1.为什么使用pandas
Pandas 一个强大的分析结构化数据的工具集,基础是Numpy(提供高性能的矩阵运算)。
Pandas可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。 具有以下优势:
- 增强图表可读性
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、 Numpy的画图和计算
2.pandas主要数据结构
- Series(一维数据)
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。

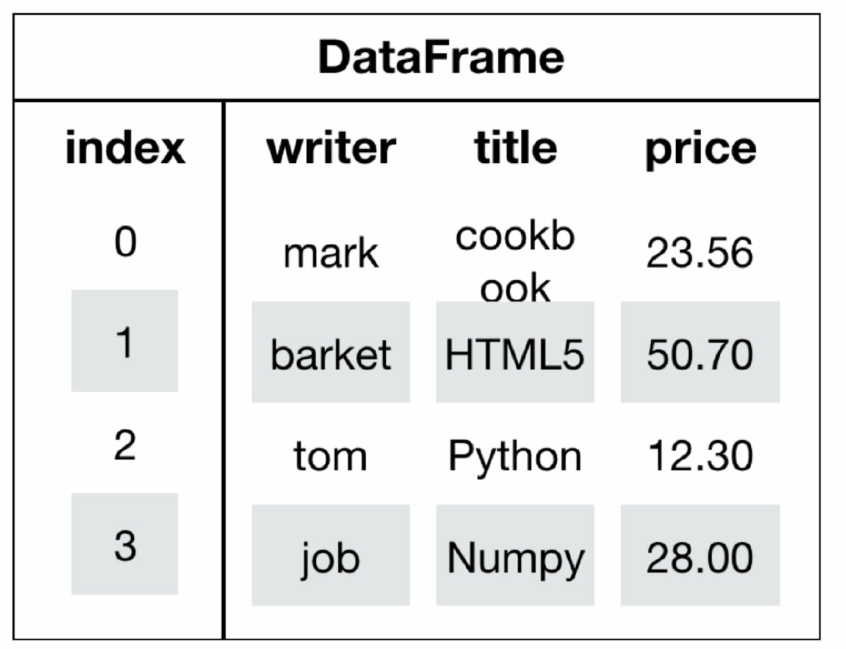
- DataFrame(二维数据)
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表明不同列,纵向索引,叫columns,1轴, axis=1
- MultiIndex(三维数据,老版本中叫Panel)。
多级索引(也称层次化索引) 是pandas的重要功能, 可以在Series、 DataFrame对象上拥有2个以及2个以上的索引。
3.Series的使用
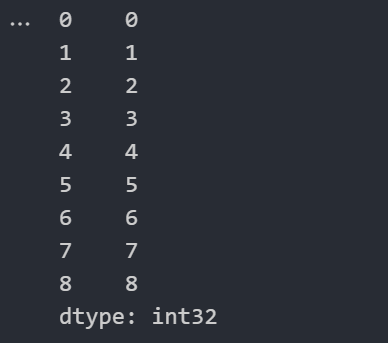
import numpy as np
import pandas as pd
pd.Series(np.arange(9))
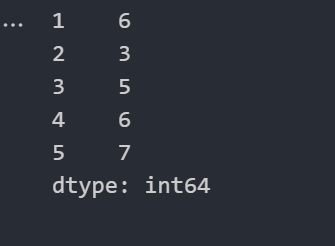
import numpy as np
import pandas as pd
#自定义索引
pd.Series([6,3,5,6,7],index=[1,2,3,4,5])
import numpy as np
import pandas as pd
#字典方式
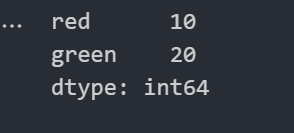
color_count = pd.Series({"red":10,"green":20})
color_count
Series的属性
为了更方便地操作Series对象中的索引和数据, Series中提供了两个属性index和values
-
index
color_count.index # 结果 Index(['blue', 'green', 'red', 'yellow'], dtype='object') -
values
color_count.values # 结果 array([ 200, 500, 100, 1000])
4.DataFrame
import pandas as pd
import numpy as np
# 生成两行三列的数据
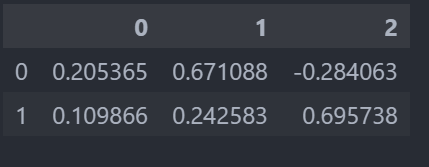
