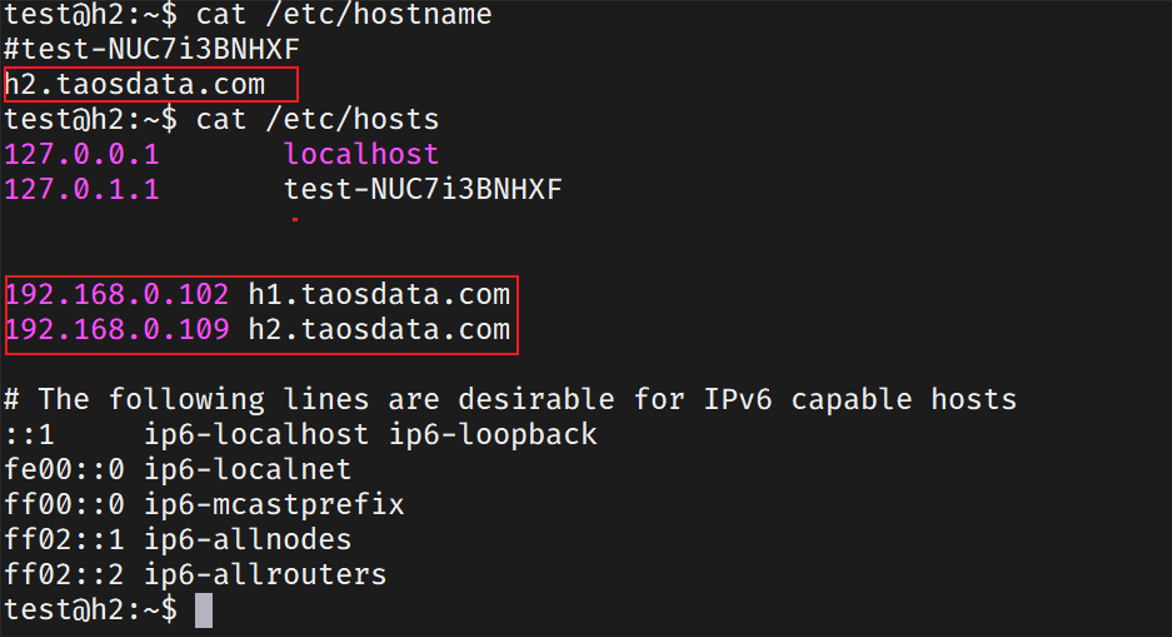
配置h2节点
重启系统
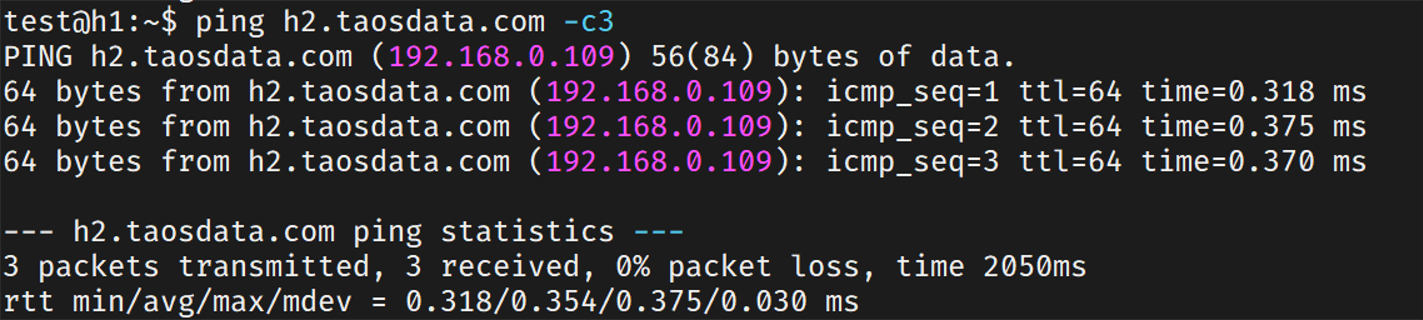
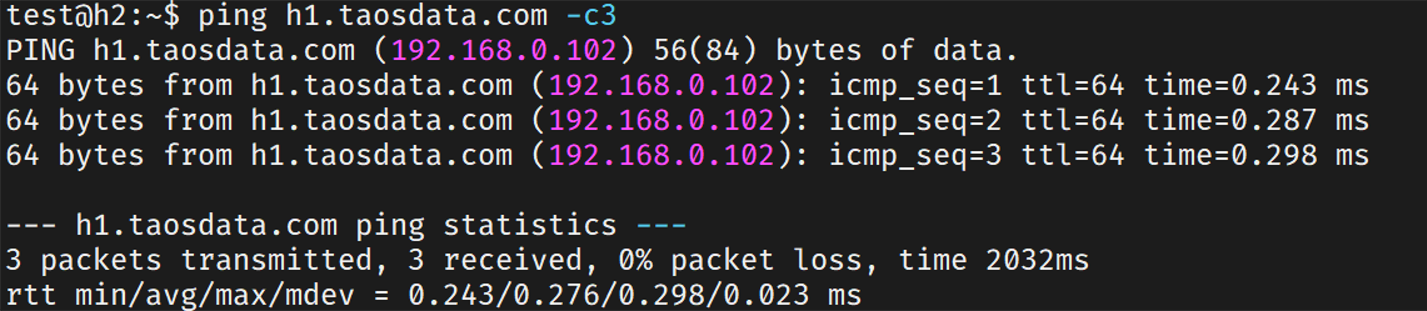
在h1节点ping h2节点,看到fqdn解析成功。
在h2节点ping h1节点,解析成功。
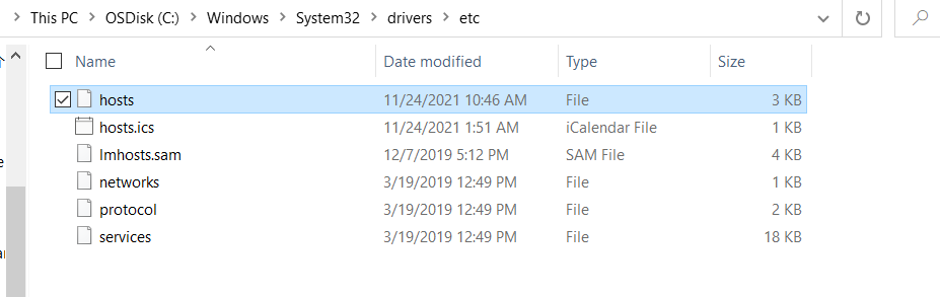
在客户端,首先配置hosts,在以下路径打开hosts文件
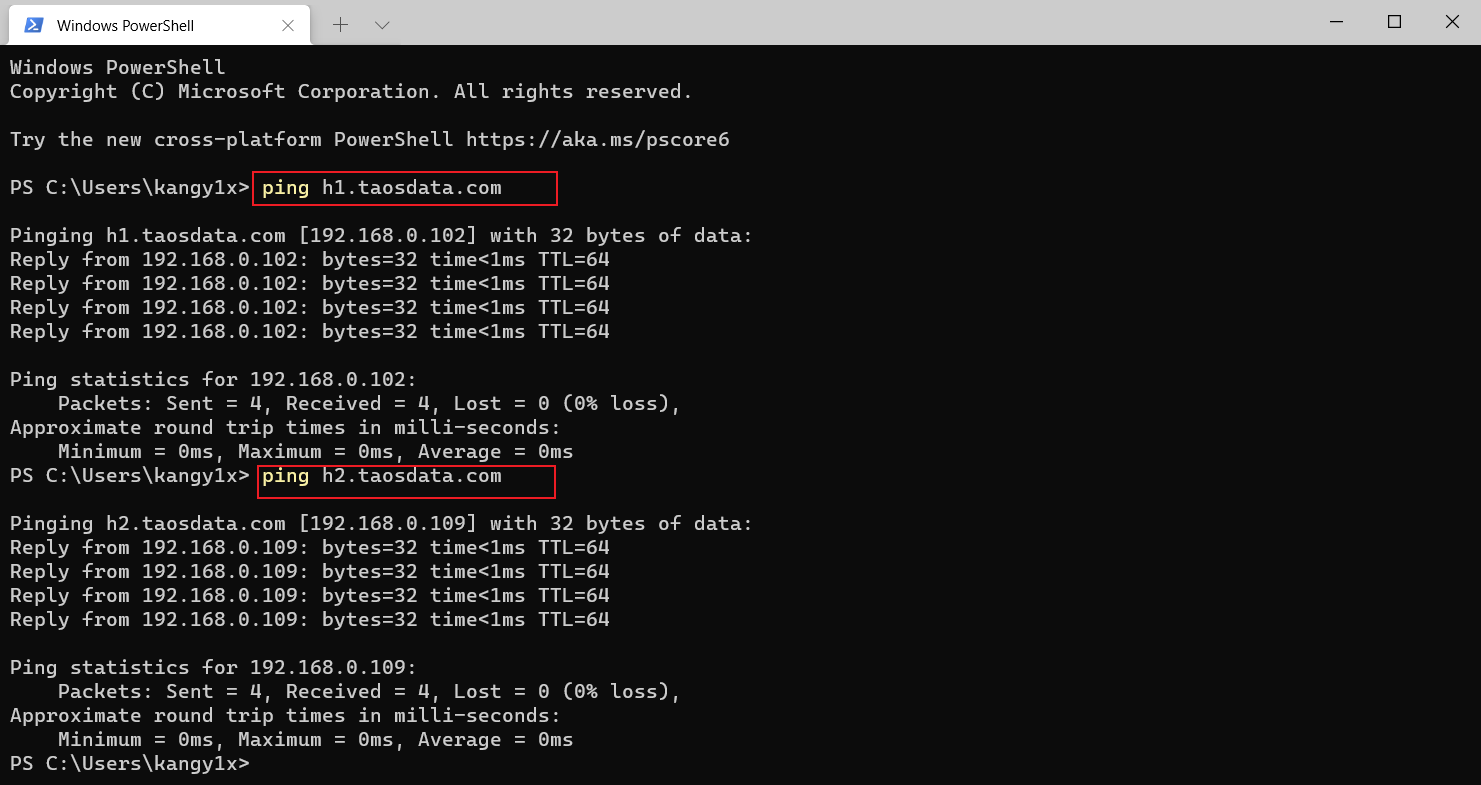
添加h1、h2节点的fqdn解析

配置好以后,在终端ping h1、h2,解析成功
3.安装TDengine和telefgraf
在h1、h2两个节点安装TDengine Server,且版本必须是一致的
