一.常用数据集
1.Kaggle
https://www.kaggle.com/detasets
特点:
- 大数据竞赛平台
- 80万科学家
- 真实数据
- 数据量巨大
2.UCI
特点:
- 1.收录了360个数据集
- 2.覆盖科学、生活、经济等领域
- 3.数据量几十万
3.scikit-learn
https://scikit-learn.org/stable/
特点:
- 数据量小
- 方便学习
二.scikit-learn数据集API介绍
sklearn.datasets
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datatets.fetch_*(data_home=None)
- 获取大规模数据集,从网络下载,函数的第一个参数是data.home,表示数据集下载的目录,默认是
~/scikit_learn_data目录,见下图
- 获取大规模数据集,从网络下载,函数的第一个参数是data.home,表示数据集下载的目录,默认是
示例代码:
from sklearn.datasets import load_iris, fetch_20newsgroups
# 1. 数据集的获取
# 1.1 小数据集获取
# iris花的数据,包括花瓣长宽和花萼长宽、目标值有三个类型(0,1,2)、目标值的名字以及描述
iris = load_iris()
# print(iris)
# 1.2 大数据集的获取
# 获取20类新闻文本
news = fetch_20newsgroups()
# print(news)
三.sklearn数据集返回值介绍
返回值类型是bunch–是一个字典类型
# 2.数据集属性描述
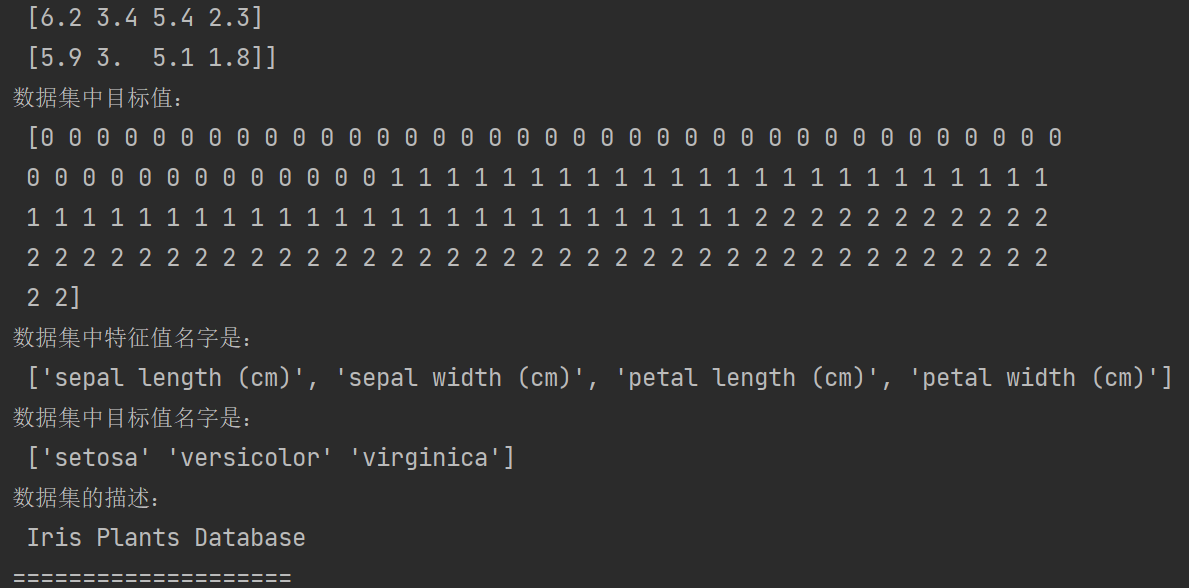
print("数据集特征值是:\n", iris.data)
print("数据集中目标值:\n", iris["target"])
print("数据集中特征值名字是:\n", iris.feature_names)
print("数据集中目标值名字是:\n", iris.target_names)
print("数据集的描述:\n", iris.DESCR)
结果如下:
四.数据可视化
from sklearn.datasets import load_iris, fetch_20newsgroups
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# iris花的数据,包括花瓣长宽和花萼长宽、目标值有三个类型(0,1,2)、目标值的名字以及描述
iris = load_iris()
# 3.数据可视化
# 3.1 数据类型转换,把数据用DataFrame存储
iris_data = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
# 添加目标值
iris_data["target"] = iris.target
