
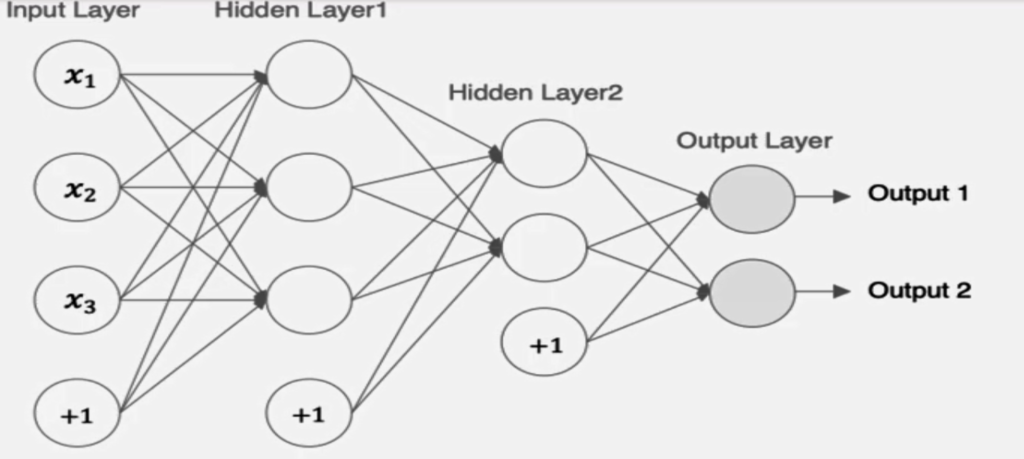
一.神经网络介绍
1. 什么是神经网络
神经网络(NN)是一种模仿生物神经网络结构和功能的计算模型。
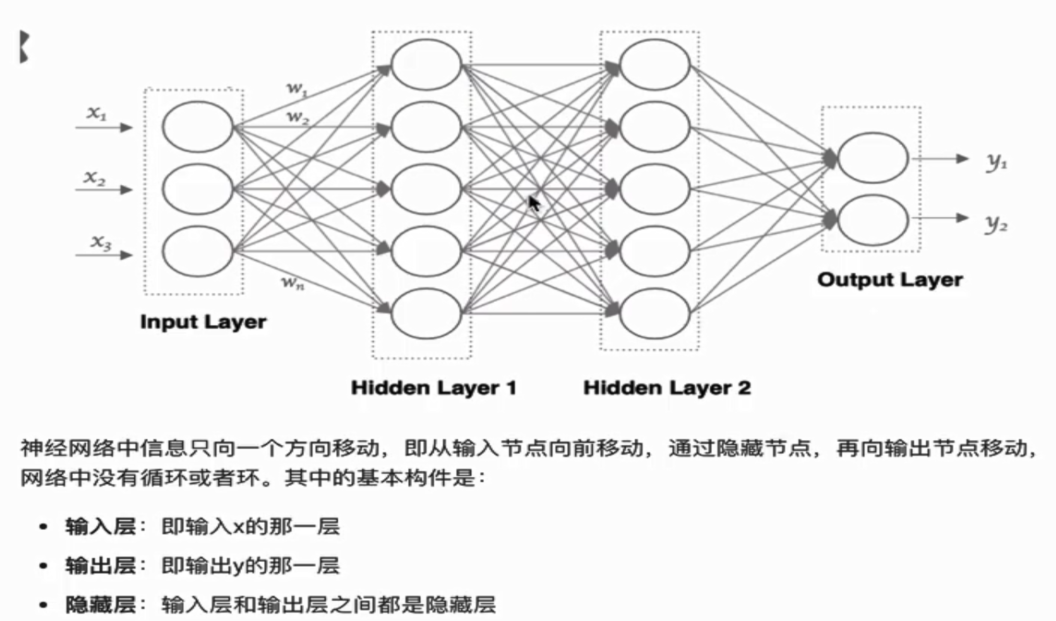
特点:
- 同一层的神经元之间没连接
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是full connected的含义),第N-1层神经元的输出就是第N层神经元的输入
- 每个连接都有一个权值
2. 神经元如何工作
人工神经元接收到一个或多个输入,对他们进行加权并相加,总和通过一个非线性函数产生输出。
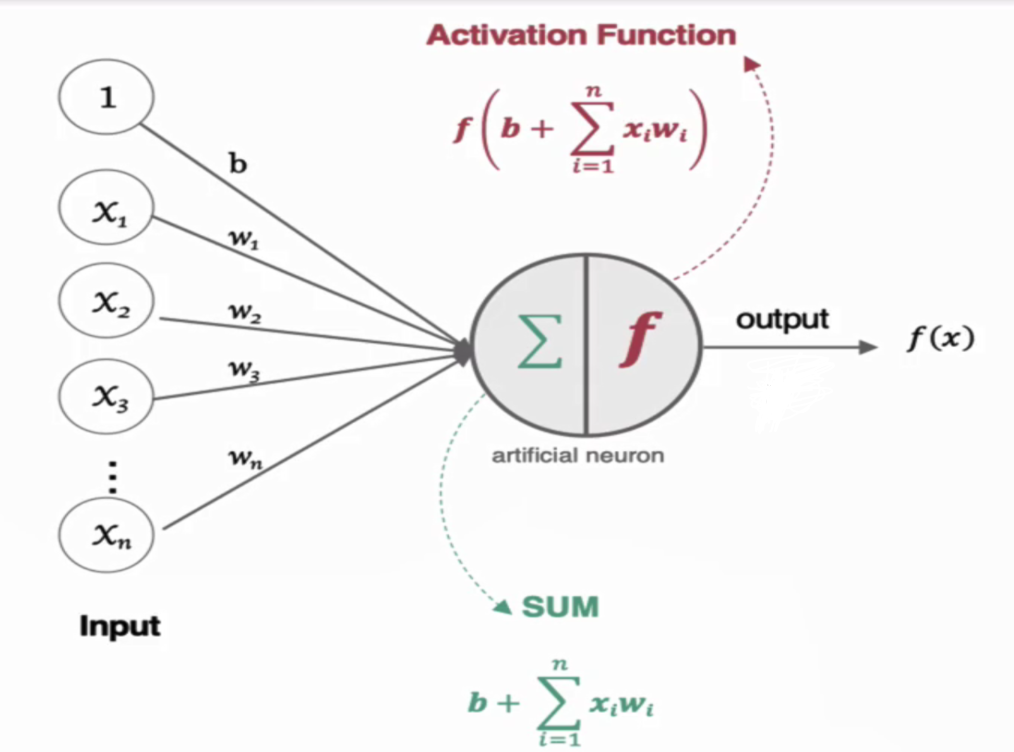
二.激活函数介绍
在神经元中引入了激活函数,它的本质是向神经网络中引入非线性因素的,通过激活函数,神经网络就可以拟合和各种曲线。如果不用激活函数,每一层的输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,引入非线性函数作为激活函数,那输出不再是输入的线性组合,可以逼近任意函数。常用的激活函数有:
1.Sigmoid/Logistics函数
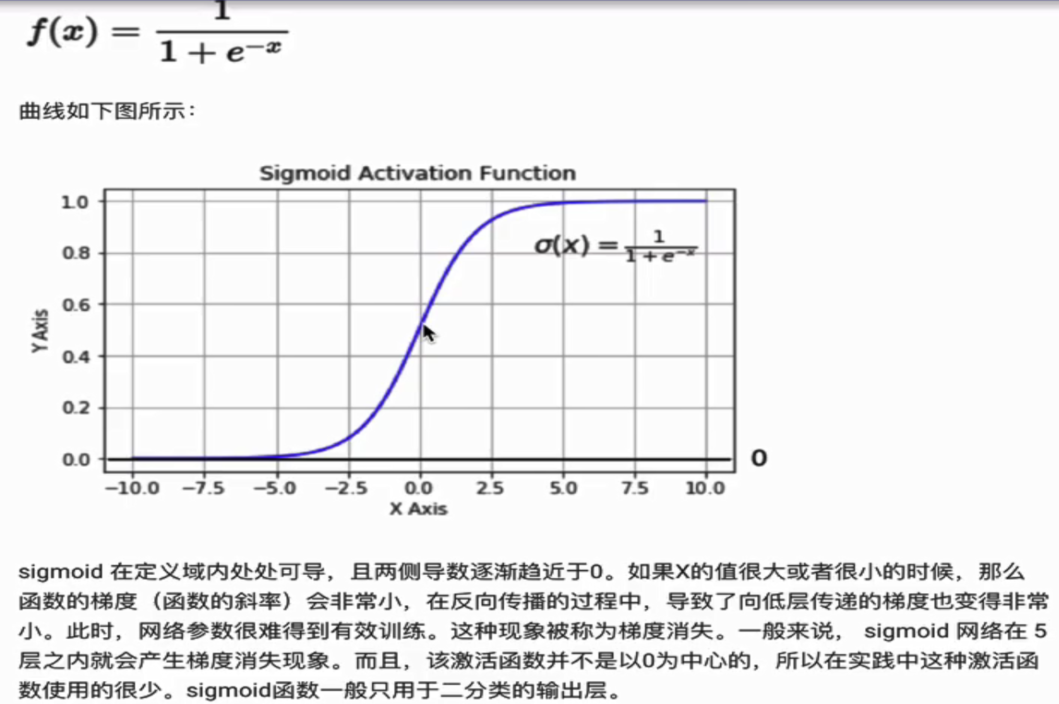
代码实现:
# 导入相应的工具包
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-15, 15, 100)
# 直接使用tf实现
y = tf.nn.sigmoid(x)
# 绘图
plt.plot(x, y)
plt.grid()
plt.show()运行结果:
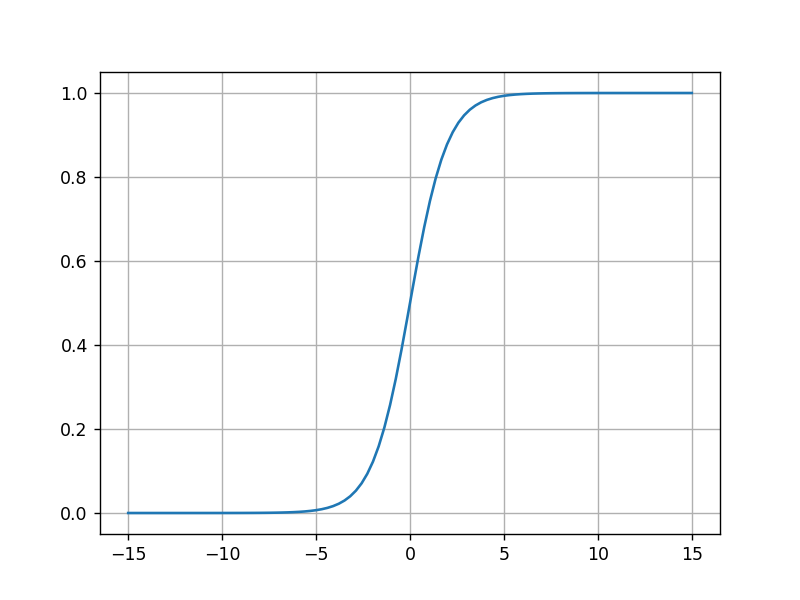
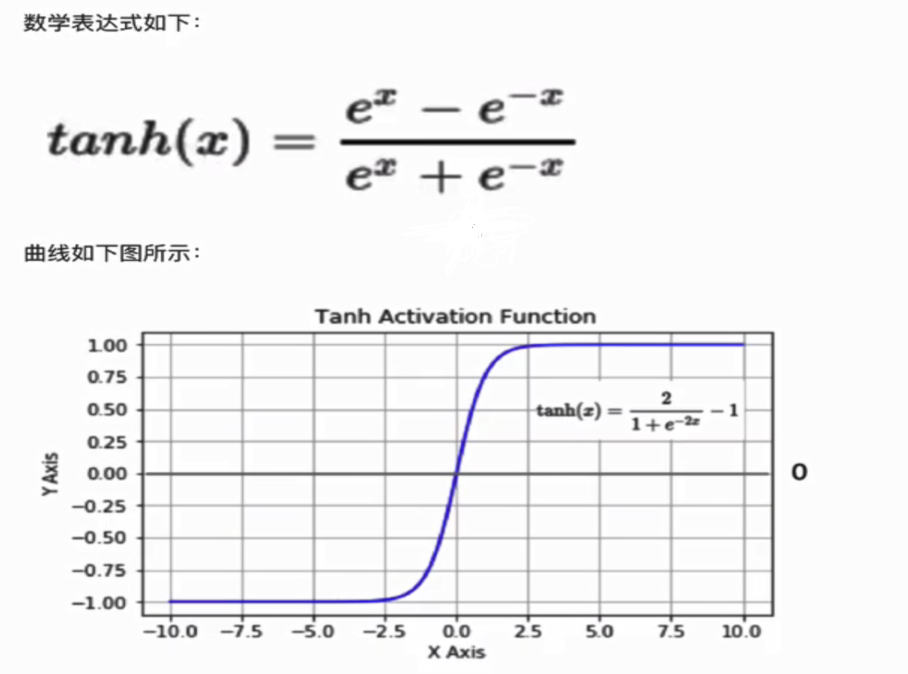
2.tanh(双曲正切曲线)
tanh也是一种非常常见的激活函数。与sigmoid相比,它是以0为中心的,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从图中可以看出,tanh两侧的导数也为0,同样会造成梯度消失。