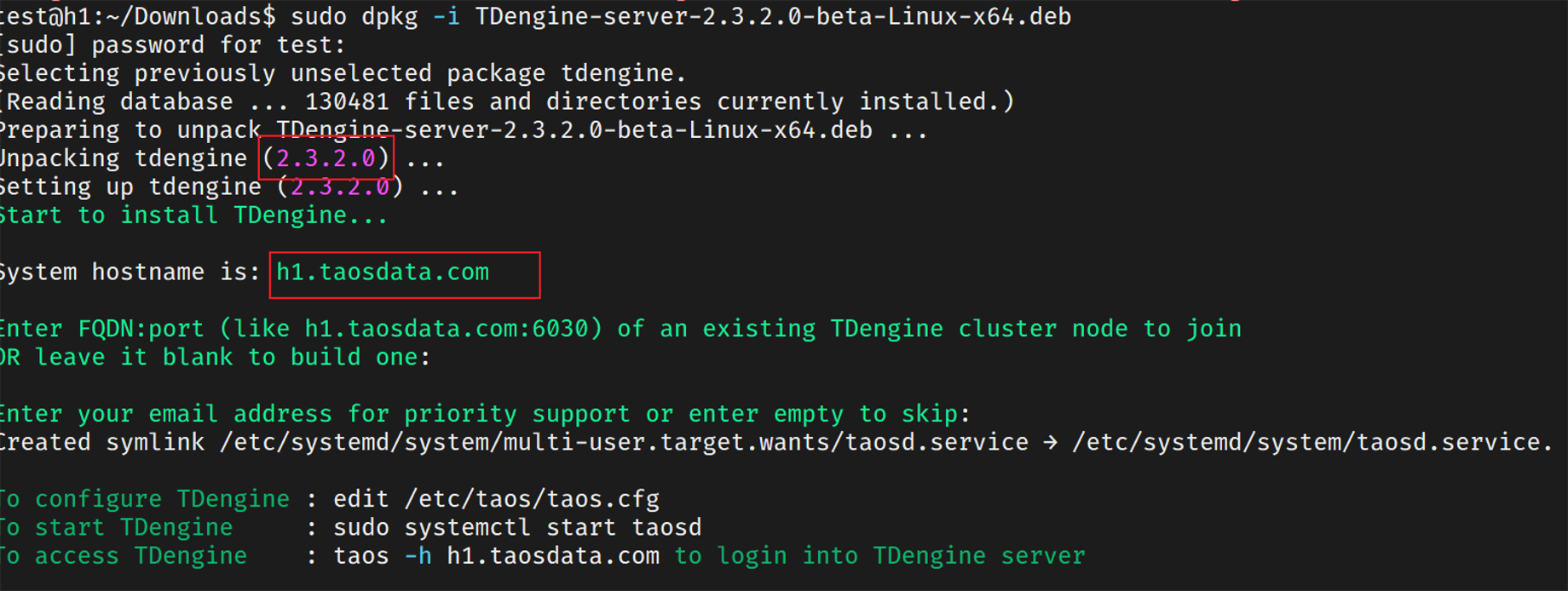
注意安装完成后先不要启动服务
然后安装telegraf并修改/etc/telegraf/telegraf.conf。要注释[[outputs.influxdb]],不然无法写入TDengine
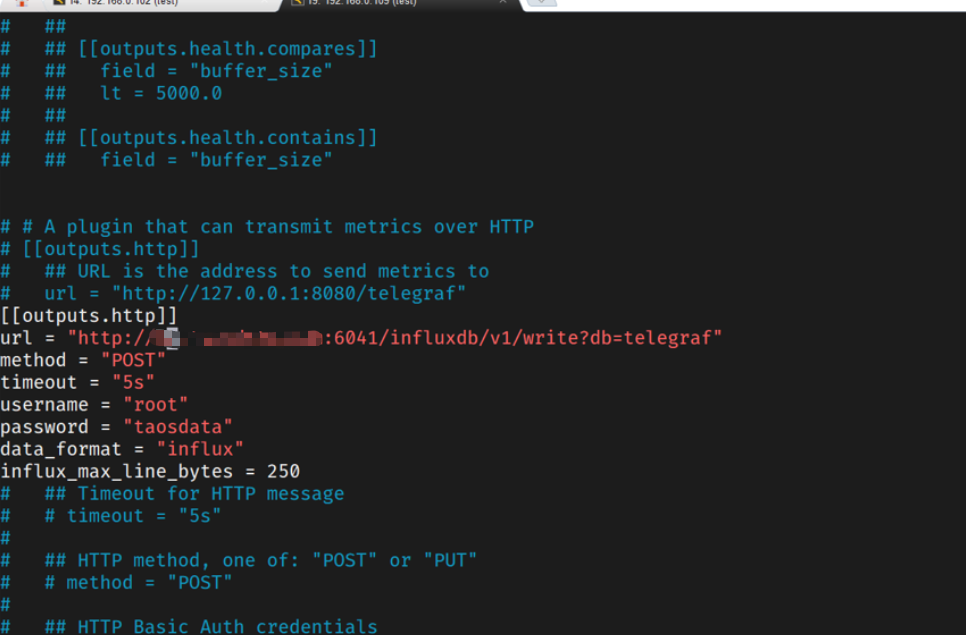
4.TDengine的配置
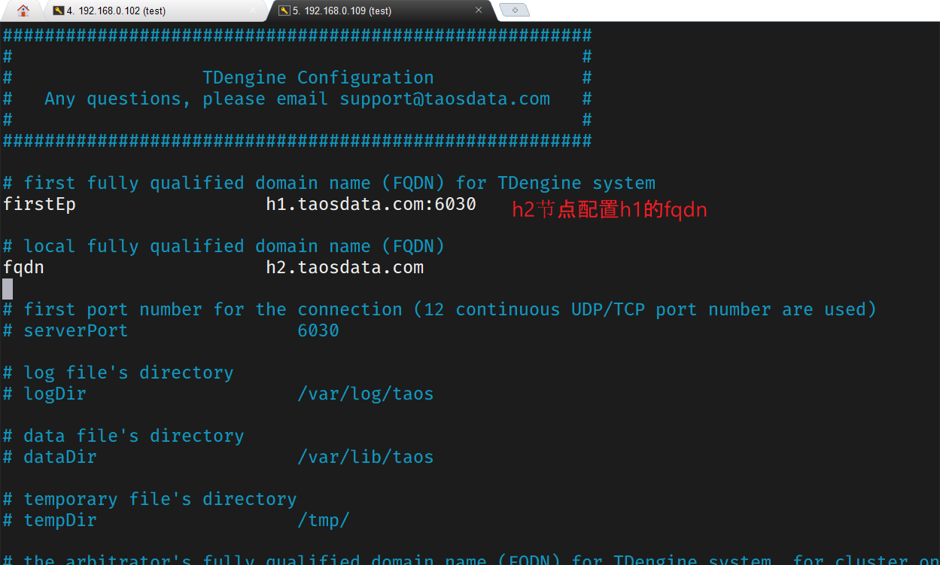
在所有的数据节点,firstEp需全部配置成一样的,但fqdn配置为每个数据节点本地的值。firstEp 是每个数据节点首次启动后连接的第一个数据节点。
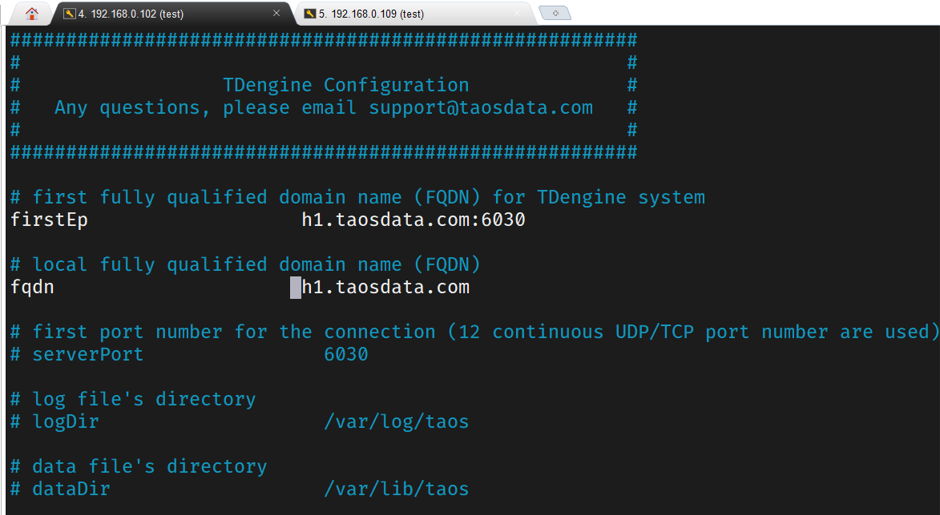
配置h1节点

在taos.cfg中配置h1的参数,这里我们让h1作为第一个启动节点,所以firstEP配置为自己的。