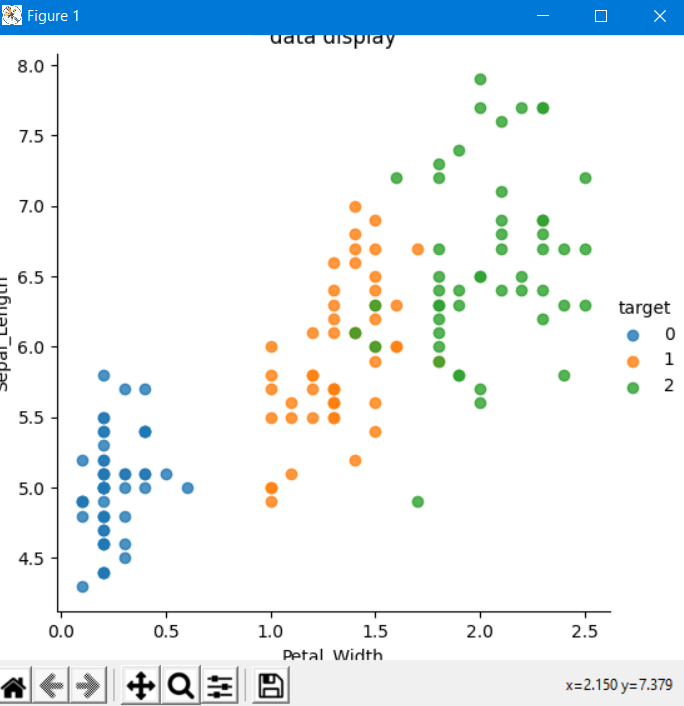
def plot_iris(data, col1, col2):
# x,y --具体x轴,y轴数据的索引值
# data -- 具体数据
# hue -- 目标值
# fit_reg -- 是否进行线性拟合
sns.lmplot(x=col1, y=col2, data=data, hue="target", fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('data display')
plt.show()
plot_iris(iris_data, "Petal_Width", 'Sepal_Length')
运行结果如下:
五.数据集的划分
1.机器学习中一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 75% 80%
- 测试集:30% 25% 20%
2.数据集划分api
sklearn.model_selection.train_test_split(arrays,*options)
x 数据集的特征值
y 数据集的目标值(标签值)
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 训练集特征值,测试集特征值,训练集目标值(也称标签),测试集目标值。
示例代码如下:
from sklearn.datasets import load_iris, fetch_20newsgroups
from sklearn.model_selection import train_test_split
iris = load_iris()
# 特征值 x_train, x_test
# 目标值 y_train, y_test
# 测试数据集占比 test_size
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=2)
# print("训练集的特征值:\n", x_train)
# print("测试集的特征值:\n", x_test)
# print("训练集的目标值:\n", y_train)
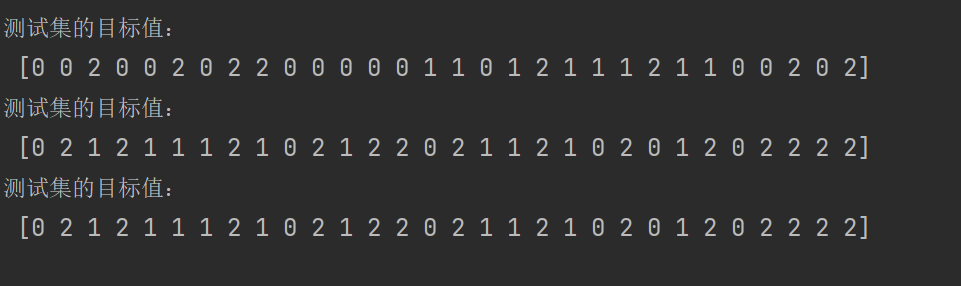
print("测试集的目标值:\n", y_test)
# print("训练集的目标值形状:\n", x_train.shape)
# print("测试集的目标值形状:\n", x_test.shape)
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("测试集的目标值:\n", y_test1)
print("测试集的目标值:\n", y_test2)
运行结果如下,通过对比三个random_state,我们发现后边两个的值相等,但是和第一个不一样,这是因为随机数种子的取值不同。