1.seaborn介绍
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
2.seaborn特点
其有如下特点:
- 基于matplotlib aesthetics绘图风格,增加了一些绘图模式
- 增加调色板功能,利用色彩丰富的图像揭示您数据中的模式
- 运用数据子集绘制与比较单变量和双变量分布的功能
- 运用聚类算法可视化矩阵数据
- 灵活运用处理时间序列数据
- 利用网格建立复杂图像集
3.安装与导入
# 安装
pip install seaborn
# 导入
import seaborn as sns
4.可视化数据的分布
当处理一组数据时,通常先要做的是了解变量是如何分布的。
- 1.对于单变量的数据来说,采用直方图核密度图曲线是个不错的选择。
- 2.对于双变量的数据来说,采用多面板图形展现,比如散点图、二维直方图、核密度估计图等
5.绘制单变量分布
可以采用最简单的直方图描述单变量的分布情况。 Seaborn中提供了 distplot()函数, 它默认绘制的是一个带有核密度估计曲线的直方图。 distplot()函数的语法格式如下。
seaborn.distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None, color=None)
上述函数中常用参数的含义如下:
(1) a: 表示要观察的数据, 可以是 Series、 一维数组或列表。
(2) bins: 用于控制条形的数量。
(3) hist: 接收布尔类型, 表示是否绘制(标注)直方图。
(4) kde: 接收布尔类型, 表示是否绘制高斯核密度估计曲线。
(5) rug: 接收布尔类型, 表示是否在支持的轴方向上绘制rugplot。
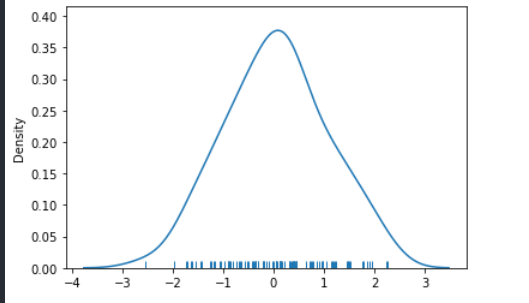
通过 distplot())函数绘制直方图的示例如下。
import numpy as np
import seaborn as sns
sns.set()
np.random.seed(0) # 确定随机数生成器的种子,如果不使用每次生成图形不一样
arr = np.random.randn(100) # 生成随机数组