score = pd.DataFrame(np.random.randn(2,3))
score
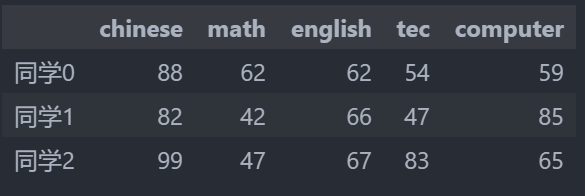
subjects = ["chinese","math","english","tec","computer"]
# score_df.shape[0]是3行 生成3个数
stu = ["同学" + str(i) for i in range(score_df.shape[0])]
stu
data = pd.DataFrame(score,columns=subjects,index=stu)
data
DataFrame的属性
-
shape
data.shape # 结果 (10, 5) -
index
DataFrame的行索引列表 data.index # 结果 Index(['同学0', '同学1', '同学2', '同学3', '同学4', '同学5', '同学6', '同学7', '同学8', '同学9'], dtype='object') -
columns
DataFrame的列索引列表
data.columns
# 结果 Index(['语文', '数学', '英语', '政治', '体育'], dtype='object')
- values
直接获取其中array的值
data.values
- head
查看第一行
data.head(1)
- values
查看所有的值
data.values
- tail
最后面的一行
data.tail(1)
- T
转置,行列互换
data.T
DatatFrame索引的设置
修改索引值
import pandas as pd
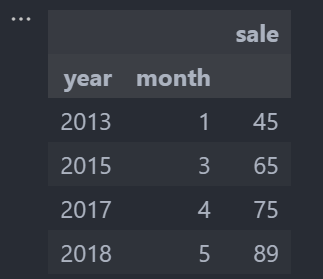
df = pd.DataFrame({"month":[1,3,4,5],
"year":[2013,2015,2017,2018],
"sale":[45,65,75,89]
})
df
# 设置年为索引值
df.set_index("year")
# 设置多个索引值
df.set_index(["year","month"])
3.MultiIndex的使用
3.1 multiIndex的使用
-
创建
arrays = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']] pd.MultiIndex.from_arrays(arrays, names=('number', 'color')) # 结果 MultiIndex(levels=[[1, 2], ['blue', 'red']], codes=[[0, 0, 1, 1], [1, 0, 1, 0]], names=['number', 'color']) -
索引操作
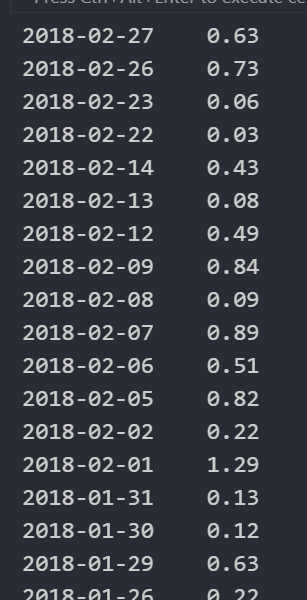