若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数。
代码实现:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-15, 15, 100)
# 直接使用tensorflow实现
y = tf.nn.tanh(x)
# 绘图
plt.plot(x, y)
# 添加网格
plt.grid()
plt.show()
运行结果:
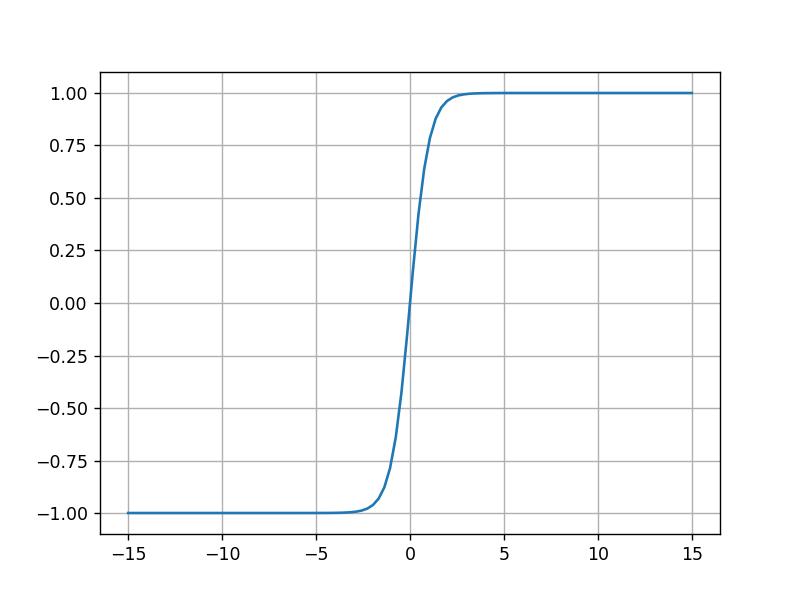
3.RELU
ReLU是目前最常用的激活函数。从图中可以看到,当x<0时,ReLU导数为0,而当x>0时,则不存在饱和问题。所以,ReLU能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象称为“神经元死亡”,它的好处是降低网络复杂度,缓解过拟合。
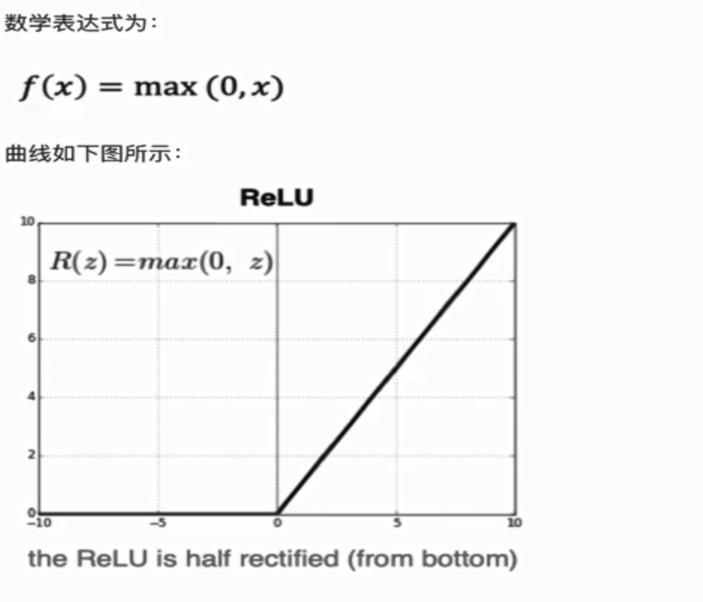
与sigmoid相比,RELU优势是:
- 采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
- sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
代码实现:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-15, 15, 100)
# 直接使用tensorflow实现
y = tf.nn.relu(x)
# 绘图
plt.plot(x, y)
# 添加网格
plt.grid()
plt.show()
运行结果:
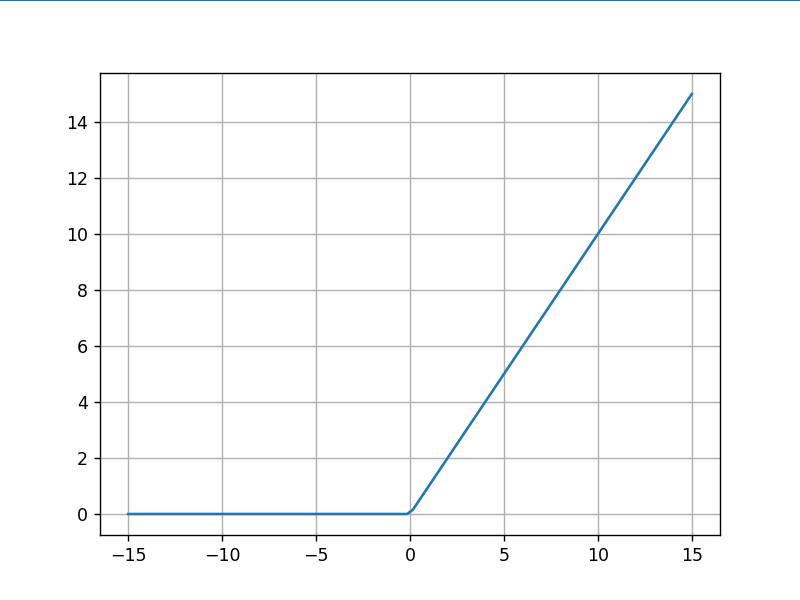
4.LeakReLu
该激活函数是对RELU的改进,数学表达式为:
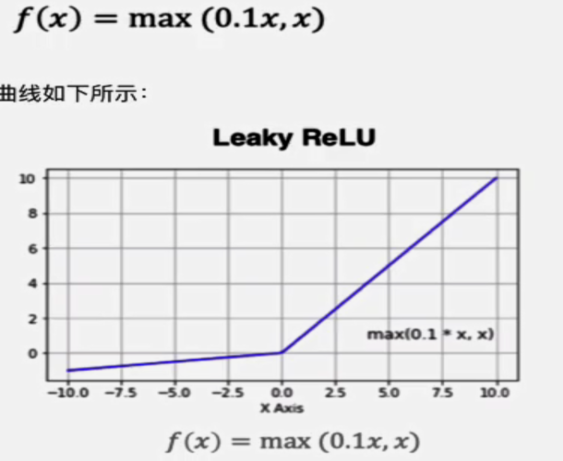
