
全文字数1303,预计阅读5min
1.什么是DL Workbench
DL Workbench是可视化的OpenVINO模型性能评估工具,用户可以在web界面下选择已有的英特尔硬件设备进行模型评估。这个工具包含了下载深度学习模型、定制和生成推理所需数据集、优化模型、校准模型、调整和比较模型的性能,从而找到最符合工程实践的模型进行部署和使用。
2.DL Workbench支持哪些设备
DL Workbench支持基于Intel CPU、GPU、NCS2和具有英特尔VPU架构的视觉加速设备HDDL。需要注意的是由于MYRIAD和HDDL设备不兼容,因此不能在DL Workbench中一起使用,故不能同时设置。
3.DL Workbench可以做哪些事情
-
可以从Open Model Zoo下载具有预训练模型的模型,用于各种不同任务
-
使用模型优化器来优化模型,转换为中间表示(IR)格式
-
可以定制和生成推理所需数据集
-
训练后优化工具包,用于校准模型,然后以INT8精度执行
-
准确性检查器,以确定模型的准确性
4.DL Workbench安装
Workbench有两种安装方式:
- 从Docker Hub安装DL Workbench(包括在Linux,Windows和macOS上安装)
https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Run_Locally.html
- 从OpenVINO工具包软件包中安装DL Workbench。参见链接:https://docs.openvinotoolkit.org/latest/workbench_docs_Workbench_DG_Install_from_Package.html
这里我们使用从Docker Hub安装的方式。在机器上安装完docker后,在页面选择配置:
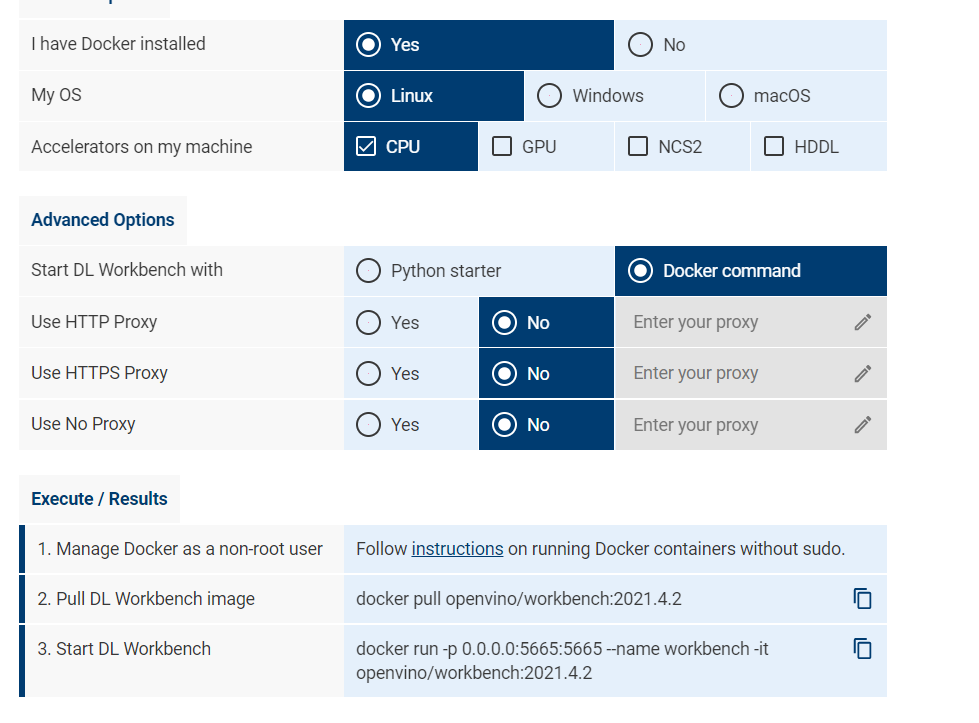
Pull DL Workbench image