import pandas as pd # 读取文件 data = pd.read_csv("./data/stock_day.csv") # 删除一些列,让数据更简单些 data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1) data = pd.read_csv("./stock_day.csv") # 显示前5行 data.head()

# 直接使用行列索引名字的方式 先列后行,需要通过索引的字符串进行获取
data["open"]["2018-02-27"] #23.53
注意:先行后列会报错,也不支持下标索引的方式
-
结合loc或者iloc使用索引
# 使用loc可以先行后列 # data.loc["2018-02-26"]["open"] #22.8 data.loc["2018-02-27":"2018-02-22","low":"p_change"] # 使用iloc可以通过索引的下标获取 前三行前五列 # data.iloc[:3,:5]
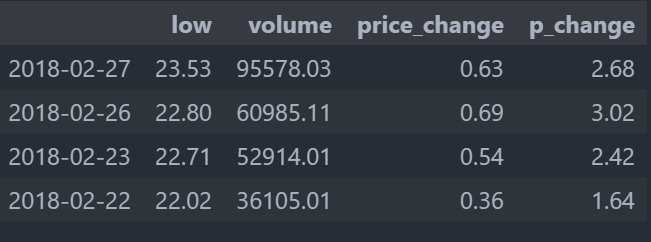
-
赋值操作
import pandas as pd data = pd.read_csv("./stock_day.csv") # 显示前5行 data.head() data["close"] = 1 data.head()

-
排序 ,排序有两种形式, 一种对于索引进行排序, 一种对于内容进行排序
-
DataFrame排序
使用df.sort_values(by=, ascending=)
单个键或者多个键进行排序,
参数:
by: 指定排序参考的键
ascending:默认升序
ascending=False:降序
ascending=True:升序
import pandas as pd
data = pd.read_csv("./stock_day.csv")
# 显示前5行
data.head()
# 按照开盘价大小排序,使用ascending指定按照大小排序
data.sort_values(by="open",ascending=True).head()
data.sort_values(by="high",ascending=False).head()
# 按照多个键排序
data.sort_values(by=["open","high"]).head(3)
# 使用df.sort_index给索引进行排序 日期索引重新排序为从小到大
data.sort_index()
-
Series排序
使用series.sort_values(ascending=True)进行排序
# series排序时,只有一列,不需要参数
data["low"].sort_values(ascending=True).head()