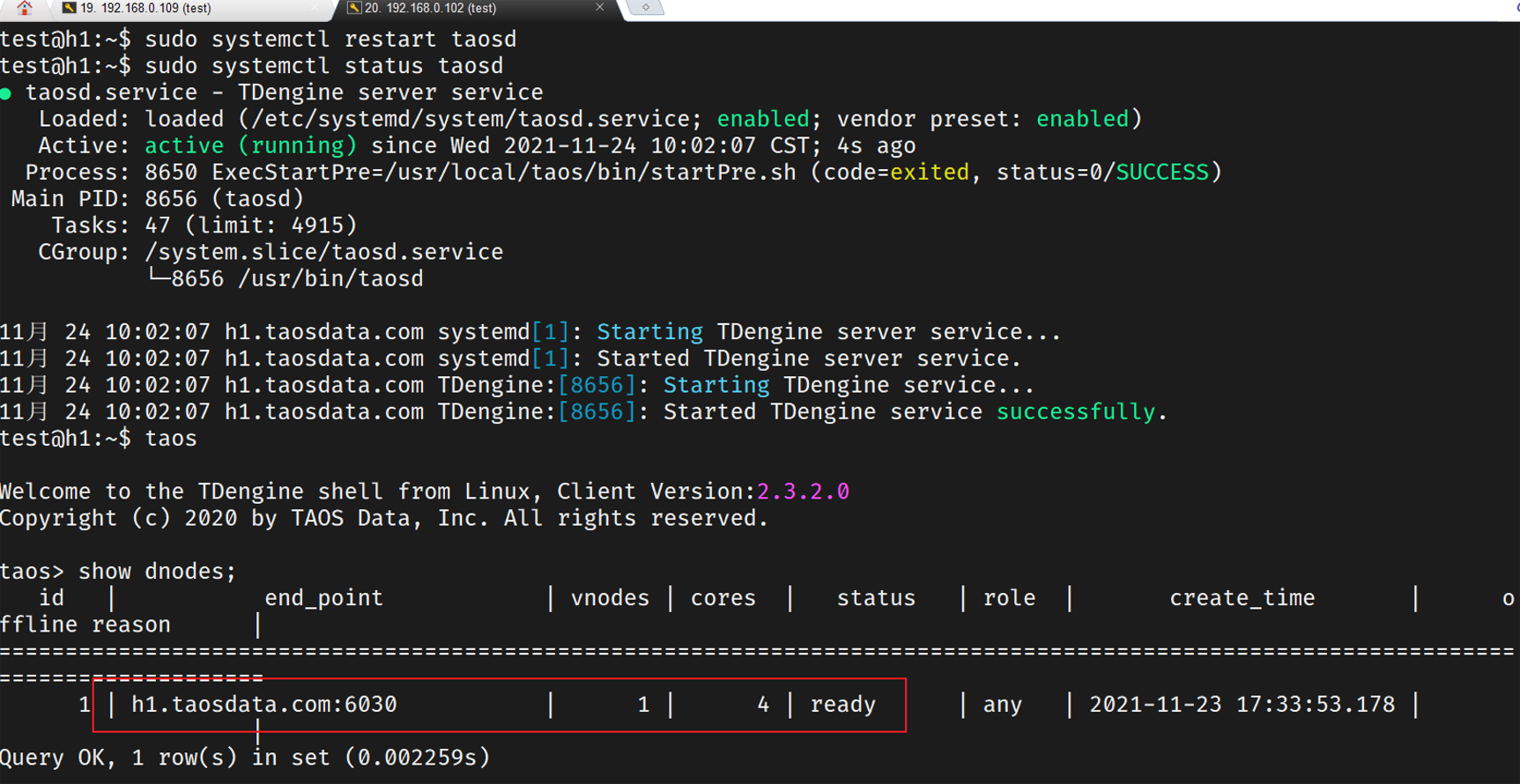
查看节点是否启动
配置h2的参数,firstEP要设置为h1的fqdn
添加后续节点
客户端安装完成TDengine cli后,在安装路径下/cfg目录下,打开taos.cfg文件
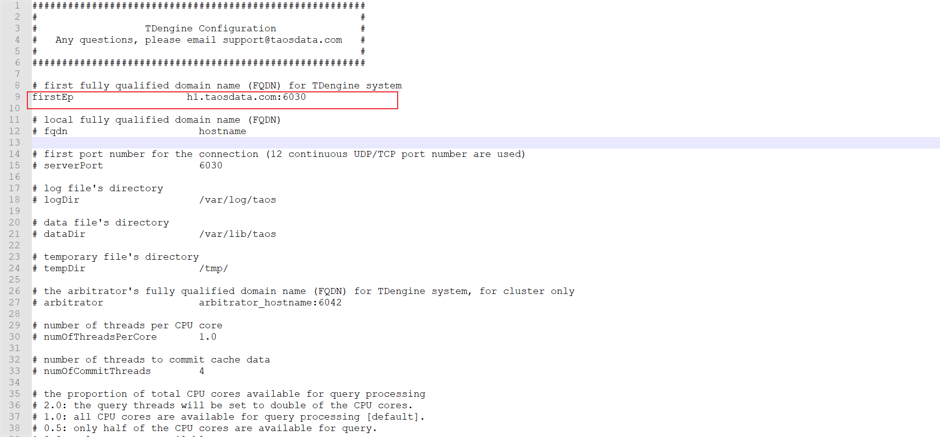
客户端是不需要配置fqdn参数的,只需配置firstEP,设置为h1节点。
配置完成后可以在tdengine cli上ping h1,h2
也使用curl命令访问数据节点比如h1,可以看到有数据返回,说明配置成功。
curl -H "Authorization: Basic cm9vdDp0YW9zZGF0YQ==" -X POST -d "show databases" "http://h1.taosdata.com:6041/rest/sqlutc"