ax = sns.distplot(arr, bins=10, hist=True, kde=True, rug=True) # 绘制直方图
运行结果如下图所示
6.绘制双变量分布
两个变量的二元分布可视化也很有用。在 Seaborn中最简单的方法是使用 jointplot()函数,该函数可以创建一个多面板图形,比如散点图、二维直方图、核密度估计等,以显示两个变量之间的双变量关系及每个变量在单坐标轴上的单变量分布。
jointplot()函数的语法格式如下。
seaborn.jointplot(x, y, data=None,
kind='scatter', stat_func=None, color=None,
ratio=5, space=0.2, dropna=True)
上述函数中常用参数的含义如下:
(1) kind: 表示绘制图形的类型。
(2) stat_func: 用于计算有关关系的统计量并标注图。
(3) color: 表示绘图元素的颜色。
(4) size: 用于设置图的大小(正方形)。
(5) ratio: 表示中心图与侧边图的比例。 该参数的值越大, 则中心图的占比会越大。
(6) space: 用于设置中心图与侧边图的间隔大小
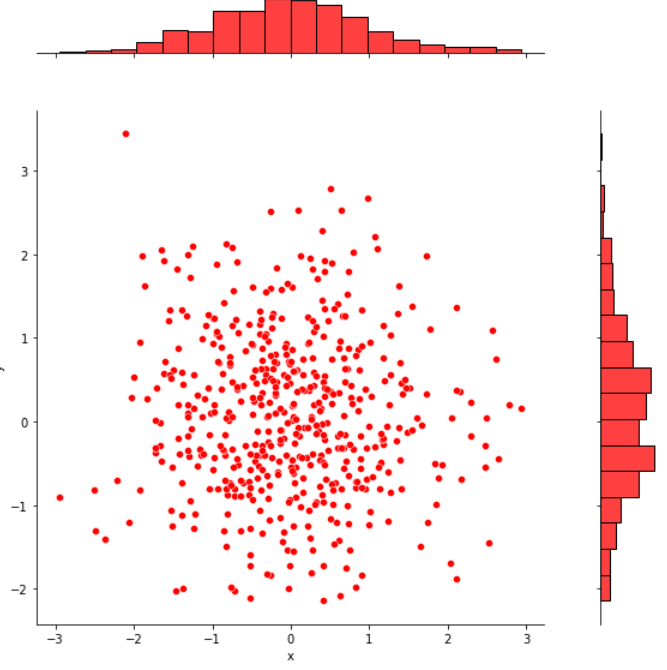
6.1 绘制散点图
import numpy as np
import pandas as pd
import seaborn as sns
# 创建DataFrame对象
dataframe_obj = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot(x="x",y="y",data=dataframe_obj,kind="scatter",color="r",size=8,ratio=5,space=1)
上边的代码首先创建了一个 DataFrame对象 dataframe_obj作为散点图的数据, 其中x轴和y轴的数据均为500个随机数, 接着调用 jointplot0 函数绘制一个散点图, 散点图x轴的名称为“x”, y轴的名称为“y”。
运行结果如下:
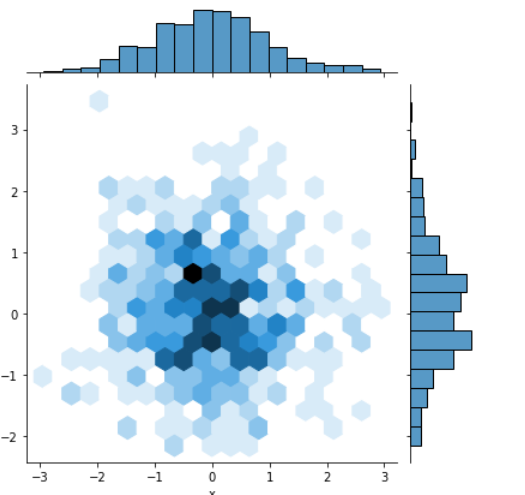
6.2 绘制二维直方图