# 使用series.sort_index()进行排序
data["p_change"].sort_index().head()
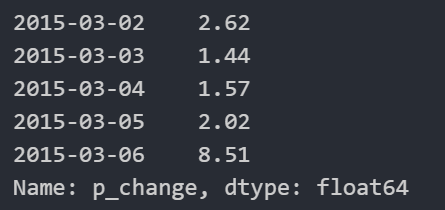
4.DataFrame运算
4.1 算术运算
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("./stock_day.csv")
# 显示前5行
data.head()
data["open"].add(10).head()
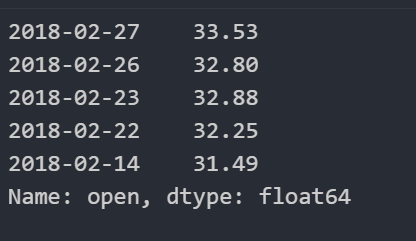
4.2 逻辑运算
import pandas as pd
data = pd.read_csv("./stock_day.csv")
# 查询23<'open'<24的数,显示前五行
data[(data["open"]>23)&(data["open"]<24)].head()
data.query("open<24 & open>23").head()
# 判断'open'是否为23.43和23.85
# data[data["open"].isin([23.43,23.85])]

4.3 统计运算
# 能够取出很多统计结果:count mean std min max等
data.describe()
# 每列最大值
data.max()
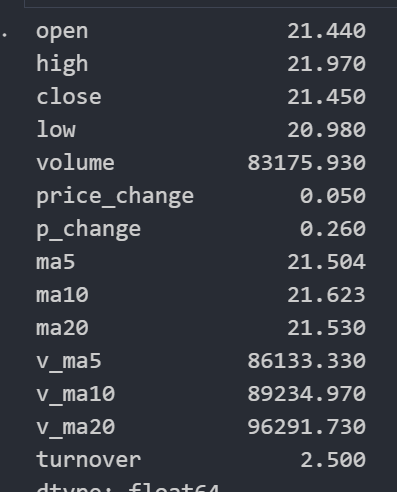
df = pd.DataFrame({'col1':[2,3,4,3,2],
'col2':[0,1,2,5,3]})
df
# 先排序,再求中位数
df.median()
# col1 3.0
# col2 2.0
# dtype: float64
data.idxmax()
data.idxmin()
# 累计统计函数
# 排一下索引
data.sort_index()
data.head()
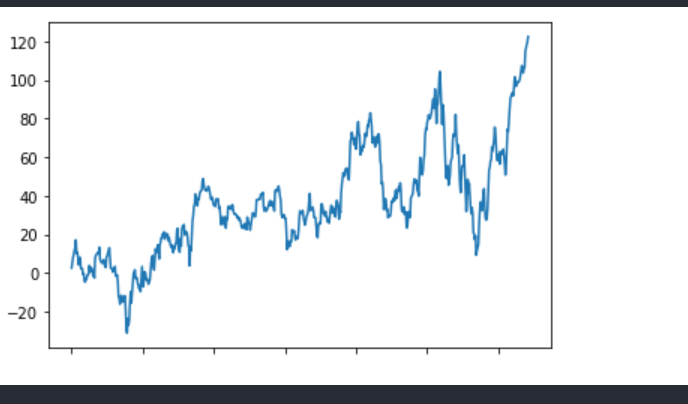
stock_rise = data["p_change"]
# cumsum 累计求和
# stock_rise.cumsum()
# 画图
stock_rise.cumsum().plot()
plt.show()
-
自定义运算
# 'open' 'close'两列的最大值-最小值结果 data[["open","close"]].apply(lambda x: x.max() - x.min(),axis=0) # open 22.74 # close 22.85 # dtype: float64 # 每一行的open close 最大值-最小值 data[["open","close"]].apply(lambda x: x.max() - x.min(),axis=1)
5. pandas画图