代码实现:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
# 定义x的取值范围
x = np.linspace(-15, 15, 100)
# 直接使用tensorflow实现
y = tf.nn.leaky_relu(x)
# 绘图
plt.plot(x, y)
# 添加网格
plt.grid()
plt.show()
运行结果:
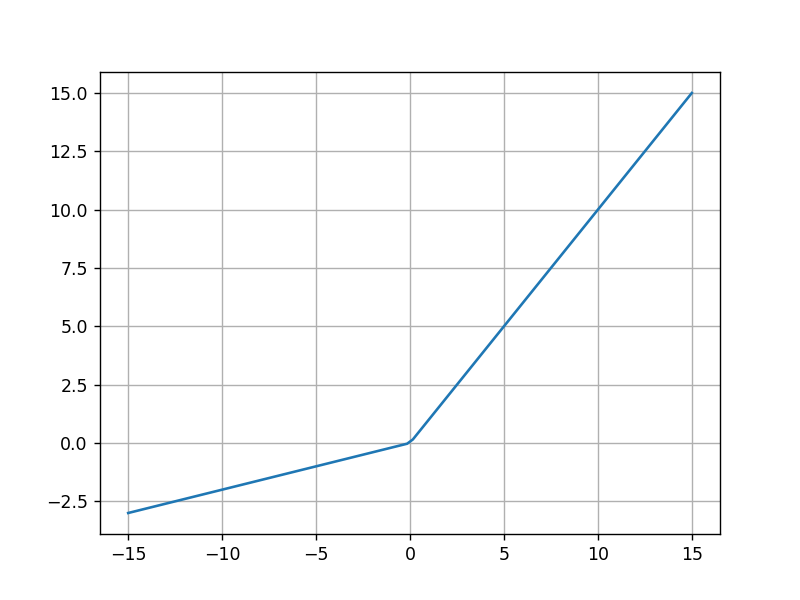
5.SoftMax
用于多分类输出层,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。

代码实现:
import tensorflow as tf
# 数字中的score
x = tf.constant([0.2, 0.02, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
# 送到softmax中计算分类结果
y = tf.nn.softmax(x)
print(y)
运行结果:

6.其他激活函数
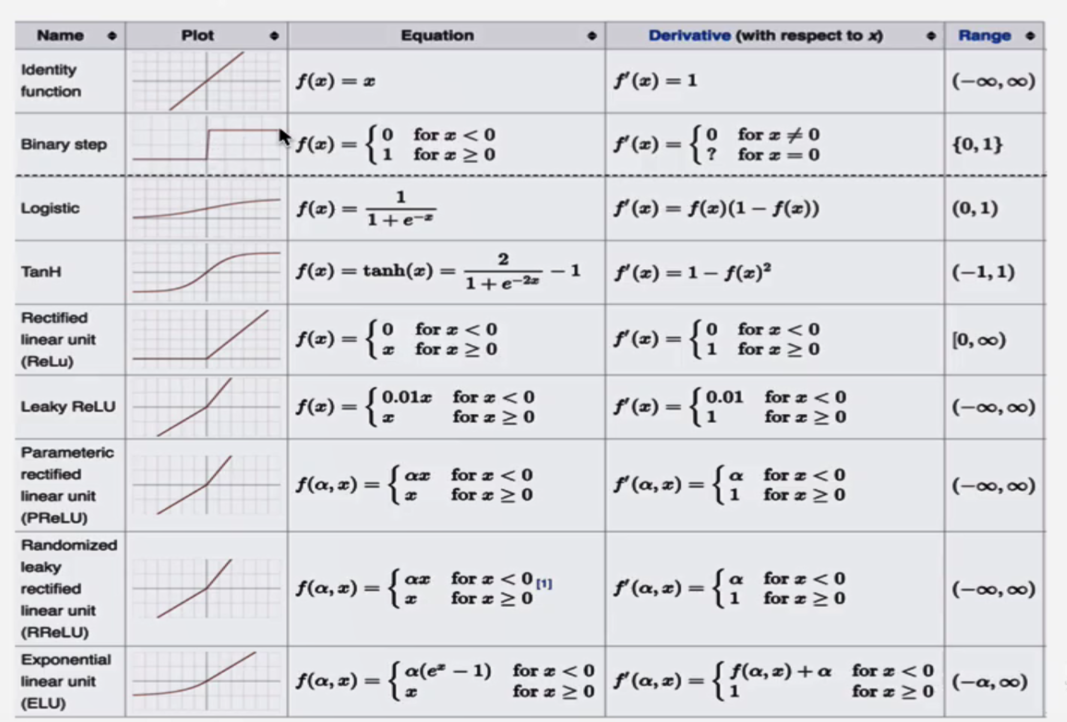
7.如何选择激活函数
隐藏层
- 优先选择RELU激活函数
- 如果Relu效果不好,那么尝试其他激活函数,如Leaky Relu等
- 如果使用Relu,需要注意下Dead Relu问题,避免出现大的梯度从而导致过多的神经元死亡。
- 不要使用sigmoid激活函数,可以尝试tanh激活函数
输出层
- 二分类问题选择
sigmoid激活函数 - 多分类问题选择
softmax激活函数 - 回归问题选择
identity激活函数
三.参数初始化
1.参数初始化介绍
对于某一个神经元来说,需要初始化的参数有两类:一类是偏置bias,直接初始化为0。还有一类是权重weight。而权重weight的初始化比较重要,接下来着重介绍。
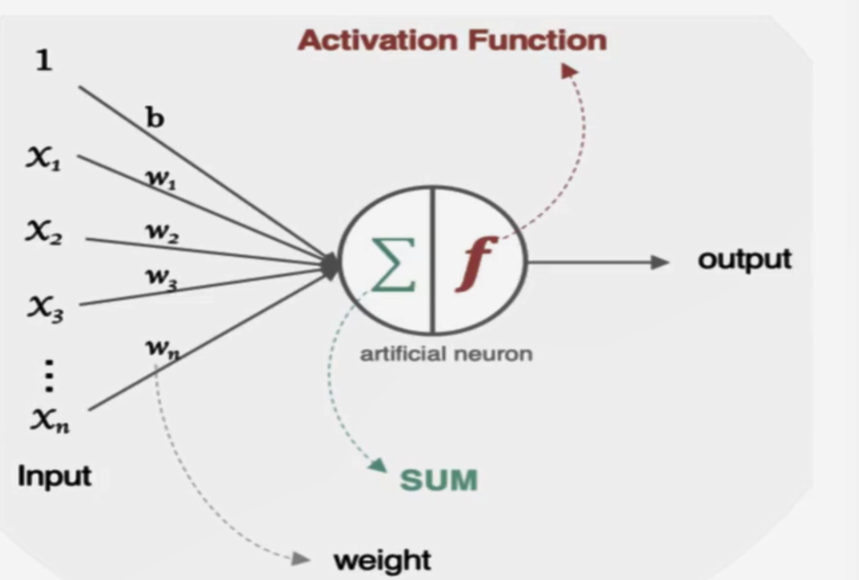