二维直方图类似于“六边形”图, 主要是因为它显示了落在六角形区域内的观察值的计数, 适用于较大的数据集。 当调用 jointplot()函数时, 只 要传入kind=”hex”, 就可以绘制二维直方图, 具体示例代码如下。
import numpy as np
import pandas as pd
import seaborn as sns
# 创建DataFrame对象
dataframe_obj = pd.DataFrame({"x":np.random.randn(500),"y":np.random.randn(500)})
sns.jointplot("x","y",data=dataframe_obj,kind="hex")
注意 –
从六边形颜色的深浅,可以观察到数据密集的程度,另外,图形的上方和右侧仍然给出了直方图。在绘制二维直方图时, 最好使用白色 背景。
结果如下图:
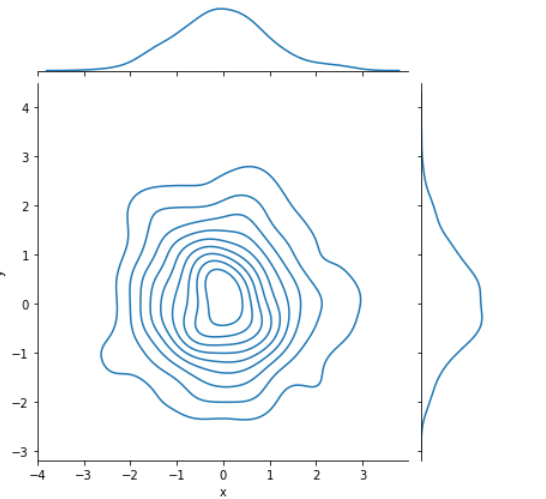
6.3 绘制核密度估计图形
利用核密度估计同样可以查看二元分布, 其用等高线图来表示。 当调用jointplot()函数时只要传入ind=”kde”, 就可以绘制核密度估计图形, 具体 示例代码如下。
sns.jointplot(x="x", y="y", data=dataframe_obj, kind="kde")
上述示例中,绘制了核密度的等高线图,另外,在图形的上方和右侧给出了核密度曲线图
结果如下图:
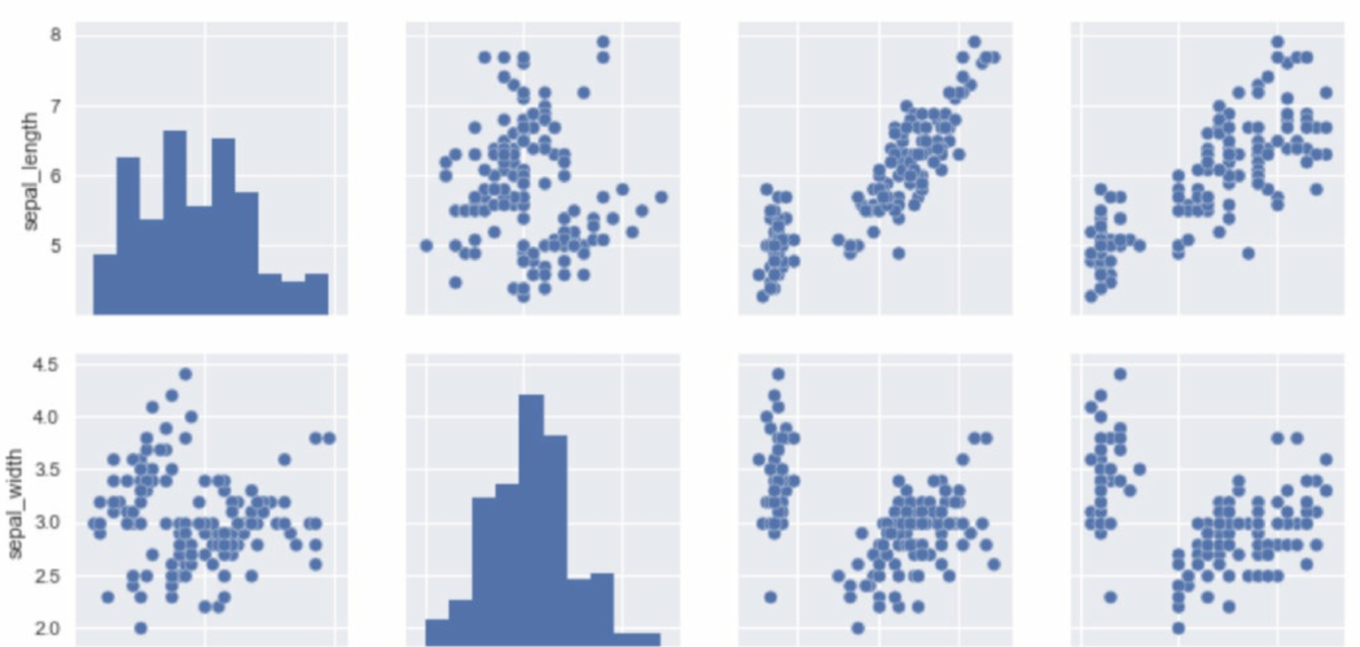
6.4 绘制成对的双变量分布
要想在数据集中绘制多个成对的双变量分布,则可以使用pairplot()函数实现,该函数会创建一个坐标轴矩阵,并且显示Datafram对象中每对变 量的关系。另外,pairplot()函数也可以绘制每个变量在对角轴上的单变量分布。
import seaborn as sns
# 加载seaborn中的数据集
dataset = sns.load_dataset("iris")
dataset.head()
# 绘制多个成对的双变量分布
sns.pairplot(dataset)
结果如下图
7.用分类数据绘图
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类别型的数据了,比如人的性别、学历、爱好等,这些数据类型都不能用连续的变量来表示, 而是用分类的数据来表示。
