
一.特征提取介绍
1.什么是特征提取?
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
2.特征提取分类:
-
字典特征提取(特征离散化)
-
文本特征提取
-
图像特征提取
3.特征提取API
sklearn.feature_extraction
二.字典特征介绍与应用
1.API介绍
作用:对字典数据进行特征值化
sparse矩阵有两个好处:1.节省内存 2.提高读取效率
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
DictVectorizer.fit_transform(X)
# X:字典或者包含字典的迭代器返回值
# 返回sparse矩阵
DictVectorizer.get_feature_names() # 返回类别名称
2.应用
代码演示:
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
data = [{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
# 1.实例化
transfer = DictVectorizer(sparse=False)
# 2.调用fit_transform
trans_data = transfer.fit_transform(data)
print(trans_data)
# 打印特征名称
print("特征名称", transfer.get_feature_names())
if __name__ == '__main__':
dict_demo()
不加sparse=False的结果:
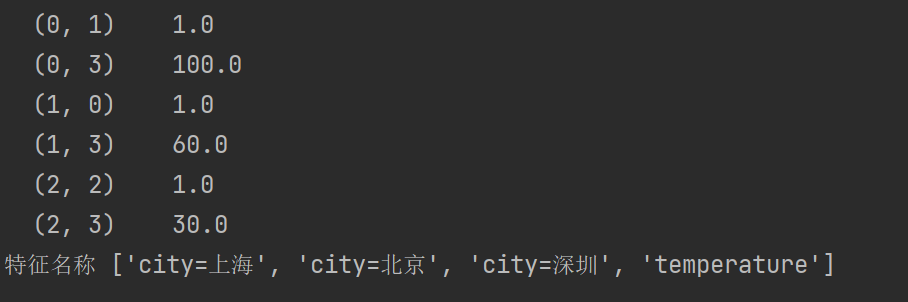
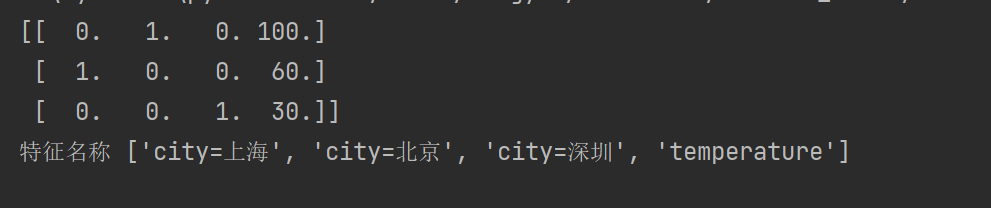
加sparse=False结果如下,我们把这个处理数据的技巧叫做one-hot编码。对于特征当中存在类别信息的我们都会做one-hot编码处理。
三.文本特征提取
1.API介绍
作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
# 返回词频矩阵
CountVectorizer.fit_transform(X)
# X:文本或者包含文本字符串的可迭代对象
# 返回值:返回sparse矩阵
CountVectorizer.get_feature_names() #返回值:单词列表
sklearn.feature_extraction.text.TfidfVectorizer
2.应用
from sklearn.feature_extraction.text import CountVectorizer
def count_text_demo():
data = ["the day is expensive ,i like tee",
"the day is cheap,i dislike caffee"]
# 实例化 没有sparse这个参数
# stop_words=["caffee"] 停用词 结果中去掉了"caffee"
# 单个字母和标点符号不做统计
transfer = CountVectorizer(stop_words=["caffee"])
# 调用fit_transform
trans_data = transfer.fit_transform(data)
print(transfer.get_feature_names())
print(trans_data.toarray())
if __name__ == '__main__':
count_text_demo()
结果如下:

四.Tf-idf文本特征提取
1.TF-IDF方法介绍
TF-IDF主要思想是 :
如果某个词或短语在一篇文章中出现的概率高,并在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用 :
用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
| tf(term frequency): 词频 | 某一个给定的词语在该文件中出现的频率 |
| idf(inverse document frequency): 逆向文档频率 | lg(总文档数量/该词出现的文档数量) |
idf:由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
tf * idf :最终得出结果可以理解为重要程度
2.应用
代码实现:
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutword():
con1 = jieba.cut("在模型优化器中添加对自定义操作的支持,以便模型优化器可以通过操作生成 IR")
con2 = jieba.cut("创建一个操作集,并且在描述它实现自定义nGraph操作自定义nGraph操作")
# 转换成列表
contest1 = list(con1)
contest2 = list(con2)
# 转换成字符串
c1 = ' '.join(contest1)
c2 = ' '.join(contest2)
print(c1, c2)
return c1,c2
def tfidfvec():
c1, c2 = cutword()
tf = TfidfVectorizer()
data = tf.fit_transform([c1, c2])
# 统计所有句子中的所有的词,重复的词只算一次,单个字母不统计 [词的列表]
print(tf.get_feature_names())
print(data.toarray())
return None
if __name__ == "__main__":
tfidfvec()
结果:

3.Tf-idf的重要性
分类机器学习算法进行文章分类中前期数据处理方式