
1.概述
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测。
2. 主要方向
- 计算机视觉(CV)
计算机视觉是指机器感知环境的能力。物体检测和人脸识别是其比较成功的研究领域。
- 语音识别
语音识别是指识别语音,并将其转换成对应文本的技术。语音识别目前仍然面临着声纹识别和鸡尾酒会效应等一些难题。现代语音识别系统严重依赖云,在离线时可能无法取得理想的效果。
- 文本发掘/分类
- 机器翻译
利用机器的力量将一种自然语言(源语言)的文本翻译成另一种语言(目标语言)。
- 机器人
分为两类:固定机器人和移动机器人。
3. 工作流程
机器学习:是从数据中自动分析获得模型,并利用模型对未知数据进行预测。
3.1 机器学习工作流程:
- 1.获取数据
- 2.数据基本处理
- 3.特征工程
- 4.机器学习(模型训练)
-
5.模型评估
- 结果达到要求,上线服务
- 没有达到要求,重新上面步骤
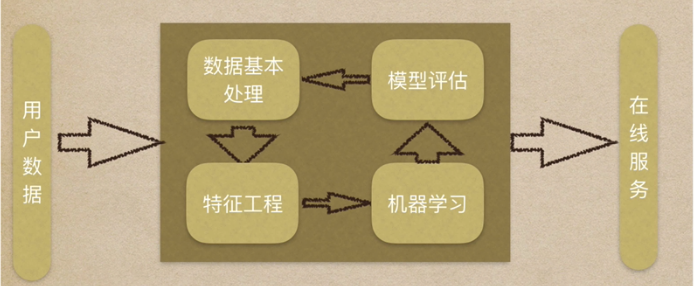
3.2 获取到的数据集介绍
1.专有名词
- 一行数据我们称为一个样本
- 一列数据我们称为一个特征
- 目标值(标签值)
- 特征值
2.数据类型构成
类型一:特征值+目标值,目标值分为是离散还是连续
类型二:只有特征值,没有目标值
3.数据划分:
- 机器学习一般的数据集划分为两个部分:
- 训练数据(数据集):用于训练,构建模型,70%-80%
- 测试数据(测试集):在模型检验时使用,用于评估模型是否有效,20%-30%
3.3 数据基本处理
对数据进行缺失值、去除异常值等处理
3.4 特征工程
特征工程指的是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好作用的过程。(把数据转换成机器更容易识别的数据)
意义:会直接影响机器学习的效果
为什么需要特征工程?
数据和特征决定了机器学习的上限,而模型和算法只是逼近了这个上限而已。
特征工程包含内容:
-
特征提取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
-
特征预处理:通过一些转换函数将特征数据转换为更合适算法模型的特征数据过程
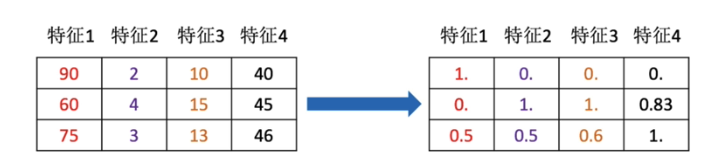
- 特征降维:指在某些限定条件下,降低随机变量(特征)个数,得到一组
不相关主变量的过程
4. 机器学习算法分类
4.1 根据数据集组成不同,分为:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
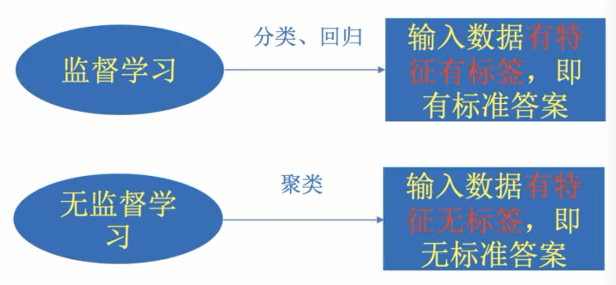
4.2 监督学习(有特征值、目标值)
-
定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称为分类)
-
In:有标签 Out:有反馈
-
目的:预测结果
-
案例:猫狗分类 房价预测
-
分类:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
-
回归:线性回归、岭回归
4.3 无监督学习(只有特征值)
-
定义:输入数据是由输入特征组成,没有目标值。
-
In:无标签 Out:无反馈