Seaborn针对分类数据提供了专门的可视化函数, 这些函数大致可以分为如下三种:
-
分类数据散点图: swarmplot()与 stripplot()。
-
类数据的分布图: boxplot() 与 violinplot()。
-
分类数据的统计估算图:barplot() 与 pointplot()。
7.1 类别散点图
通过 stripplot()函数可以画一个散点图, stripplot0函数的语法格式如下。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)
上述函数中常用参数的含义如下
(1) x, y, hue: 用于绘制长格式数据的输入。
(2) data: 用于绘制的数据集。 如果x和y不存在, 则它将作为宽格式, 否则将作为长格式。
(3) jitter: 表示抖动的程度(仅沿类別轴)。 当很多数据点重叠时, 可以指定抖动的数量或者设为Tue使用默认值。
import seaborn as sns
data = sns.load_dataset("tips")
data.head()
sns.stripplot(x="day",y="total_bill",data=data,jitter=False)
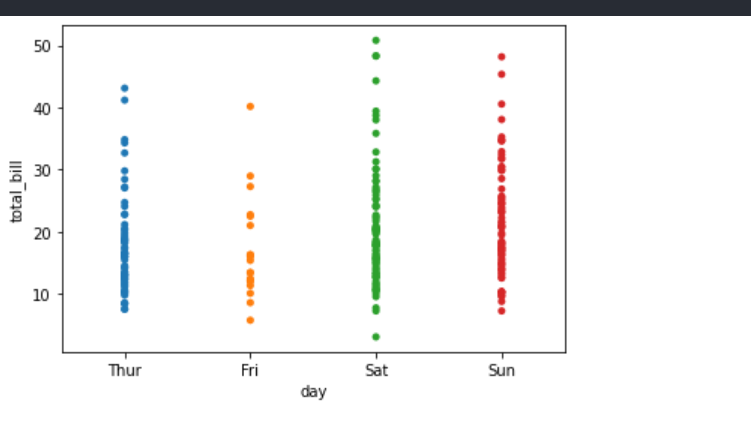
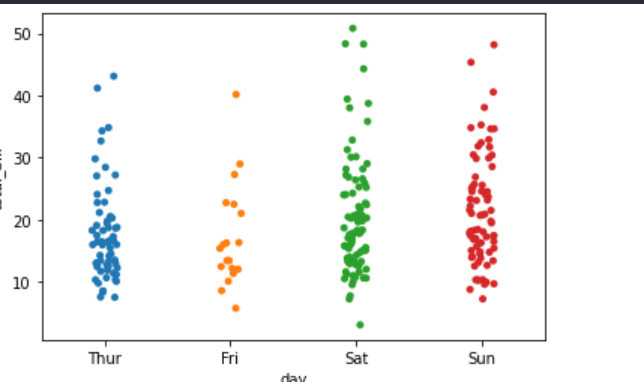
由上图可知,图表中的横坐标是分类的数据,而且一些数据点会互相重叠,不易于观察。我们可以设置jitter=True, 以调整横坐标的位置。
sns.stripplot(x="day",y="total_bill",data=data,jitter=True)
加入标签值,可以看到Thre和Fri两列中有hue的值混入。
sns.stripplot(x="day",y="total_bill",data=data,jitter=True,hue="time")
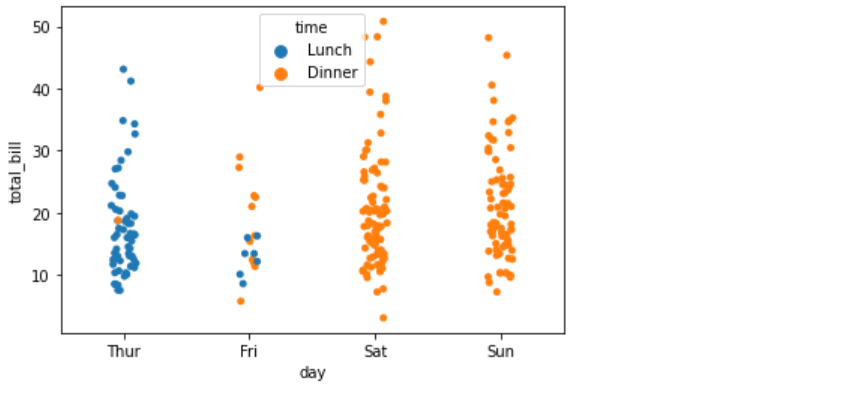
swarmplot函数绘制散点图,该函数的好处是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况:
sns.swarmplot("day","total_bill",data=data)
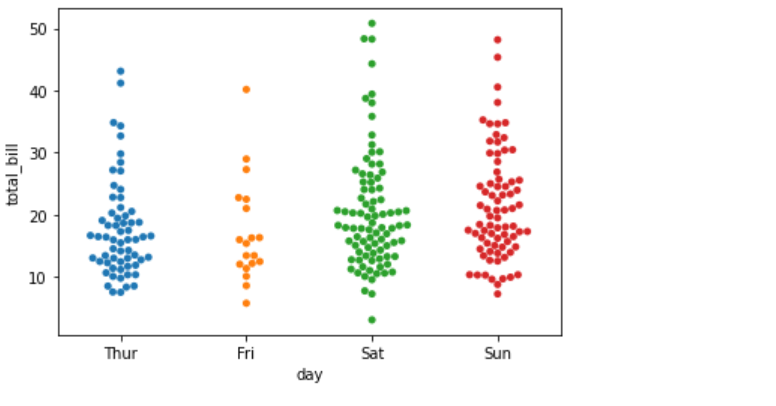
7.2 类别内的数据分布
要想查看各个分类中的数据分布,显而易见,散点图是不满足需求的原因是它不够直观。针对这种情况,我们可以绘制如下两种图形进行查看。
7.2.1箱形图
它能显示出一组数据的最大值、最小值、中位数、及上下四分 位数。
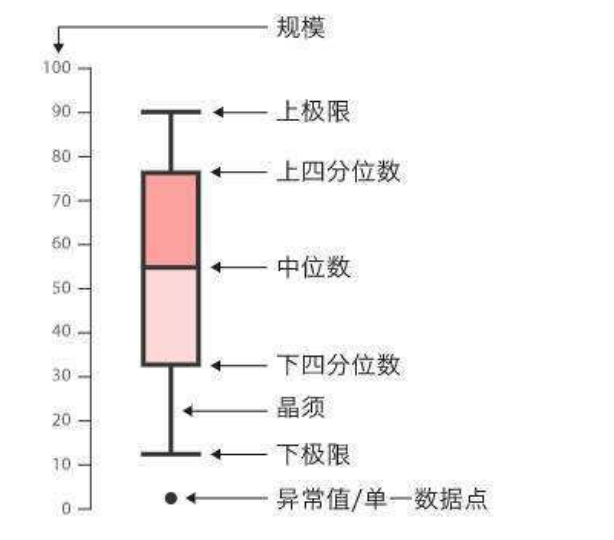
seaborn中用于绘制箱形图的函数为 boxplot(), 其语法格式如下:
seaborn.boxplot(x=None, y=None, hue=None, data=None, orient=None, color=None, saturation=0.75, width=0.8)
常用参数的含义如下:
(1) palette:用于设置不同级别色相的颜色变量。 —- palette=[“r”,”g”,”b”,”y”]
(2) saturation:用于设置数据显示的颜色饱和度。 —- 使用小数表示
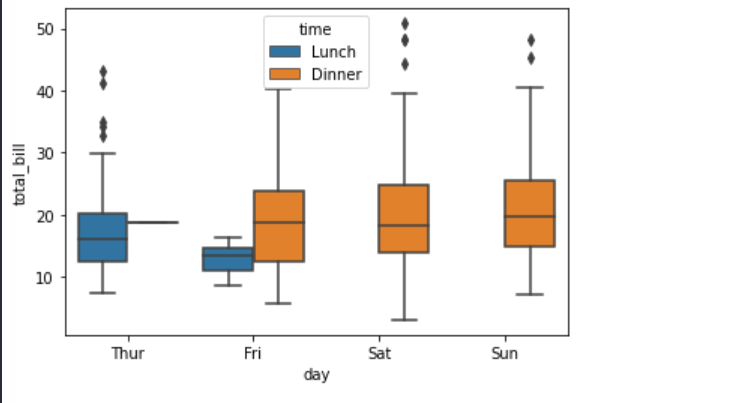
使用 boxplot()函数绘制箱形图的具体示例如下。
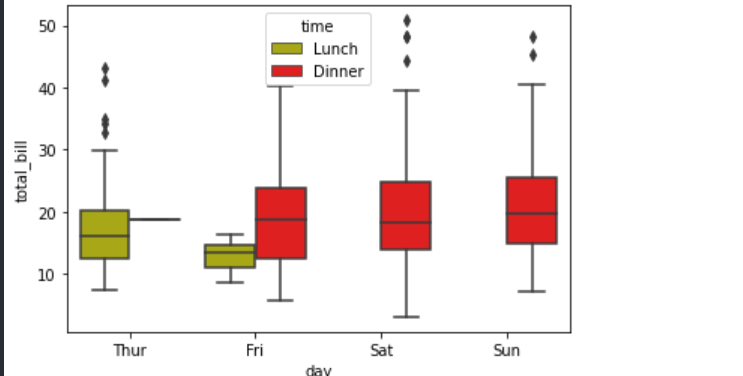
sns.boxplot("day","total_bill",data=data,hue="time")
使用palette替换颜色
sns.boxplot("day","total_bill",data=data,hue="time",palette=["y","r"])
7.2.2 小提琴图
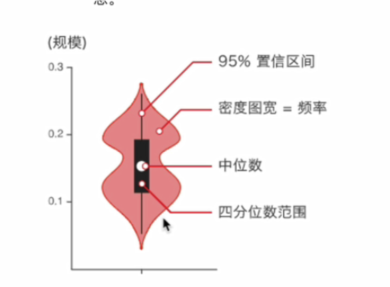
小提琴图 (Violin Plot) 用于显示数据分布及其概率密度。
这种图表结合了箱形图和密度图的特征,主要用来显示数据的分布形状。
中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表95%置信区间,而白点则为中位数。
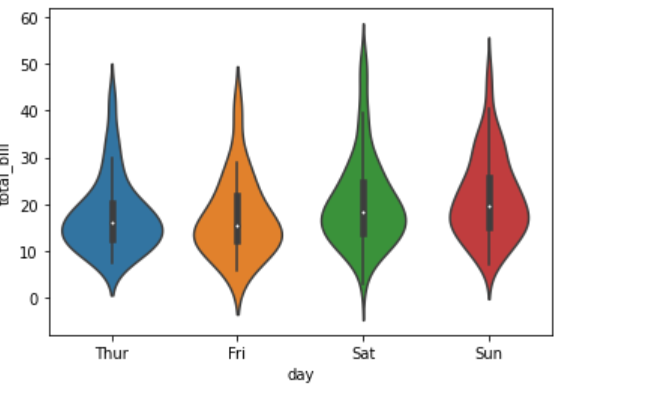