配置完成后如果发现节点的tdengine数据库中没有采集到数据,可以参照文章末尾 Q&A 1 解决办法。
六.集群管理与数据操作
1.登录节点
在TDengine cli登录h1节点

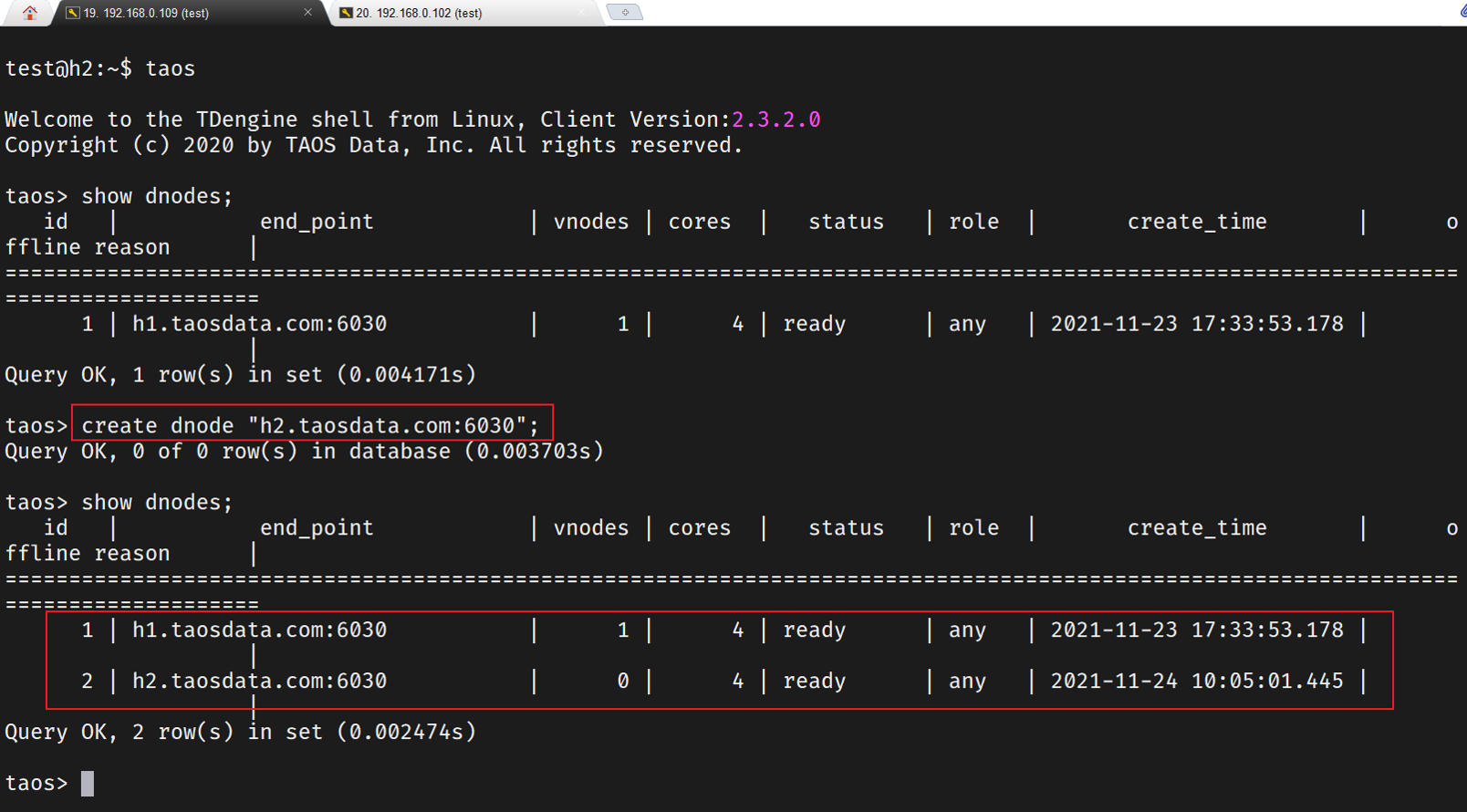
2.查看Mnodes和dnodes

3.添加节点
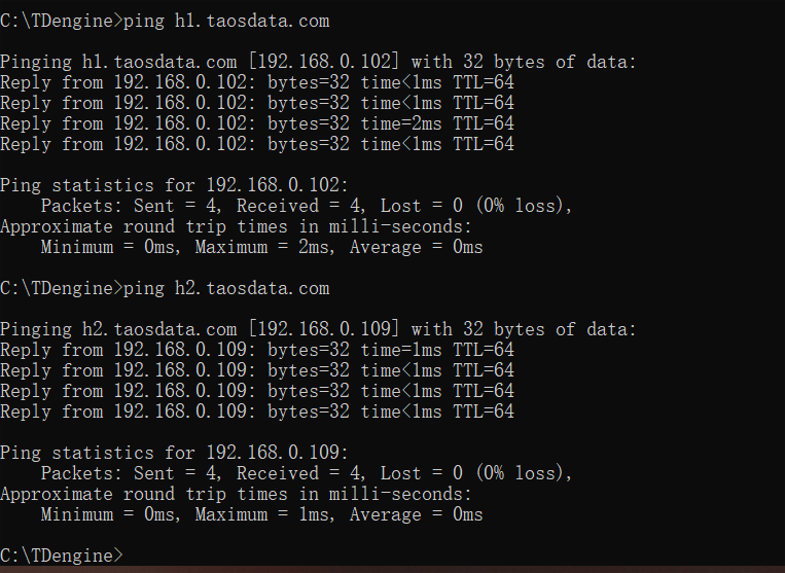
添加h7节点,因为节点没有配置所以状态是offline

4.删除节点
删除h7节点,使用drop [id]。添加和删除节点的过程中生产数据是安全的,应用程序端也是无感的,因为有高可用和负载均衡机制。
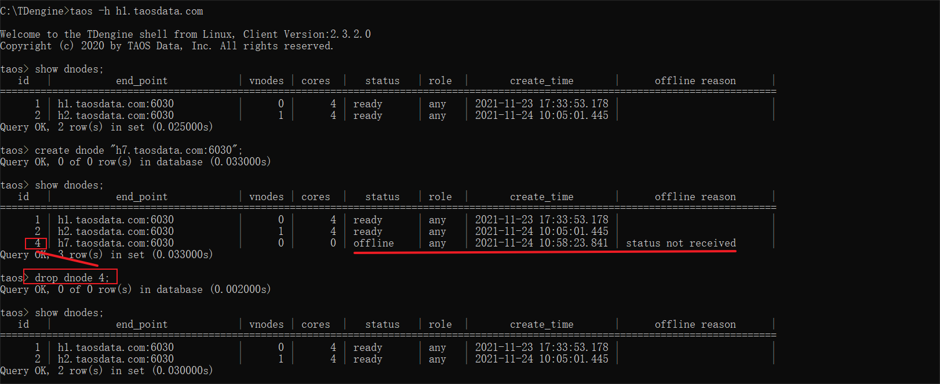
5.查看vgroups