2.随机初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化。
3.标准初始化
权重参数初始化从区间均匀随机取值。
4.Xavier初始化
该方法的基本思想是各层的激活值和梯度的方差在传播过程中保持一致,也叫做Glorot初始化。在tf.keras中实现的方法有两种:
- 正态化Xavier初始化:
Glorot正态分布初始化器,也称为Xavier正态分布初始化器。它从以0为中心,标准差为stddev = sqrt(2/(fan_in + fan_out)) 的正态分布中抽取样本,其中fan_in 是输入神经元的个数,fan_out是输出的神经元个数。
实现方法:
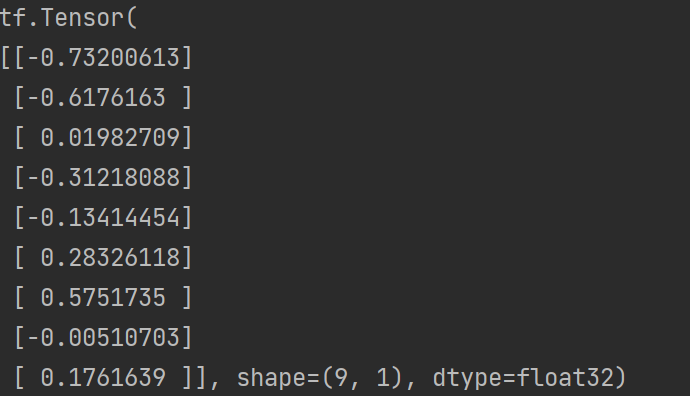
import tensorflow as tf
# 进行实例化
initializer = tf.keras.initializers.glorot_normal()
# 采样得到权重值 9行1列
values = initializer(shape=(9, 1))
print(values)
输出结果:
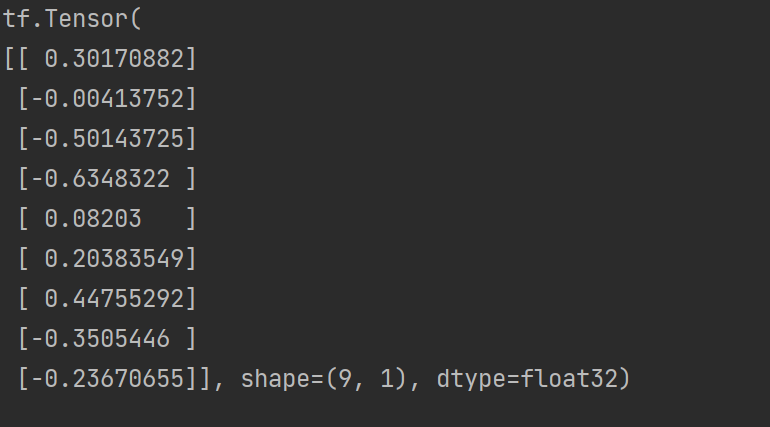
- 标准化Xavier初始化
Glorot均匀分布初始化器,也称为Xavier均匀分布初始化器。它从[-limit,limit]中的均匀分布中抽取样本,其中limit是sqrt(6 / (fan_in+ fan_out)),其中fan_in是输入神经元的个数,fan_out是输出的神经元个数。
实现方法:
import tensorflow as tf
# 进行实例化
initializer = tf.keras.initializers.glorot_uniform()
# 采样得到权重值 9行1列
values = initializer(shape=(9, 1))
print(values)
输出结果:
5.He初始化
he初始化,也称为Kaiming初始化,出自大神何恺明之手,基本思想是正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。在tf.keras中有两种:
- 正态化的he初始化
He正态分布初始化是以0为中心,标准差为stddev = sqrt(2 / fan_in) 的截断正态分布中抽取样本,其中fan_in 是输入神经元的个数,在tf.keras中实现方法为:
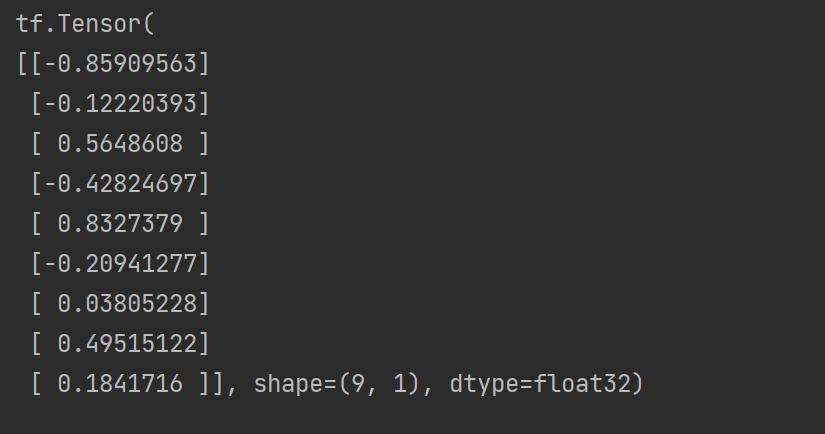
import tensorflow as tf
# 进行实例化
initializer = tf.keras.initializers.he_normal()
# 采样得到权重值 9行1列
values = initializer(shape=(9, 1))
print(values)
输出结果:
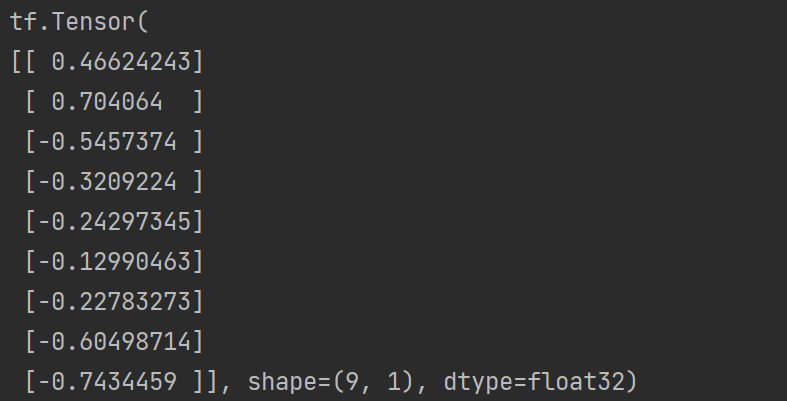
- 标准化的he初始化
He均匀方差缩放初始化器。它从[-limit,limit]中的均匀分布中抽取样本,其中limit是sqrt(6 / fan_in),其中fan_in输入神经元的个数。
实现方法:
import tensorflow as tf
# 进行实例化
initializer = tf.keras.initializers.he_uniform()
# 采样得到权重值 9行1列
values = initializer(shape=(9, 1))
print(values)
输出结果:
四.神经网络的搭建
1.构建方式介绍
tf.keras中构建有三种方式,一种是通过Sequential构建,一种是通过利用function API构建,还有一种是通过Model的子类构建。前者是按一定的顺序对层进行堆叠,而后者可以用来构建较复杂的网络模型。首先我们介绍下用来构建网络的全链接层:
tf.keras.layers.Dense(
# 当前层中包含的神经元个数
units=3,
# 激活函数,relu、sigmoid等
activation=None,
# 是否使用偏置,默认使用偏置
use_bias=True,
# 权重的初始化方式,默认是Xavier初始化
kernel_initializer='glorot_uniform',