seaborn中用于绘制提琴图的函数为violinplot(), 其语法格式如下
seaborn.violinplot(x=None, y=None, hue=None, data=None)
示例演示
sns.violinplot("day","total_bill",data=data)
7.3 类别内的统计分布
要想查看每个分类的集中趋势,则可以使用条形图和点图进行展示。Seaborn库中用于绘制这两种图表的具体函数如下
-
barplot()函数: 绘制条形图
-
pointplot()函数: 绘制点图
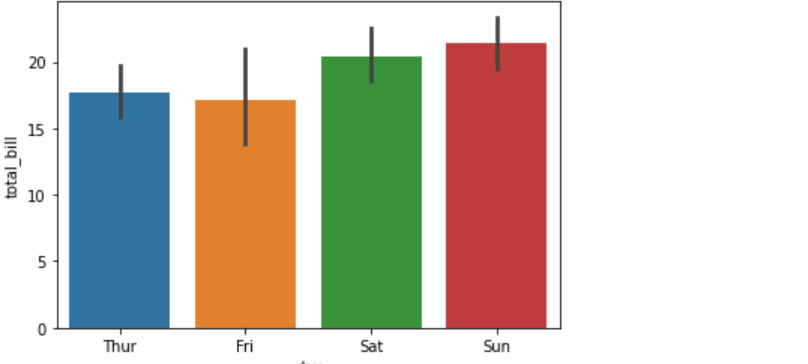
7.3.1 条形图
最常用的查看集中趋势的图形就是条形图。默认情况下,barplot函数会在整个数据集上使用均值进行估计。若每个类别中有多个类别时(使用了hue参数),则条形图可以使用引导来计算估计的置信区间(是指由样本统计量所构造的总体参数的估计区间),并使用误差条来表示置信区间。
使用 barplot()函数的示例如下
sns.barplot("day","total_bill",data=data)
7.3.2 绘制点图
另外一种用于估计的图形是点图,可以调用 pointplot()函数进行绘制,该函数会用高度低计值对数据进行描述,而不是显示完整的条形,它只会绘制点估计和置信区间。
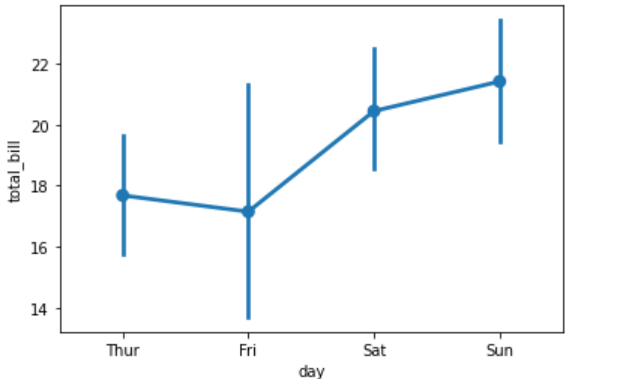
sns.pointplot("day","total_bill",data=data)
7.4 案例:NBA球员数据分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 获取数据
data = pd.read_csv("./nba_2017_nba_players_with_salary.csv")
data.head(5)
# 数据共有342行,38列
data.shape #(342, 38)
# 查看数据描述
data.describe()
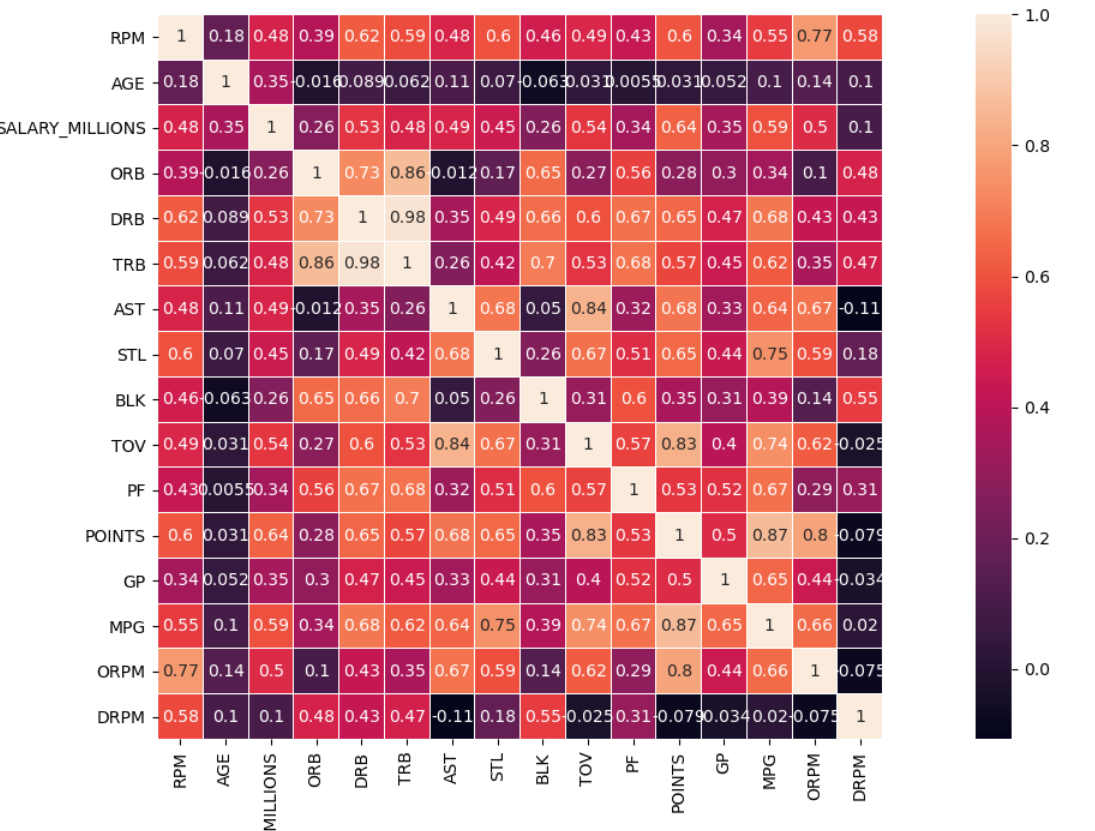