进入数据库才能看到vgroups,否则会报错DB不可用
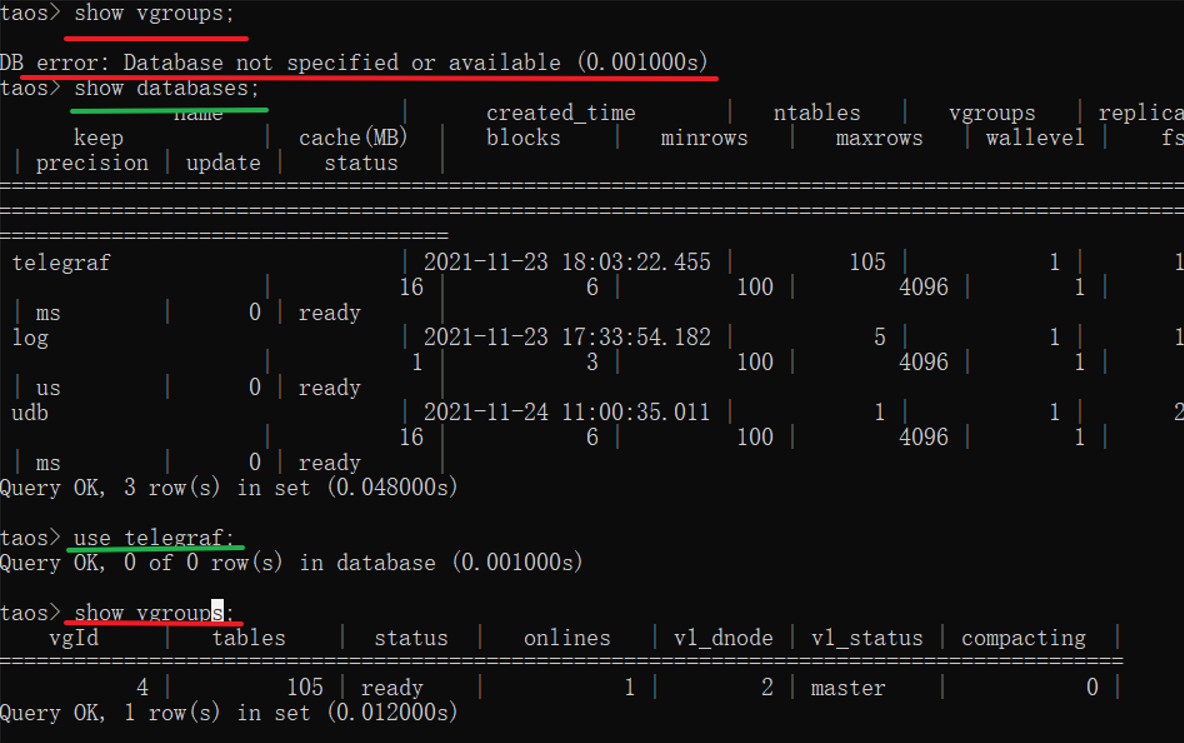
6.修改DB的Vnode副本数
Vnode副本数不能超过节点数,否则会报错。我们有2个节点,所以最多只能创建2个副本。建库时默认指定为1,这里我们修改为2,并查看数据库replice显示为2,修改成功。
7.一些数据操作
建库并指定副本数

建表

表中插入数据
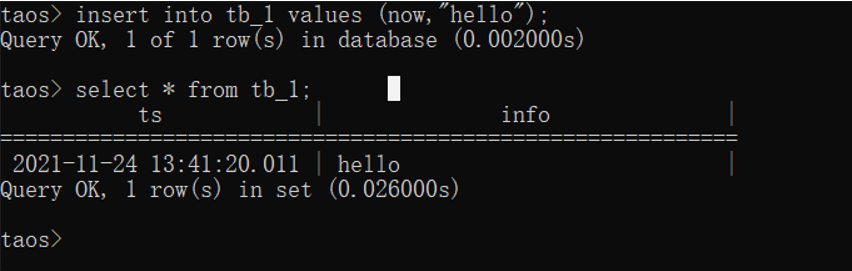
七.配置grafana
1.下载
下载grafana和tdengine-datasource
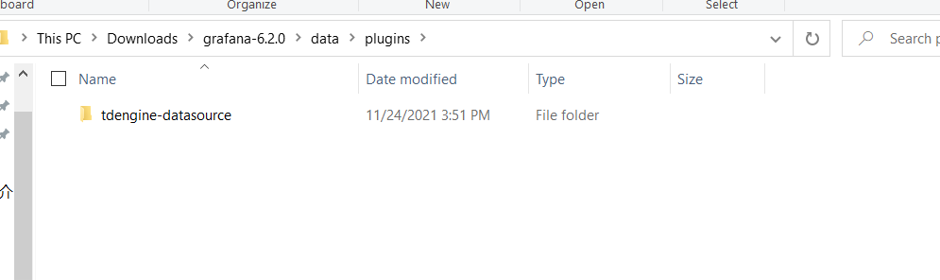
2.添加plugin
配置tdengine-datasource,把下载的插件目录放到以下路径