# 偏执的初始化方式,默认为0
bias_initalizer='zeros')
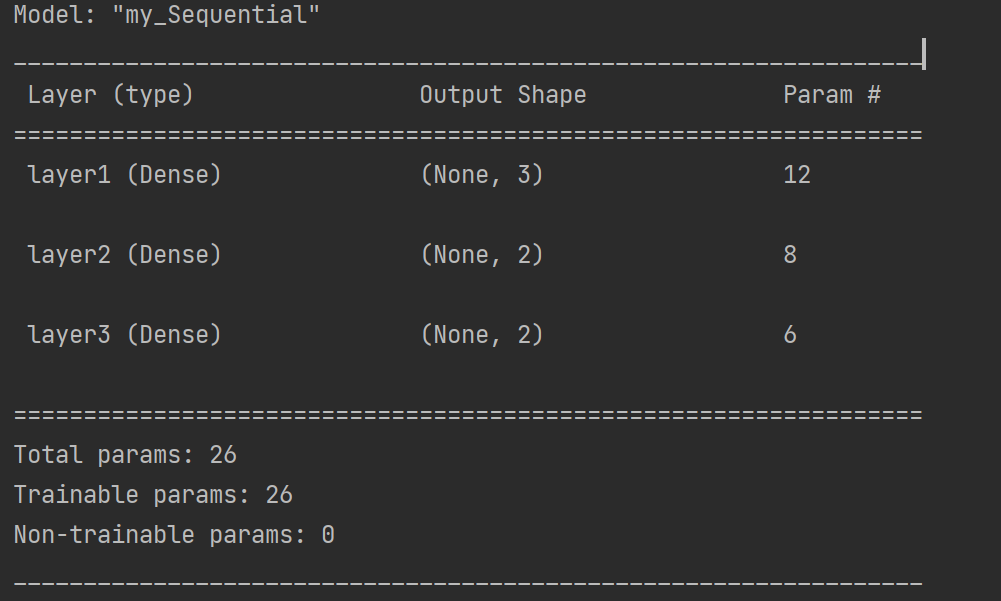
2.通过Sequential构建(重点)
Sequential()提供了一个层的列表,能快速地建立一个神经网络模型。通过sequential的方式只能构建简单的单输入、单输出网络模型,较复杂的模型没有办法实现。实现方法如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 定义一个Sequential模型,包含3层
model = keras.Sequential(
[
# 第一个隐层:激活函数为relu,权重初始化为he_normal
layers.Dense(3, activation="relu",kernel_initializer="he_normal", name="layer1", input_shape=(3, )),
# 第二个隐层:激活函数为relu,权重初始化为he_normal
layers.Dense(2, activation="relu",kernel_initializer="he_normal", name="layer2"),
# 第三层(输出层):激活函数为sigmoid,权重初始化为he_normal
layers.Dense(2, activation="sigmoid",kernel_initializer="he_normal", name="layer3"),
],
name="my_Sequential"
)
# 展示模型结果
model.summary()
运行结果:
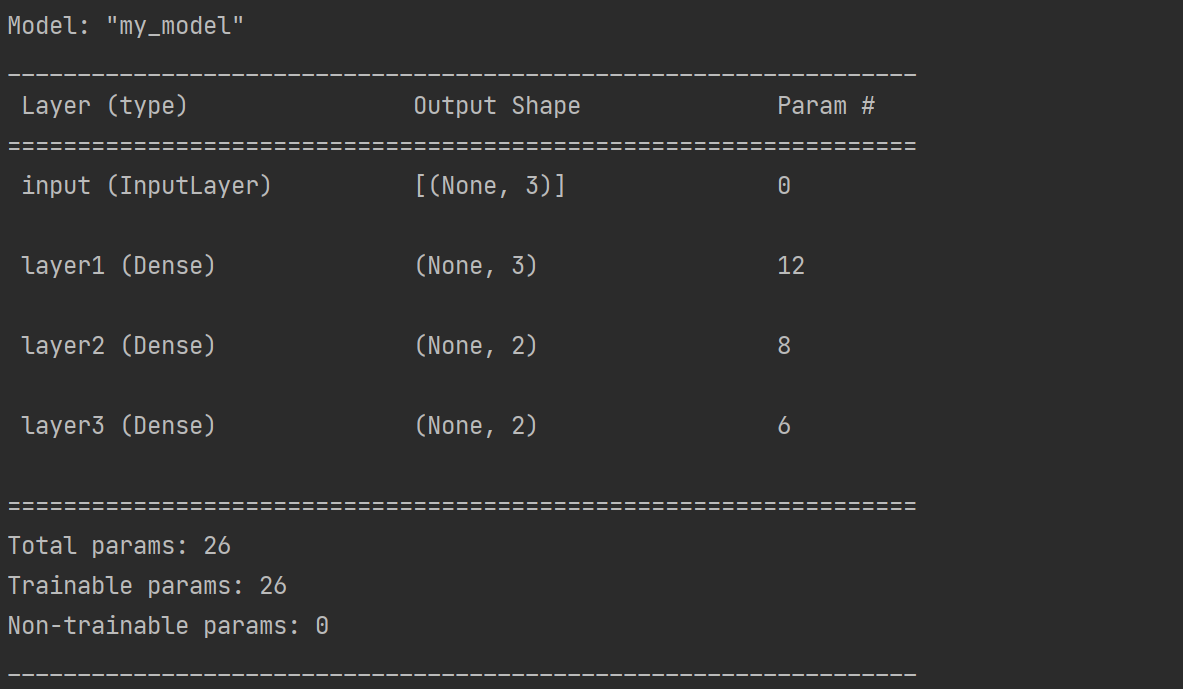
3.利用function API构建(实践中常用)
tf.keras提供了Function API,建立更为复杂的模型,使用方法是将层作为可调用的对象并返回张量,并将输入向量和输出向量提供给tf.keras.Model的inputs 和outputs 参数,实现方法如下:
import tensorflow as tf
from tensorflow.python.keras.utils.vis_utils import plot_model
# 定义模型的输入
inputs = tf.keras.Input(shape=(3,), name="input")
# 第一层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(3, activation="relu", name="layer1")(inputs)
# 第二层:激活函数为relu,其他默认
x = tf.keras.layers.Dense(2, activation="relu", name="layer2")(x)
# 第三层(输出层):激活函数为sigmoid
outputs = tf.keras.layers.Dense(2, activation="sigmoid", name="layer3")(x)
# 使用Model来创建模型,指明输入和输出
model = tf.keras.Model(inputs=inputs, outputs=outputs, name="my_model")
# 展示模型结果
model.summary()
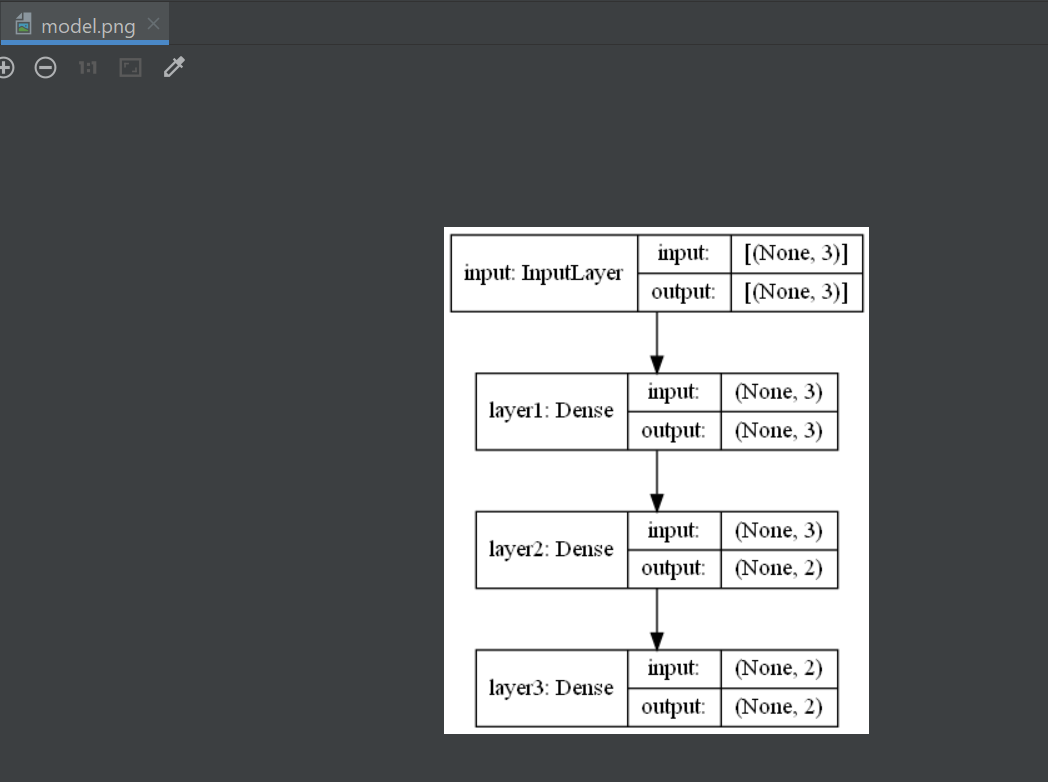
plot_model(model, to_file='model.png', show_shapes=True)
运行结果:
plot_model是 keras 中提供了一个神经网络可视化的函数,并可以将可视化结果保存在本地。
4.通过model的子类构建(与Pytorch中是类似的)
通过model的子类构建模型,此时需要在__init__中定义神经网络的层,在call方法中定义网络的前向传播过程,实现方法如下:
import tensorflow as tf
# 定义model的子类
class MyModel(tf.keras.Model):
# 在init方法中定义网络的层结构
def __init__(self):