-
目的:发现潜在结构
-
案例:物以类聚,人以群分
-
聚类 k-means,降维
监督学习和无监督学习区别:
4.4 半监督学习(有特征值,但是一部分数据有目标值,一部分没有)
- 定义:训练集同时包含有标记样本数据和未标记样本数据。
- 已知:训练样本Data和待分类的类别
- 未知:训练样本有无标签均可
- 应用(案例):训练数据量过多时,监督学习效果不能满足需求,因此用来增强效果。
4.5 强化学习
-
定义: 自动进行决策,并且可以做连续决策。强化学习是一个动态过程,上一步数据的输出是下一步数据的输入,强化学习的目标是获得最多的累计奖励。
-
主要包含四个元素: agent、action、environment、Reward(奖励)
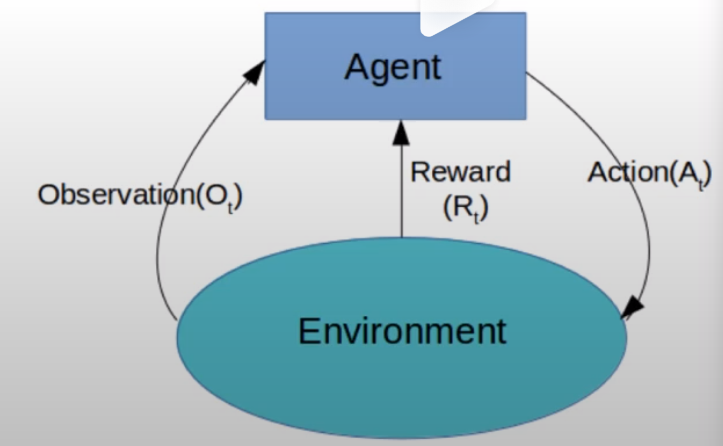
- In: 决策流程及激励系统,Out: 一系列行动
- 目的: 长期利益最大化,回报函数(只会提示你是否在朝着目标方向前进的延迟反映)
- 案例: 学下棋
- 算法: 马尔科夫决策,动态规划
下图为监督学习和强化学习的区别:
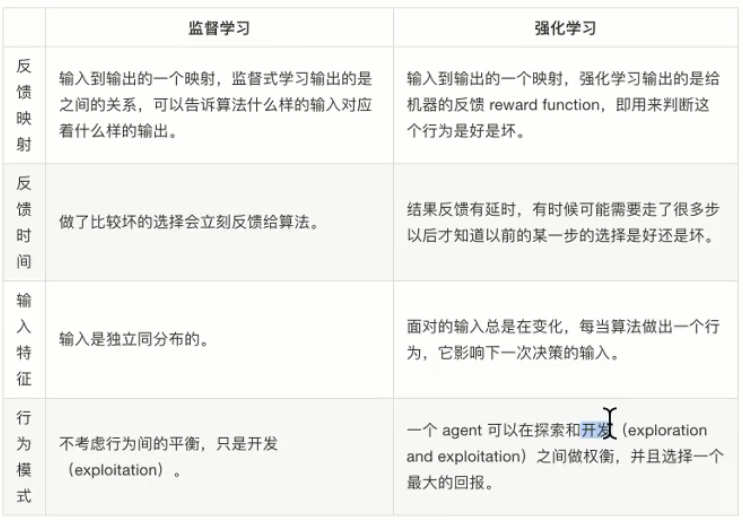
什么是独立同分布?
独立是说每次抽样之间没关系,不会互相影响
同分布是说每次抽样,样本服从同一个分布
独立同分布是说每次抽样之间独立而且同分布
西瓜书解释:输入空间中的所有样本服从一个隐含未知的分布,训练数据所有样本都是独立地从这个分布上采样而得。
对比小结:
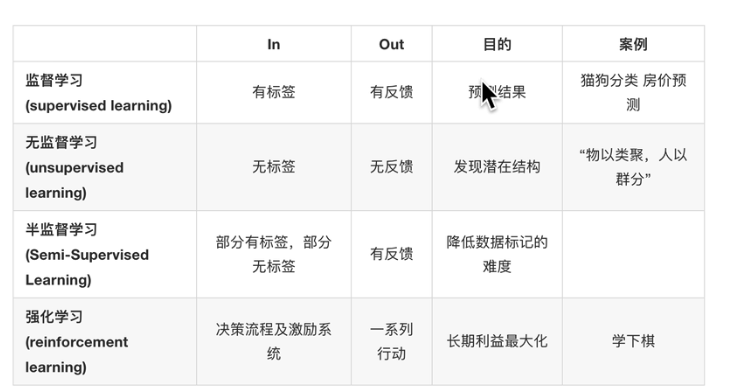
5. 模型评估
按照数据集的目标值不同,可以把模型评估分为分类模型评估和回归模型评估。
5.1 分类模型评估
评价指标:
- 准确率:预测正确的数占样本总数的比例
- 精确率:正确预测为正占全部预测为正的比例
- 召回率:正确预测为正占全部正样本的比例
- F1-score:主要用于评估模型的稳健性
- AUC:主要用于评估样本不均匀的情况
5.2 回归模型评估
均方根误差(RMSE)
- RMSE是一个衡量回归模型误差率的常用公式。不过,它仅能比较误差是相同单位的模型。如下图,p是预测值,a是真实值。

- 相对平方误差(RSE)
RSE可以比较误差是不同单位的模型
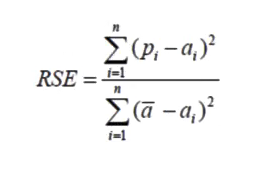
- 平均绝对误差(MAE)
MAE与原始数据单位相同,它仅能比较误差是相同单位的模型。量级近似于RMSE,但是误差值相对小一些。
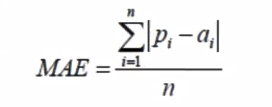
- 相对绝对误差(RAE)
RAE可以比较误差是不同单位的模型
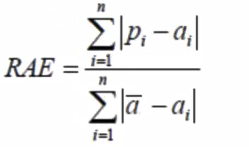
- 决定系数
决定系数回归模型汇总了回归模型的解释度,由平方和术语计算而得。

5.3 拟合
模型评估用于评价训练好的模型的表现效果,其表现效果大致可以分为两类:过拟合、欠拟合。
在训练过程中,可能遇到下面问题:
训练数据训练的很好,误差不大,为什么测试集上有问题呢?
当算法在某个数据集当中出现这种情况,可能就出现了拟合问题。
5.3.1 欠拟合
模型学习的太过粗糙,连训练集中的样本数据特征关系都没有学出来。
5.3.2 过拟合
模型在训练样本中表现过于优越,导致在测试数据集表现不佳。