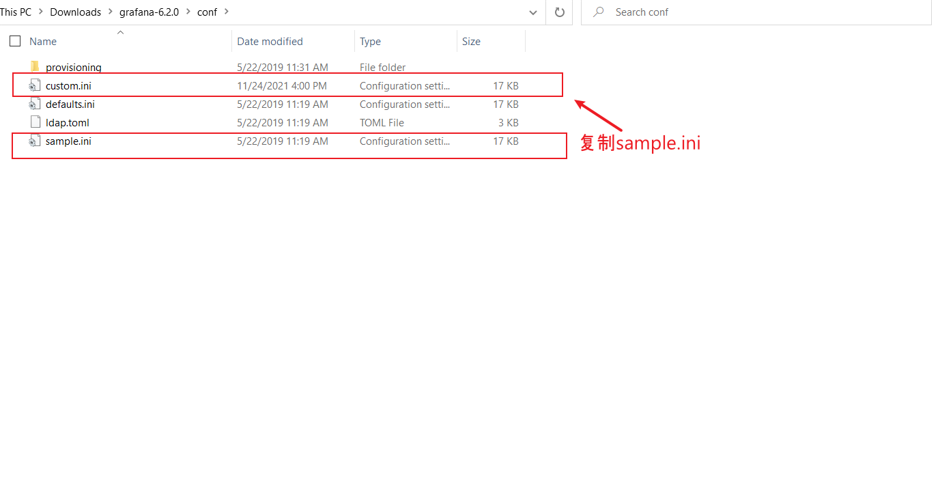
3.修改配置
该路径下复制sample.ini文件,并重命名为custom.ini
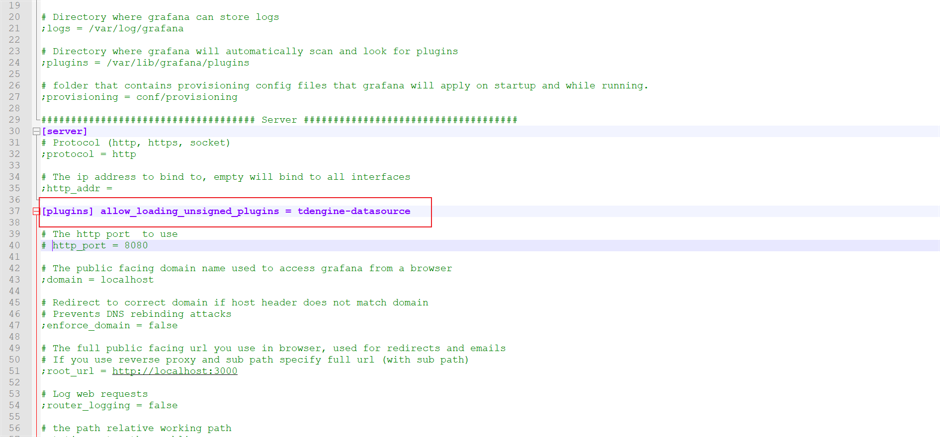
添加配置使之生效
运行grafana服务
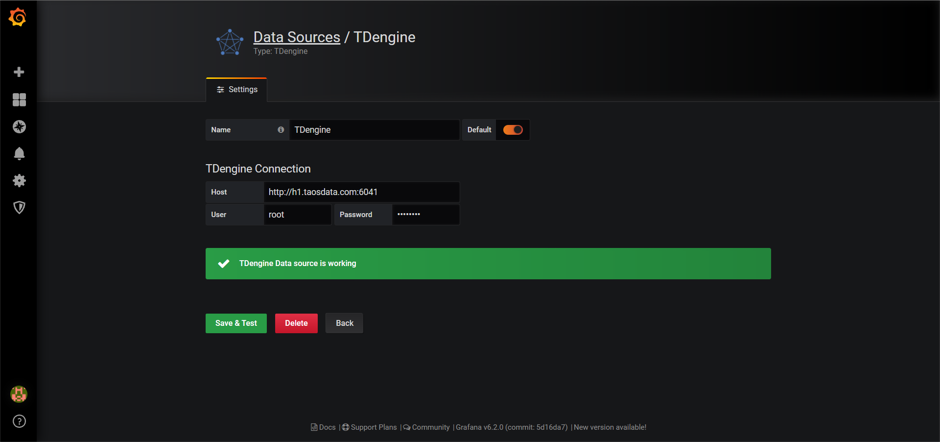
添加TDengine数据库

配置host和相关参数,点击保存
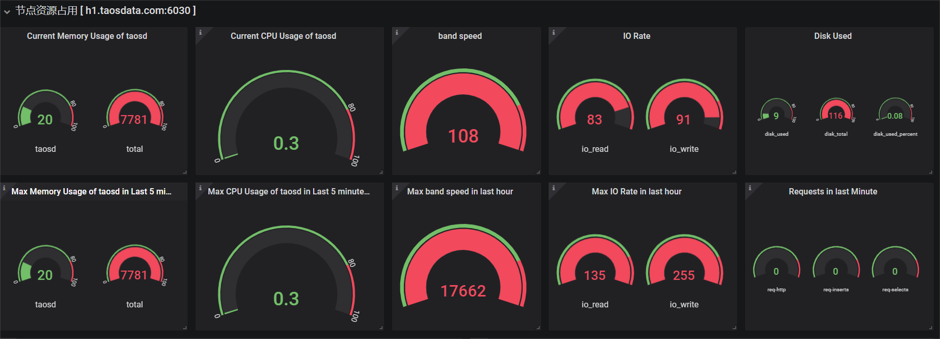
八.在grafana中展示数据
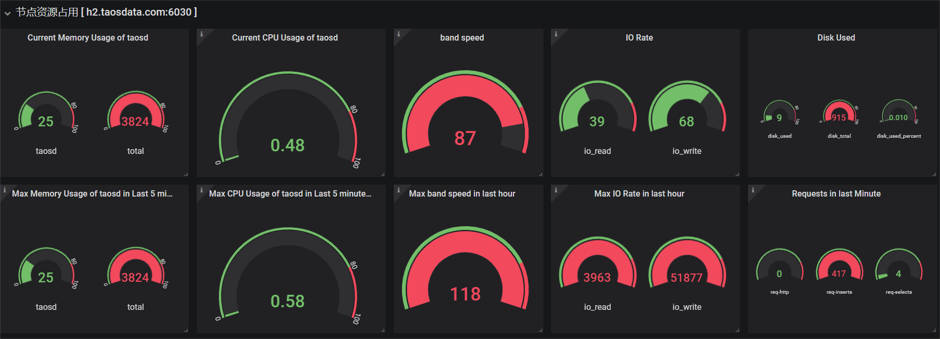
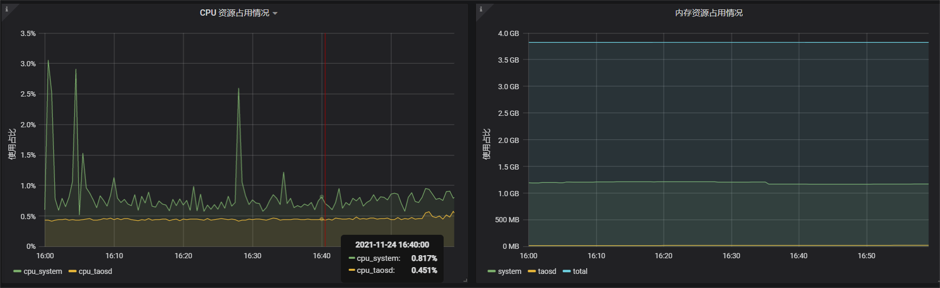
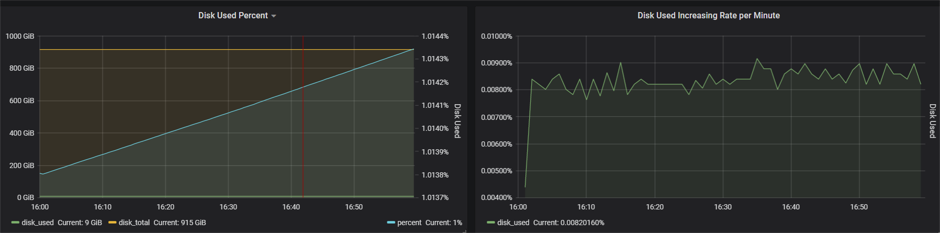
可以在仪表盘中查看两个节点的数据