# 效率值相关性分许
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB','AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor.head()
# 获取两列数据之间的相关性
corr = data_cor.corr()
corr.head()
# 设置画布大小,和dpi
plt.figure(figsize=(20,8),dpi=100)
# 热力图展示 square参数变为正方形,设置线宽,显示数据
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)
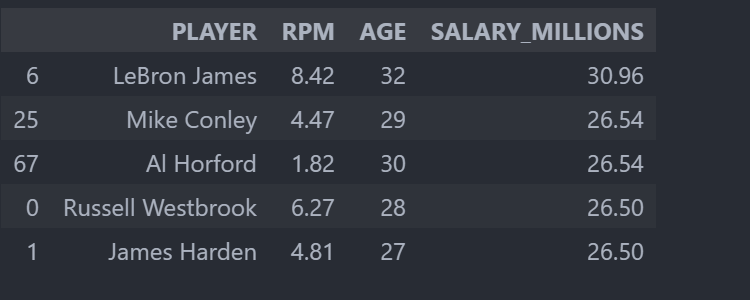
# 按照球员薪资排名,降序
data.loc[:, ["PLAYER", "RPM", "AGE", "SALARY_MILLIONS"]].sort_values(by="SALARY_MILLIONS", ascending=False).head()
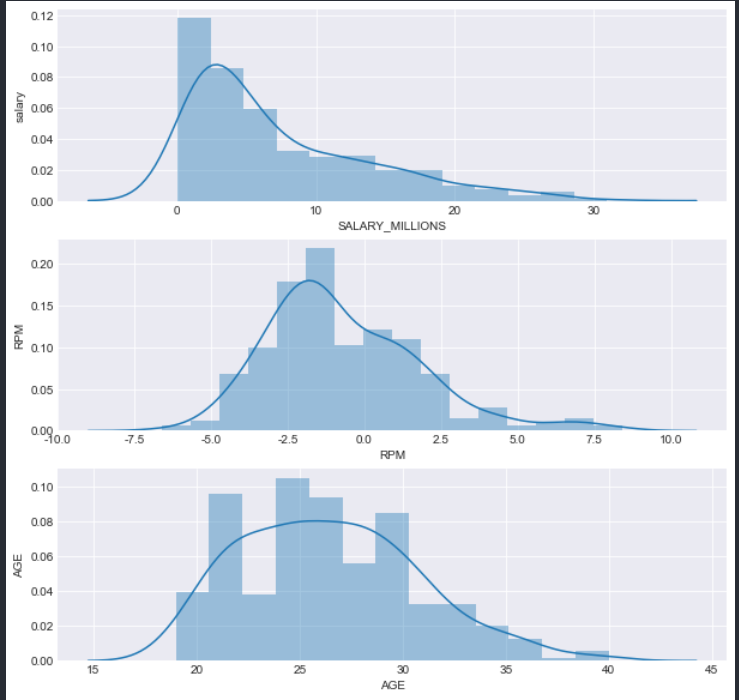
Seaborn常用的三个数据可视化方法
单变量:
# 利用seaborn中的distplot绘图来分别看一下球员薪水、效率值、年龄这三个信息的分布情况
# 设置seaborn的面板风格
sns.set_style("darkgrid")
plt.figure(figsize=(10, 10))
plt.subplot(3, 1, 1)
sns.distplot(data["SALARY_MILLIONS"])
plt.ylabel("salary")
plt.subplot(3, 1, 2)
sns.distplot(data["RPM"])
plt.ylabel("RPM")
plt.subplot(3, 1, 3)
sns.distplot(data["AGE"])
plt.ylabel("AGE")
双变量:
# 球员的年龄和薪水变化关系,六边形分布
sns.jointplot(data.AGE, data.SALARY_MILLIONS, kind="hex")
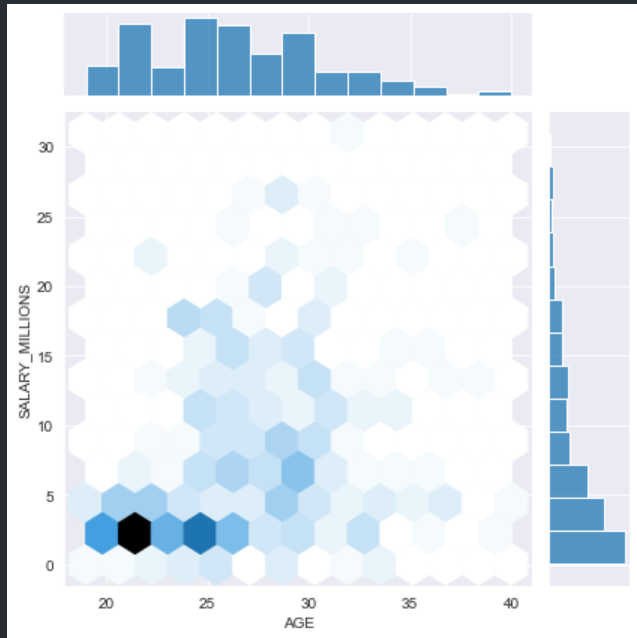
多变量:
multi_data = data.loc[:, ['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