super(MyModel, self).__init__()
# 第一层: 激活函数为relu,权重初始化为he_normal
self.layer1 = tf.keras.layers.Dense(3, activation="relu", kernel_initializer="he_normal", name="layer1",
input_shape=(3,))
# 第二层:激活函数为relu,权重初始化为he_normal
self.layer2 = tf.keras.layers.Dense(2, activation="relu", kernel_initializer="he_normal", name="layer2")
# 第三层(输出层):激活函数为sigmoid,权重初始化为he_normal
self.layer3 = tf.keras.layers.Dense(2, activation="sigmoid", kernel_initializer="he_normal", name="layer3")
# 在call方法中完成前向传播
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
outputs = self.layer3(x)
return outputs
# 实例化模型
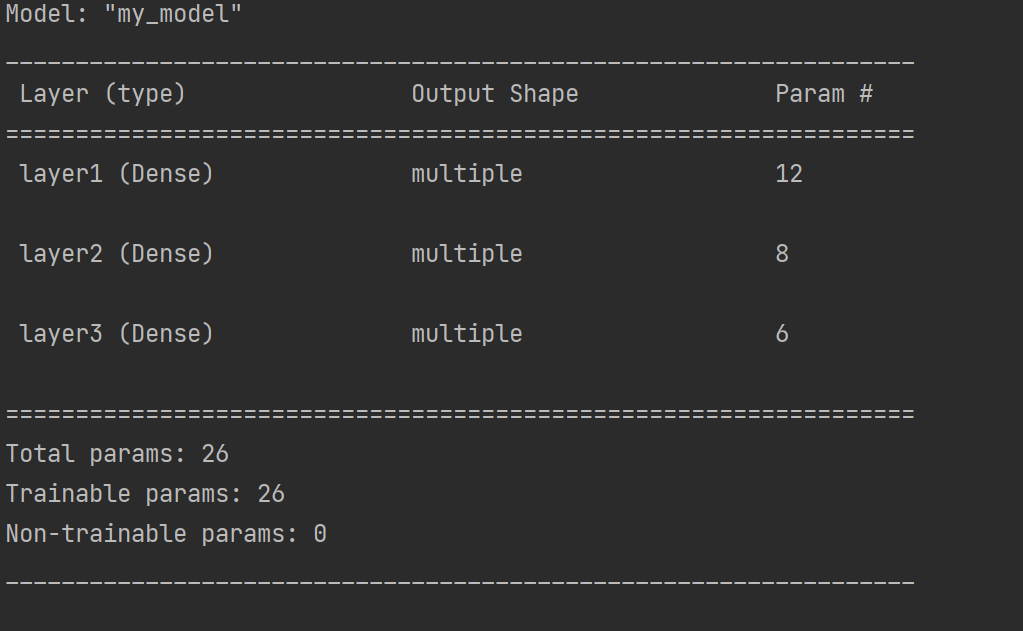
model = MyModel()
# 设置一个输入,调用模型(否则无法使用summay)
x = tf.ones((1, 3))
y = model(x)
# 展示模型结果
model.summary()
运行结果:
五.神经网络的优缺点
1.优点
- 精度高,性能优于其他的机器学习方法,甚至在某些领域超过了人类
- 可以拟合任意的非线性函数
- 随者计算机硬件发展,近年来在学界和业界受到了热捧,有大量的框架和库可供调用
2.缺点
- 黑箱,很难解释模型是怎么工作的
- 训练时间长,需要大量计算力
- 网络结构复杂,需要调整超参数
- 小数据集上表现不佳,容易发生过拟合