h1节点的数据展示
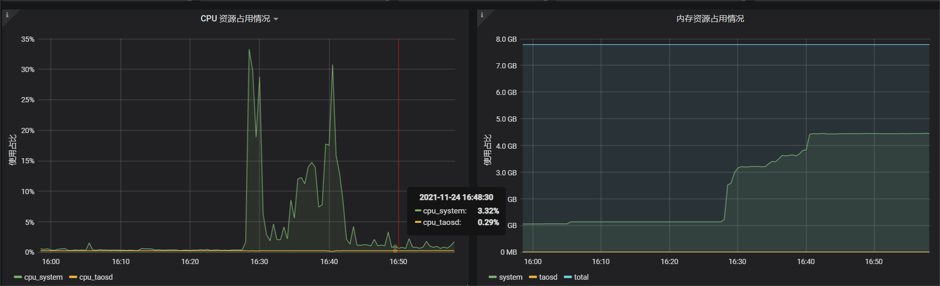
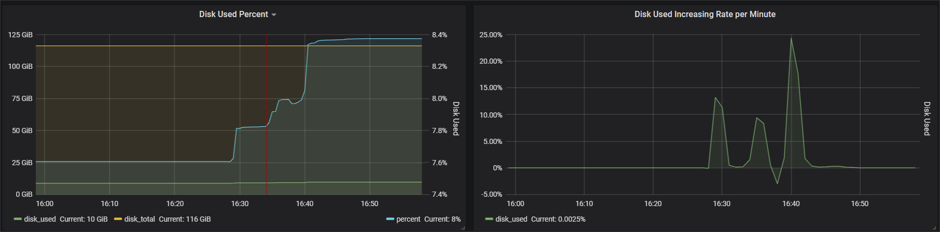
h2节点的数据展示
Q&A
1.集群搭建好以后发现每个节点的数据库都没有采集到数据,怎么解决?
描述
这里我用了最新的TDengine2.3版本,因为它包含一个 BLM3 独立程序,可以直接接收Telegraf 的数据写入。但是搭建完成后却发现每个节点都没有数据写入。
解决过程
查看telegraf启动状态发现,会显示如下报错
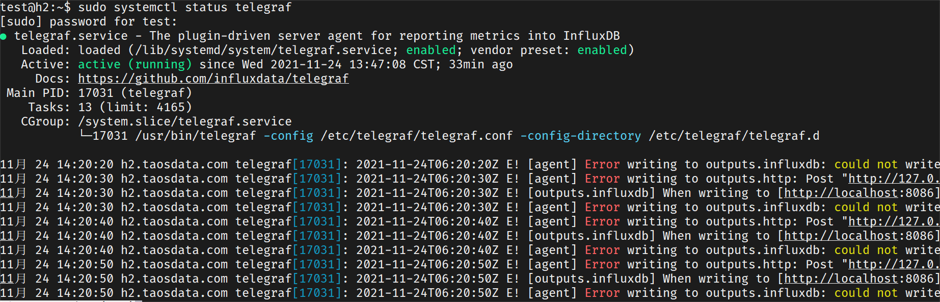
然后查看telegraf.conf,注释掉[[outputs.influxdb]],重启服务还是没有数据写入。由此判定问题可能出在TDengine上。
