
一.常用的损失函数
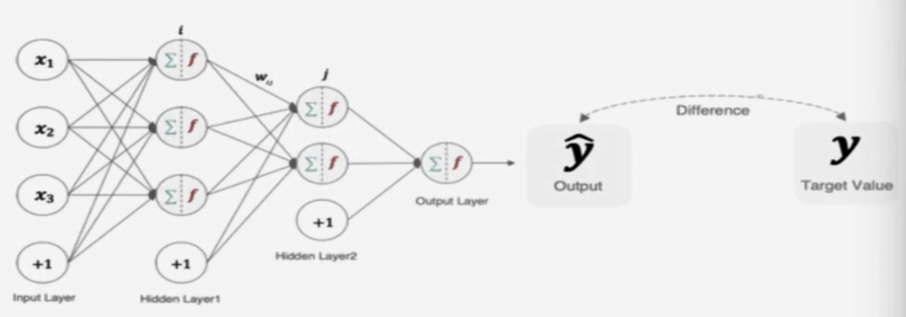
在深度学习中,损失函数是用来衡量模型参数的质量的函数,衡量的方式是比较网络输出和真实输出的差异,损失函数在不同的文献中名称是不一样的,虽然叫法不同,都统一表示损失函数。主要有以下几种命名方式:
| 命名方式 | |
|---|---|
| 损失函数 | loss function |
| 代价函数 | cost function |
| 目标函数 | objective function |
| 误差函数 | error function |
二.分类任务
在深度学习的分类任务中使用最多的是交叉熵损失函数,所以着重歇息这种损失函数。
1.多分类任务
多分类任务通常使用softmax将logits转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失。它的计算方式是:
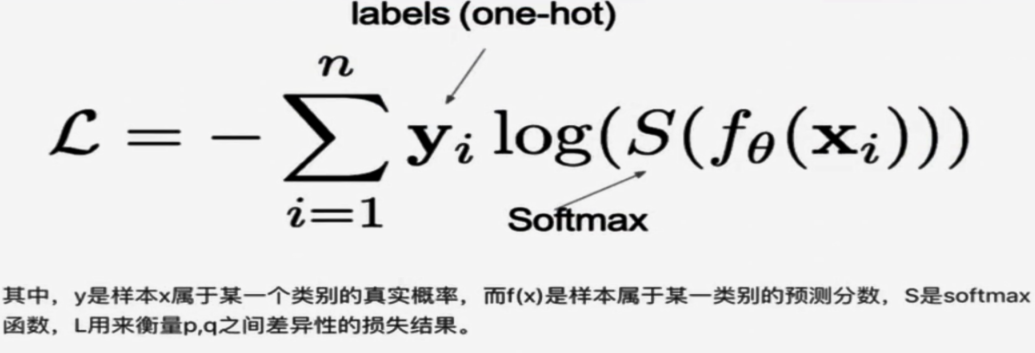
从概率角度理解,我们的目的是最小化正确类别所对应的预测概率的对数的负值,即最大化概率值。在tf.keras中使用CategoricalCrossentropy实现,如下所示:
import tensorflow as tf
# 设置真实值和预测值
y_true = [[0, 1, 0], [0, 0, 1]]
y_pred = [[0.05, 0.95, 0], [0.1, 0.8, 0.1]]
# 实例化交叉熵损失
cce = tf.keras.losses.CategoricalCrossentropy()
# 计算损失结果
print(cce(y_true, y_pred).numpy()) # 1.1769392