5.1 pandas.DataFrame.plot
5.2 pandas.Series.plot
5.3 文件的读取与存储
pandas支持csv、sql、xls、json、hdf5等格式文件。
注意
优先使用HDF5文件存储,使用的方式是blosc,速度很快,节省空间。
-
1.csv
import pandas as pd import matplotlib.pyplot as plt import numpy as np # 读取 data = pd.read_csv("./stock_day.csv",usecols= ["open","close"]) data.head() # 保存 data.to_csv("./test.csv",columns=["close"]) -
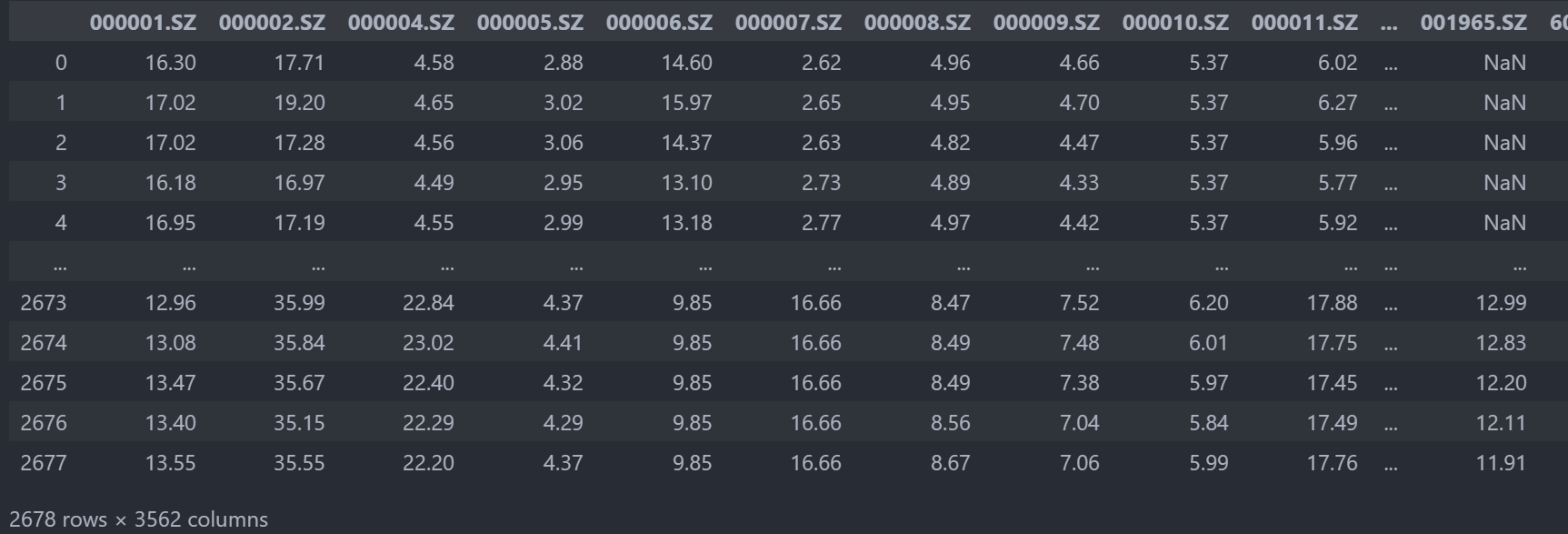
2.HDF5
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
# 读取文件
data_file = pd.read_hdf("./day_close.h5")
data_file.head()
# 存储路径
data_file.to_hdf("./save.h5", key="data_file")
pd.read_hdf("./save.h5")
-
3.json
# 读取 records以 列名:值 {columns:values} 的方式显示 按行读取 data = pd.read_json("./Sarcasm_Headlines_Dataset.json",orient="records",lines=True,) data.head() # 保存 data.to_json("./save.json",orient="records",lines=True) pd.read_json("./save.json",orient="records",lines=True).head()
5.4 缺失值的处理
import numpy as np
import pandas as pd
# 读取电影数据
movie = pd.read_csv("./IMDB-Movie-Data.csv")
# 判断缺失值是否存在 存在缺失值为False
pd.notnull(movie)
# 判断是否都是True,如果有缺失值,就会返回False
np.all(pd.notnull(movie))
# 如果有缺失值,就返回Ture
np.any(pd.isnull(movie))
# 有缺失值怎么办? 删除或者替换
# 删除
data = movie.dropna()
# 如果有缺失值,就返回Ture
np.any(pd.isnull(data))
# 取出这一列的平均值
num_mean = movie["Revenue (Millions)"].mean()