登录节点,尝试建表插入数据,发现是可以写入的。那么问题是出在哪里呢?
和taos的技术人员交流后一起排查,发现在/var/log/taos目录下并没有生成taosadapter.log,使用sudo systemctl start taosadapter启动adapter服务,报错如下,找不到服务

鉴于是官网下载的版本安装的,并非自己编译的,技术人员说说tdengine启动的时候adapter会随之启动,可能是一个BUG他们会尽快修复的。然后发给我一个补丁文件,见下图。
这个补丁文件的使用方法是这样的,放到/etc/init.d和/etc/systemd/system目录下,然后chmod 754加权限,然后重启服务器,即可看到服务已经启动
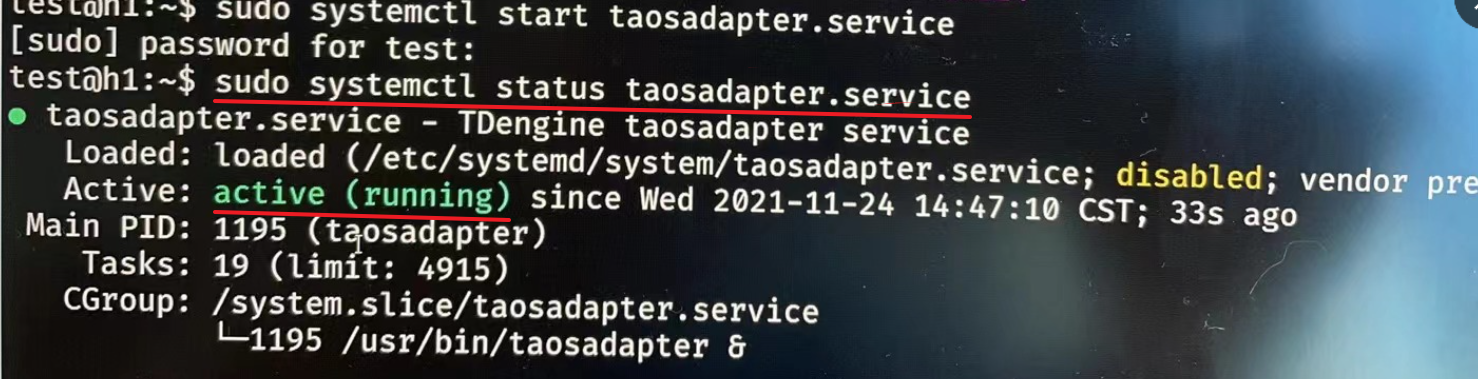
然后我们查看数据库,发现数据已经采集到tdengine了,问题解决了!!