sns.pairplot(multi_data)
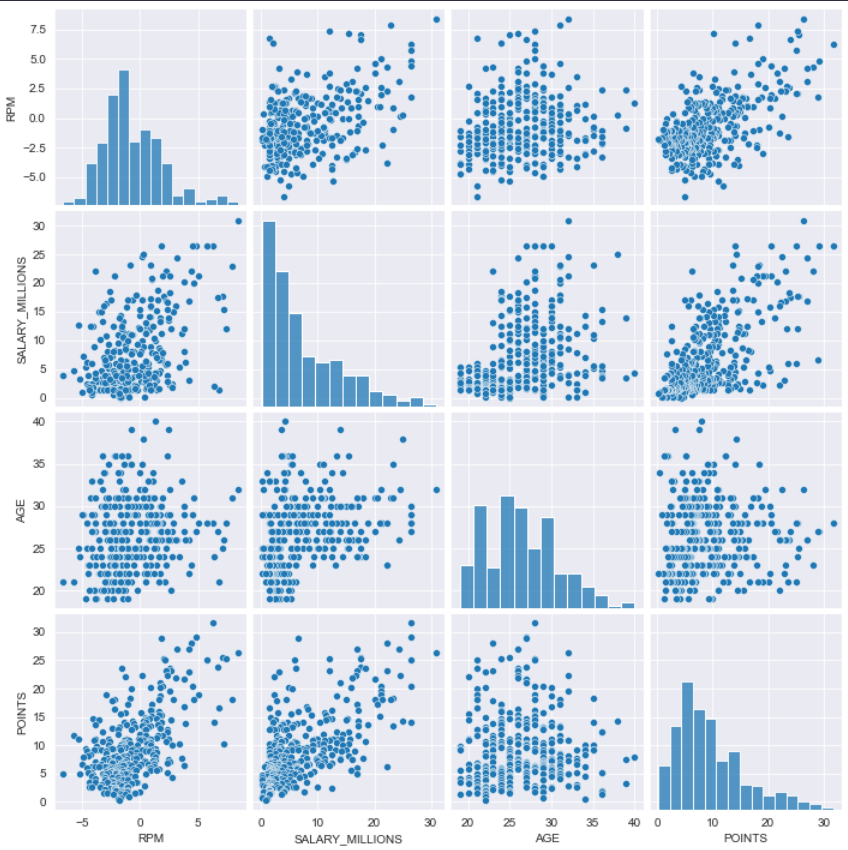
衍生变量的一些可视化实践-以年龄为例
def age_cut(df):
'''年龄划分'''
if df.AGE <= 24:
return "young"
elif df.AGE >= 30:
return "old"
else:
return "best"
# 使用apply对年龄划分
data["age_cut"] = data.apply(lambda x:age_cut(x),axis=1)
data.head()
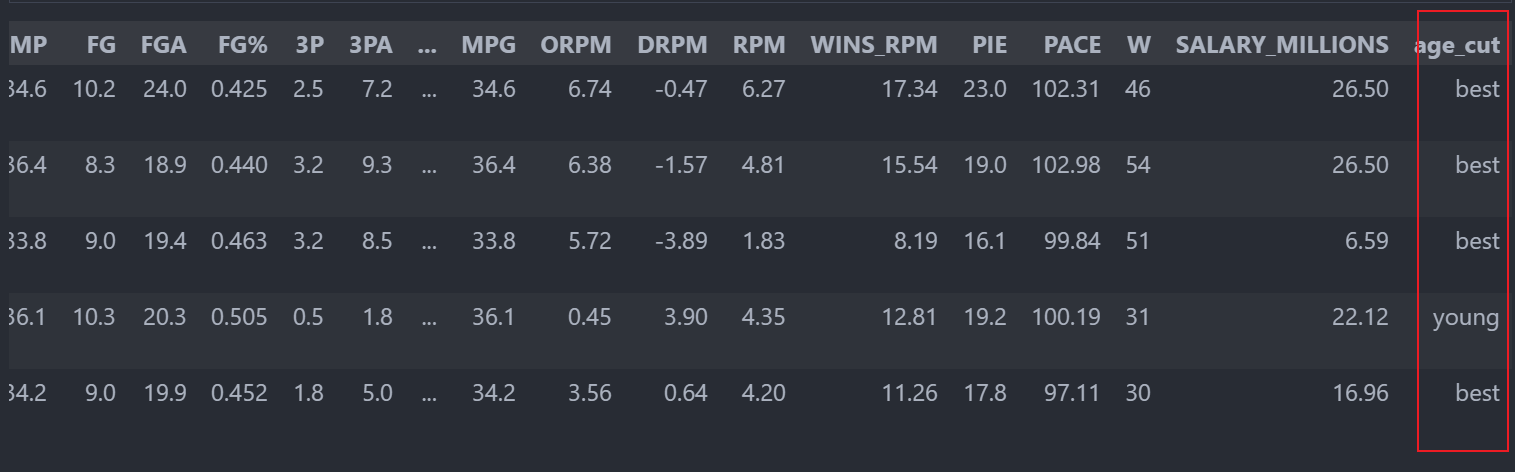
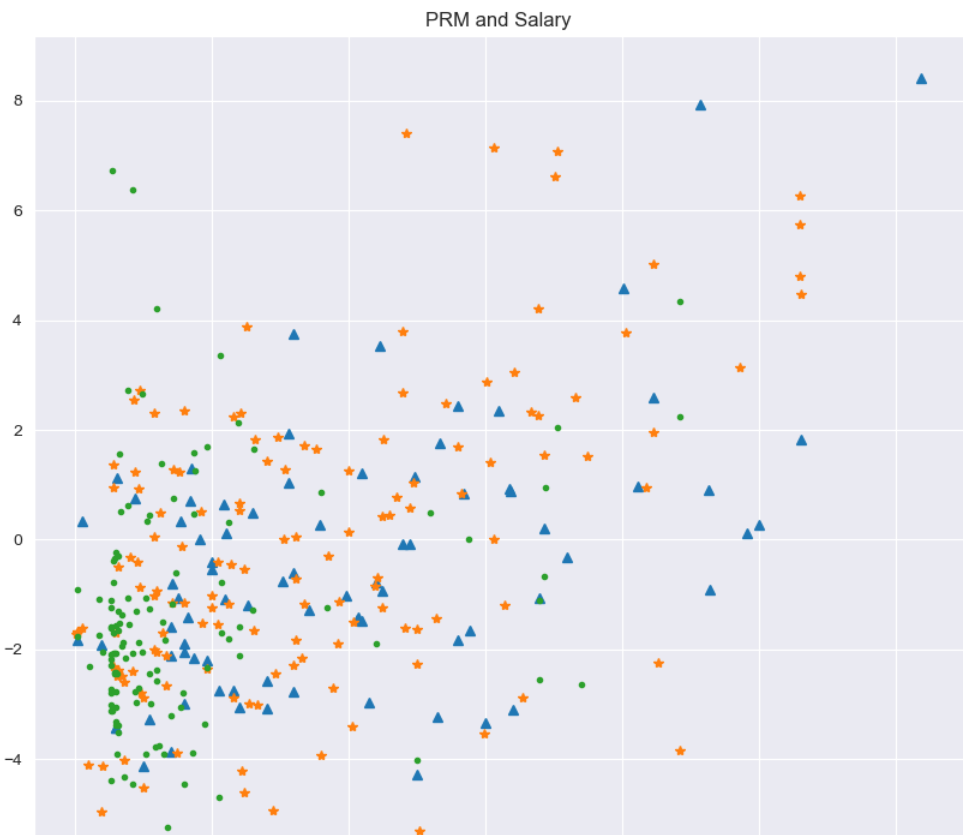
基于年龄段对球员薪水和效率值进行分析
sns.set_style("darkgrid")
plt.figure(figsize=(10,10),dpi=100)
plt.title("PRM and Salary")
x1 = data.loc[data.age_cut == "old"].SALARY_MILLIONS
y1 = data.loc[data.age_cut == "old"].RPM
plt.plot(x1,y1,"^")
x2 = data.loc[data.age_cut == "best"].SALARY_MILLIONS
y2 = data.loc[data.age_cut == "best"].RPM
plt.plot(x2,y2,"*")
x3 = data.loc[data.age_cut == "young"].SALARY_MILLIONS
y3 = data.loc[data.age_cut == "young"].RPM
plt.plot(x3,y3,".")
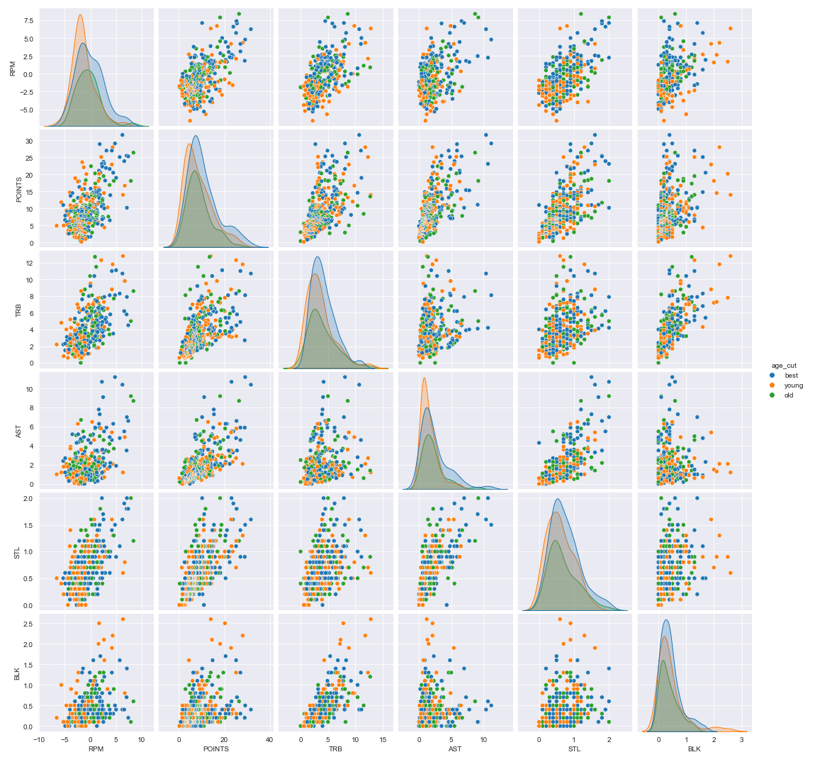
multi_data2 = data.loc[:, ['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(multi_data2,hue='age_cut')