num_mean
# 82.95637614678898
# ba 把该行的缺失值替换为平均值
movie["Revenue (Millions)"].fillna(num_mean,inplace=True)
#再次查看是否替换成功
num_mean = movie["Revenue (Millions)"]
num_mean
# 查找那一列有缺失值
for i in movie.columns:
if np.any(pd.isnull(movie[i])) == True:
print(i)
#替换为平均值
movie[i].fillna(movie[i].mean(),inplace=True)
# 判断是否有缺失值 有为True
np.any(pd.isnull(movie))
# Metascore
5.5 数据离散化
- 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
- 什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
离散化有很多种方法,使用一种最简单的方式去操作
比如原始人的身高数据: 165, 174, 160, 180, 159, 163, 192, 184 假设按照身高分几个区间段: 150~165, 165~180,180~195 这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个”哑变量”矩阵
import pandas as pd
data = pd.read_csv("./stock_day.csv")
data.head()
p_change = data["p_change"]
p_change
# 分组:qcut方法和cut方法
# 自动分成数量差不多的类别:qcut
qcut= pd.qcut(p_change,10)
# 统计每组数量
qcut.value_counts()
# 指定分组区间 cut
bins = [-100,-7,-5,-3,0,3,5,7,100]
p_count = pd.cut(p_change,bins)
# 统计每组数量
p_count.value_counts()
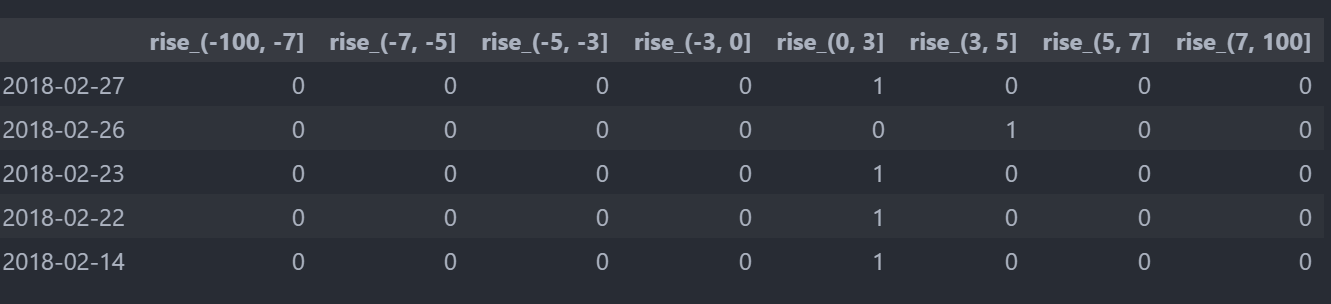
# one-hot编码:把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1,其又被称为热编码。
dummies = pd.get_dummies(p_count,prefix="rise")
dummies.head()
5.6 合并
如果你的数据由多张表组成, 那么有时候需要将不同的内容合并在一起分析
- pd.concat 实现数据合并
pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为列索引, axis=1为行索引
