
一.从进程理解容器
1.理解几个事实
- 容器技术的兴起源于 PaaS 技术的普及;
- Docker 公司发布的 Docker 项目具有里程碑式的意义;
- Docker 项目通过“容器镜像”,解决了应用打包这个根本性难题;
- 容器的本质是一种特殊的进程。
2.进程
一旦“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运行起来后的计算机执行环境的总和,就是我们说的进程。
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法
3.PID Namespace介绍
比如我们创建一个docker
$ docker run -it busybox /bin/sh
然后容器里执行ps命令,可以看到,我们在 Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行,且已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。当我们在宿主机上运行了一个 /bin/sh 程序,操作系统都会给它分配一个进程编号,比如 PID=100。这个编号是进程的唯一标识。而现在通过docker运行,对被隔离应用的进程空间做了处理,使得这些进程只能看到重新计算过的进程编号,比如PID=1,实际上他们在宿主机的操作系统里还是原来的100进程。这种机制就是Linux 里面的 Namespace 机制。
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
4.容器的基本实现原理
除了PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;
Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
这,就是 Linux 容器最基本的实现原理了。 实际上在创建容器进程时,制定了这个进程所需要启用的一组Namespace参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
所以说,容器,其实是一种特殊的进程而已。
5.容器和虚拟机的区别
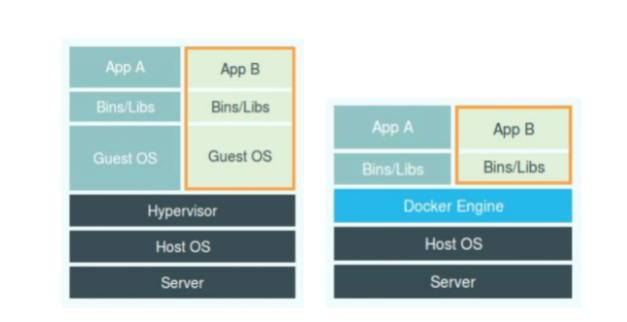
左边是虚拟机的工作原理,使用虚拟化技术作为应用沙盒,就必须要由 Hypervisor 来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。
右边是docker工作原理,容器化后的用户应用,却依然还是一个宿主机上的普通进程,这就意味着这些因为虚拟化而带来的性能损耗都是不存在的;而另一方面,使用 Namespace 作为隔离手段的容器并不需要单独的 Guest OS,这就使得容器额外的资源占用几乎可以忽略不计。
二.隔离与限制
1.Linux Namespace 的隔离机制有什么问题
敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。不过相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
-
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
-
其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
-
还有是基于共享宿主机内核的事实,容器给应用暴露出来的攻击面是相当大的,应用“越狱”的难度自然也比虚拟机低得多。
2.为什么要对容器做限制,Linux Cgroups做怎么限制?
由于容器之间是平等的竞争关系,每个容器能使用的资源可以随时被宿主机上别的容器占用,也可能吃光所有的资源,Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。 此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu可以用 mount 指令把它们展示出来,这条命令是:
$ mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
输出结果,是一系列文件系统目录。/sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
cfs_period 和 cfs_quota 这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container
root@ubuntu:/sys/fs/cgroup/cpu$ ls container/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
这个目录就称为一个“控制组”。操作系统会在新创建的 container 目录下,自动生成该子系统对应的资源限制文件。 执行一个死循环,可以把计算机的 CPU 吃到 100%
$ while : ; do : ; done &
[1] 226
top 指令来确认一下 CPU 有没有被打满
$ top
%Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
接下来,我们可以通过修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
我们可以用 top 指令查看一下,计算机的 CPU 使用率立刻降到了 20%
$ top
%Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
除 CPU 子系统外,Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
我们通过执行docker run时的参数指定,来修改控制组下面的资源文件。如下面命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
启动后,查看 Cgroups 文件系统下CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认,这个 Docker 容器,只能使用到 20% 的 CPU 带宽。
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
总之,一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
3.Linux Cgroups有什么问题?
跟 Namespace 的情况类似,Cgroups 对资源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系统的问题。
Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。但是,你如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
4.如何修复容器中的 top 指令以及 /proc 文件系统中的信息呢?
Mount Namespace 修改的是容器进程对文件系统“挂载点”。Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
为了能够让容器的这个根目录看起来更“真实”,我们一般会在这个容器的根目录下挂载一个完整操作系统的文件系统,比如 Ubuntu18.04 。这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc。当进入容器之后执行的 /bin/bash,就是 /bin 目录下的可执行文件,与宿主机的 /bin/bash 完全不同。
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。这两个系统调用虽然功能类似,但是也有细微的区别。
需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核。
三.深入理解容器镜像
1.什么是容器的一致性
正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。对一个应用来说,操作系统本身才是它运行所需要的最完整的“依赖库”。
有了容器镜像“打包操作系统”的能力,这个最基础的依赖环境也终于变成了应用沙盒的一部分。这就赋予了容器所谓的一致性:无论在本地、云端,还是在一台任何地方的机器上,用户只需要解压打包好的容器镜像,那么这个应用运行所需要的完整的执行环境就被重现出来了。
2.什么是联合文件系统(Union File System)?
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
这就用到了联合文件系统,它最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
比如ubuntu16.04,使用的是AuFS这个联合文件系统实现的。从结构可以看出来,容器的 rootfs 由如下图所示的三部分组成:
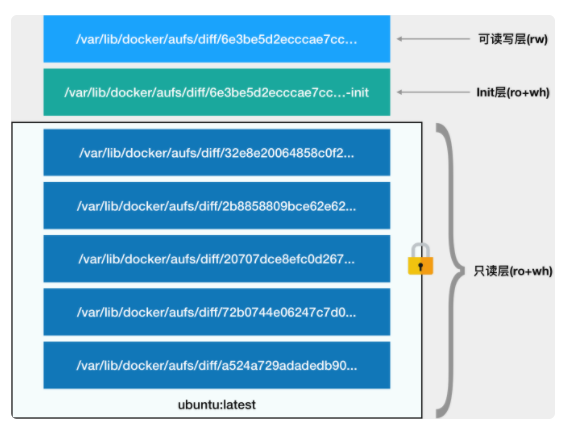
- 只读层:
是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的
- 可读写层:
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
- Init 层:
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
最终,这 7 个层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
3.如何使用Dockerfile制作容器镜像?
演示demo
# 使用官方提供的Python开发镜像作为基础镜像
FROM python:3.7-slim
# 将工作目录切换为/app
WORKDIR /app
# 将当前目录下的所有内容复制到/app下
ADD . /app
# 使用pip命令安装这个应用所需要的依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 允许外界访问容器的80端口
EXPOSE 80
# 设置环境变量
ENV NAME World
# 设置容器进程为:python app.py,即:这个Python应用的启动命令
CMD ["python", "app.py"]
CMD ["python", "app.py"]等价于docker run <image> python app.py。