concat = pd.concat([data,dummies],axis=1)
concat.head()
- pd.merge
pd.merge(left, right, how=’inner’, on=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left : DataFrame
right : 另一个DataFrame
on : 指定的共同键
how:按照什么方式连接

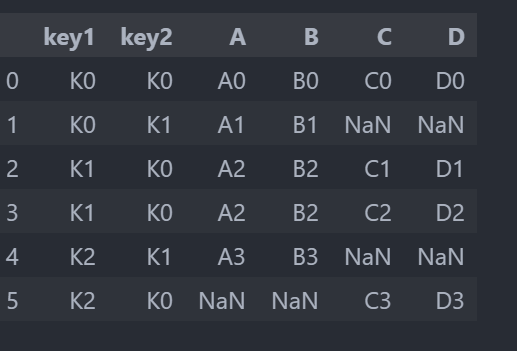
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
right
pd.merge(left,right,on=["key1","key2"])
# 内连接
pd.merge(left,right,on=["key1","key2"],how="inner")
# 左表为主
pd.merge(left,right,on=["key1","key2"],how="left")
# 右表为主
pd.merge(left,right,on=["key1","key2"],how="right")
# 外连接
pd.merge(left,right,on=["key1","key2"],how="outer")
5.7 交叉表与透视表
-
交叉表: 交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表) pd.crosstab(value1, value2)
-
透视表: 透视表是将原有的DataFrame的列分别作为行索引和列索引, 然后对指定的列应用聚集函数 data.pivot_table() DataFrame.pivot_table([], index=[])
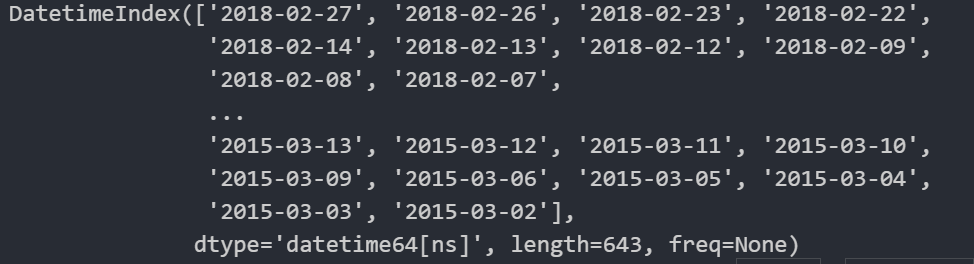
import pandas as pd data.index

# 转换为日期格式
time = pd.to_datetime(data.index)
time
# 打印时间中的日
time.day

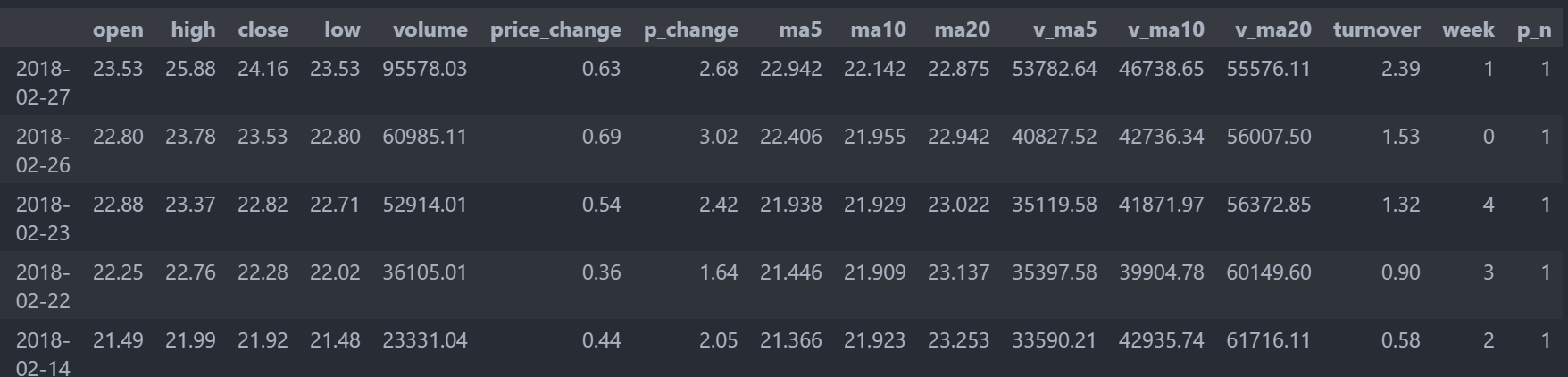
# 插入列week
data["week"] = time.weekday
data.head()

# p_change列中的数据大于0置为1,否则置为0
data["p_n"] = np.where(data["p_change"]>0 ,1,0)
data.head()
5.8 分组与聚合
分组与聚合通常是分析数据的一种方式, 通常与一些统计函数一起使用, 查看数据的分组情况
- 分组API
DataFrame.groupby(key, as_index=False)
key:分组的列数据, 可以多个
案例:不同颜色的不同笔的价格数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
col
# 分组,求平均值 根据color对price1分组,并求平均值
col.groupby(["color"])["price1"].mean()
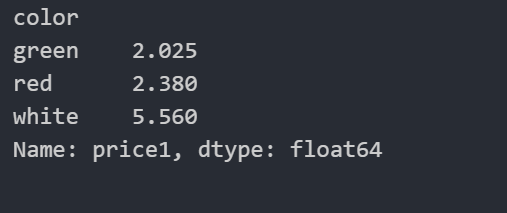
col["price1"].groupby(col["color"]).mean()
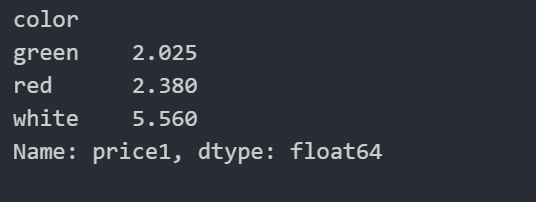
# as_index=False 保留原索引
col.groupby(["color"],as_index=False)["price1"].mean()
import matplotlib.pyplot as plt
starbucks = pd.read_csv("./directory.csv")
starbucks.head()
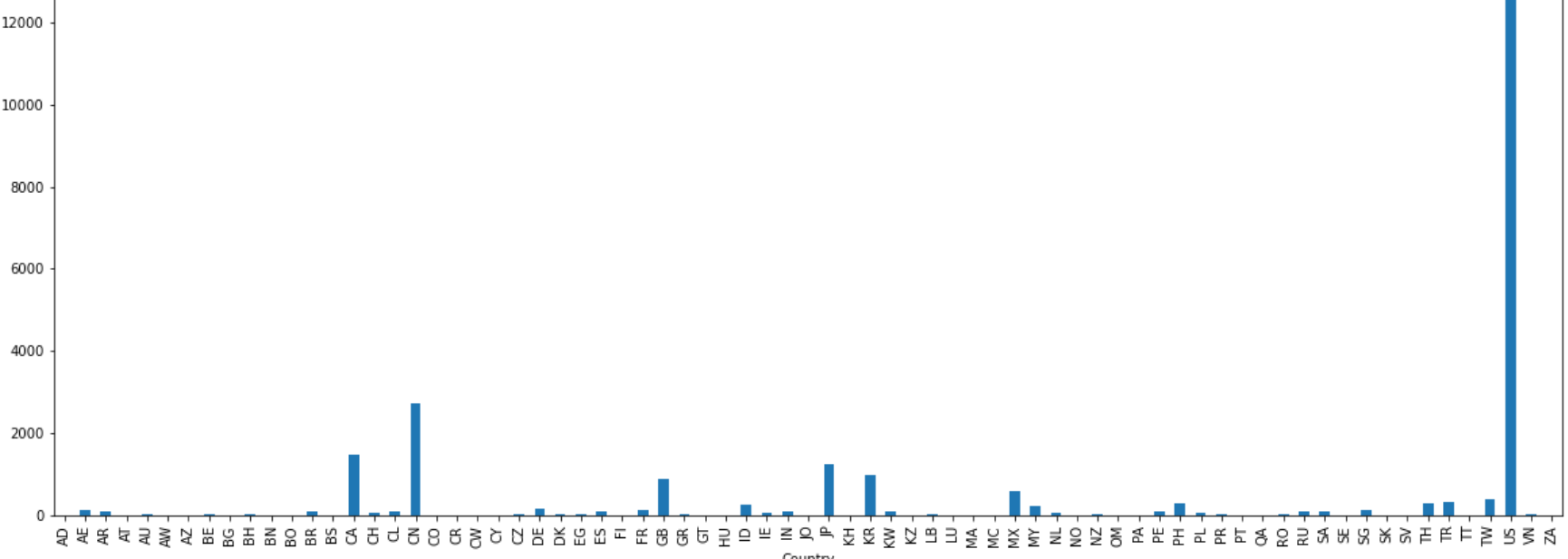
count = starbucks.groupby(["Country"]).count()
count
count["Brand"].plot(kind="bar",figsize=(20,8))
plt.show()
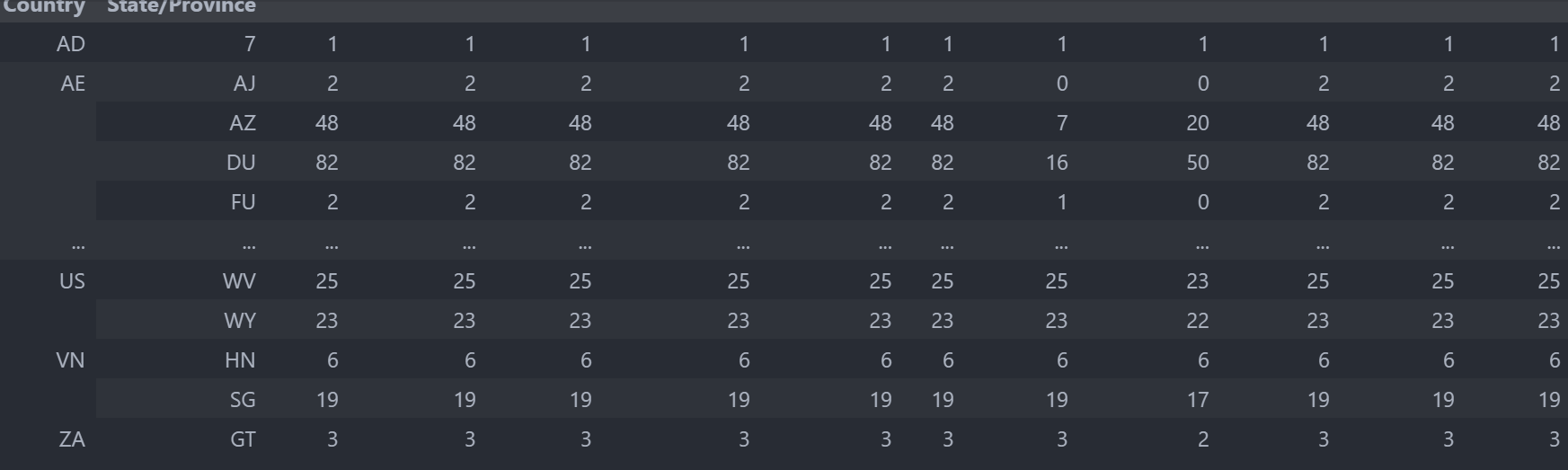
starbucks.groupby(["Country","State/Province"]).count()
电影数据案例分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
movie = pd.read_csv("./IMDB-Movie-Data.csv")
movie.head()
# 获取平均分
movie["Rating"].mean()
# 获取导演人数
np.unique(movie["Director"]).shape[0]
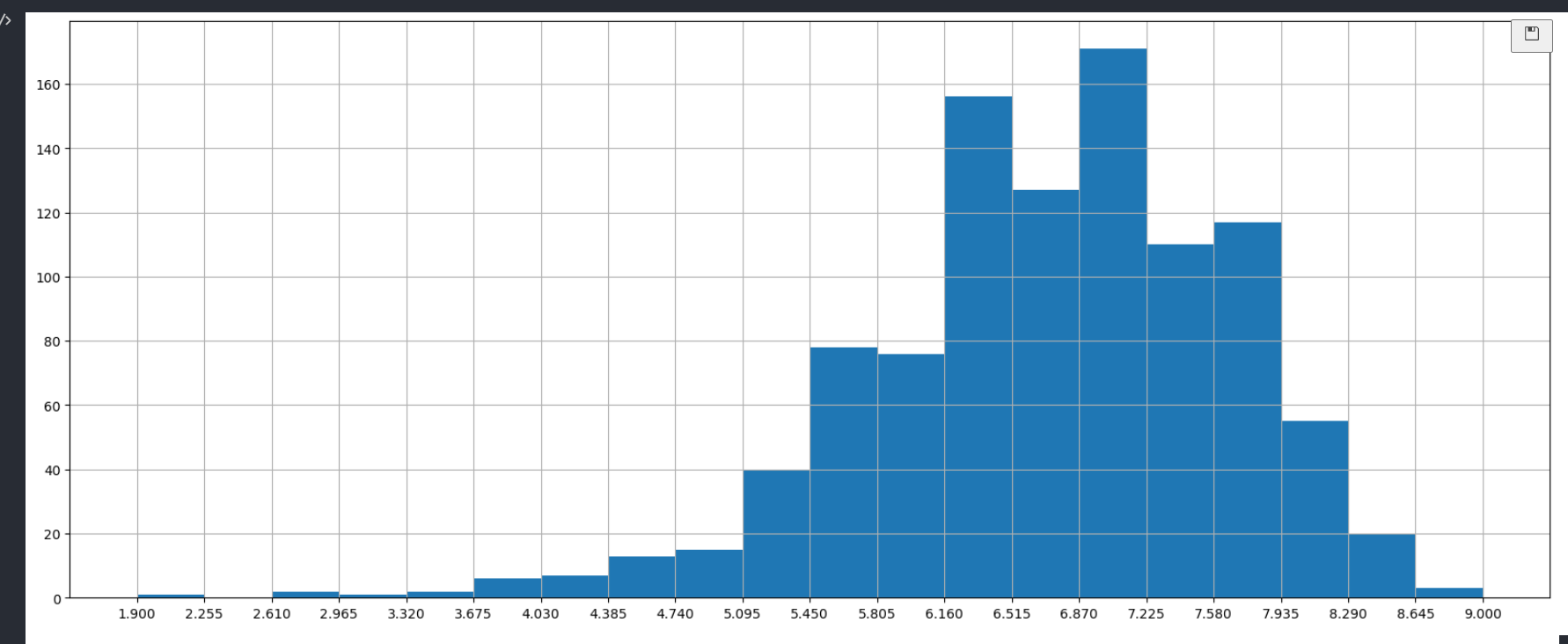
# Rating分布
movie["Rating"].plot(kind="hist")
# 分20组
# 创建画布
plt.figure(figsize=(20,8),dpi=100)
# 修改刻度的间隔
max_ = movie["Rating"].max()
min_ = movie["Rating"].min()
# 生成刻度列表
t1 = np.linspace(min_,max_,num=21)
plt.xticks(t1)
# 添加网格
plt.grid()
# 绘制图像
plt.hist(movie["Rating"].values,bins=20)
# 显示图像
plt.show()