docker pull openvino/workbench:2021.4.2
Start DL Workbench
docker run -p 0.0.0.0:5665:5665 --name workbench -it openvino/workbench:2021.4.2
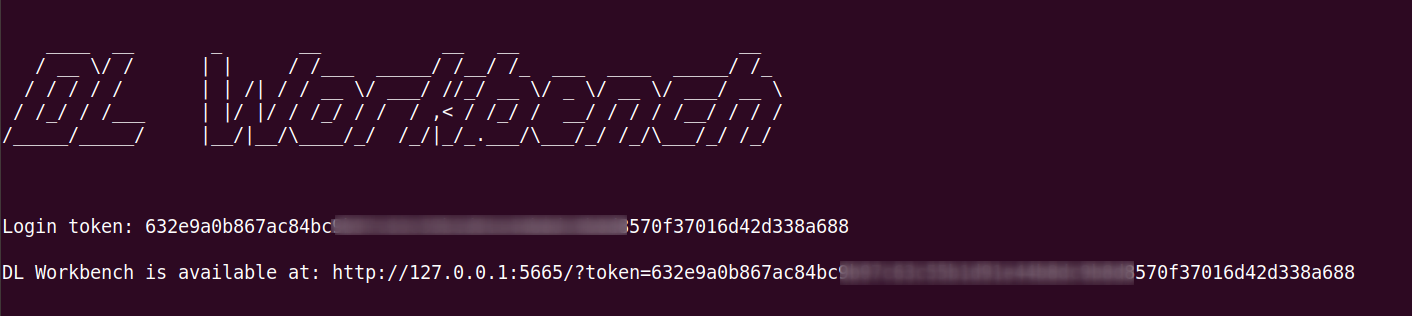
执行成功的显示如下图,这时会启动一个本地服务器。
5.如何使用DL Workbench进行推理
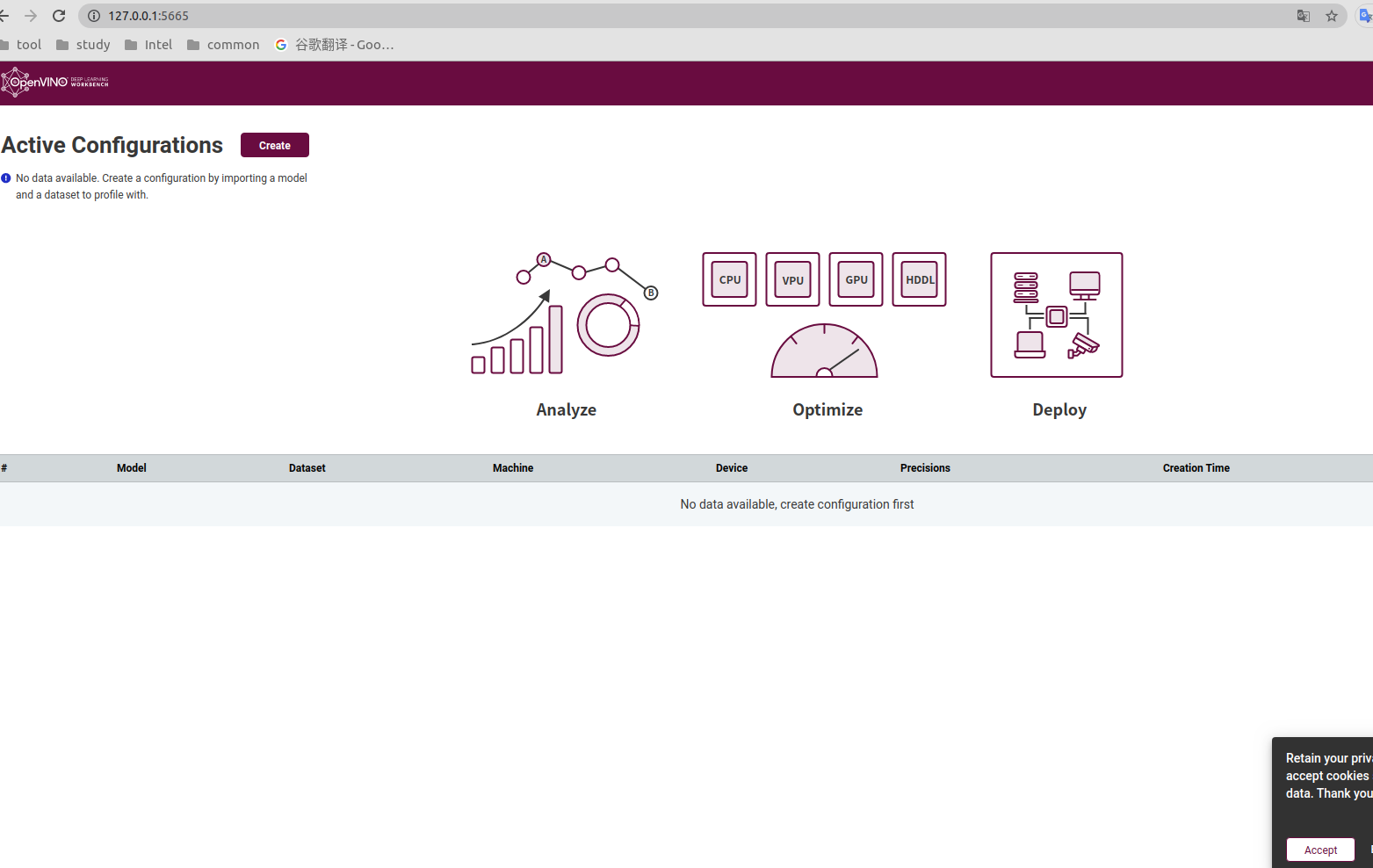
粘贴本地服务器的link到浏览器并打开Workbench的Web界面,首页显示如下图
点击 create 创建配置,将打开Create Configuration页面。
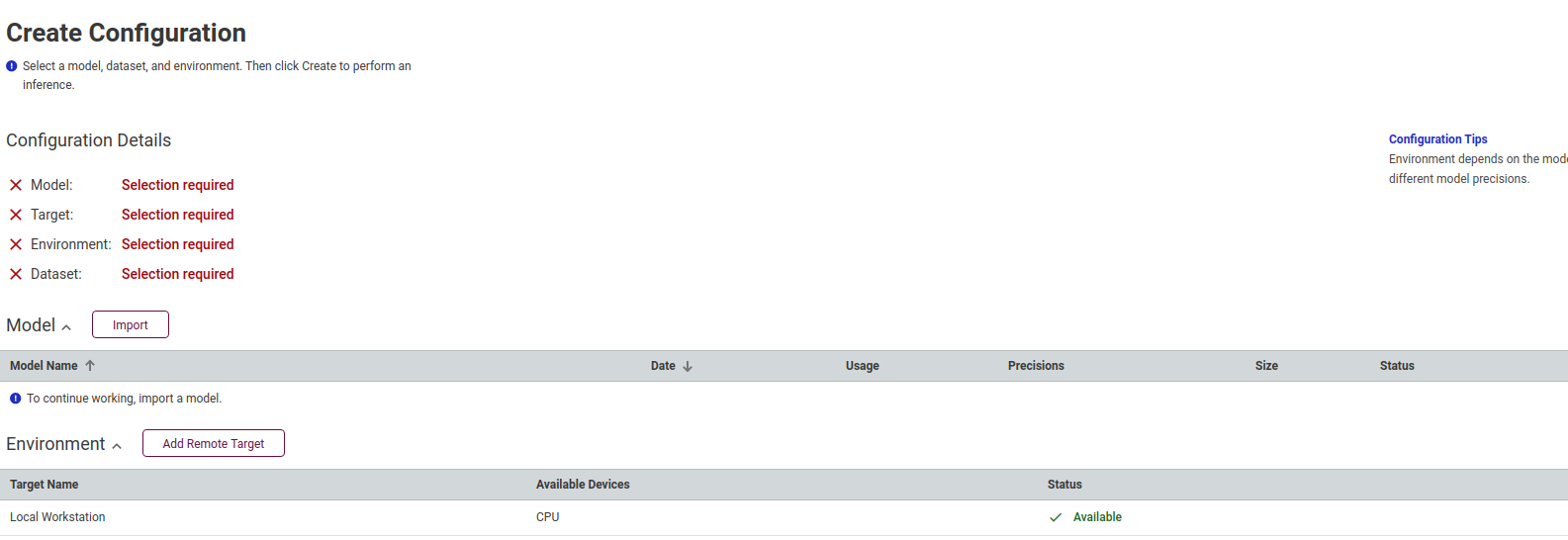
导入模型,可以从Open Model Zoo选择在线模型,也可以在Original Model中选择本地模型,这里我们使用在线模型
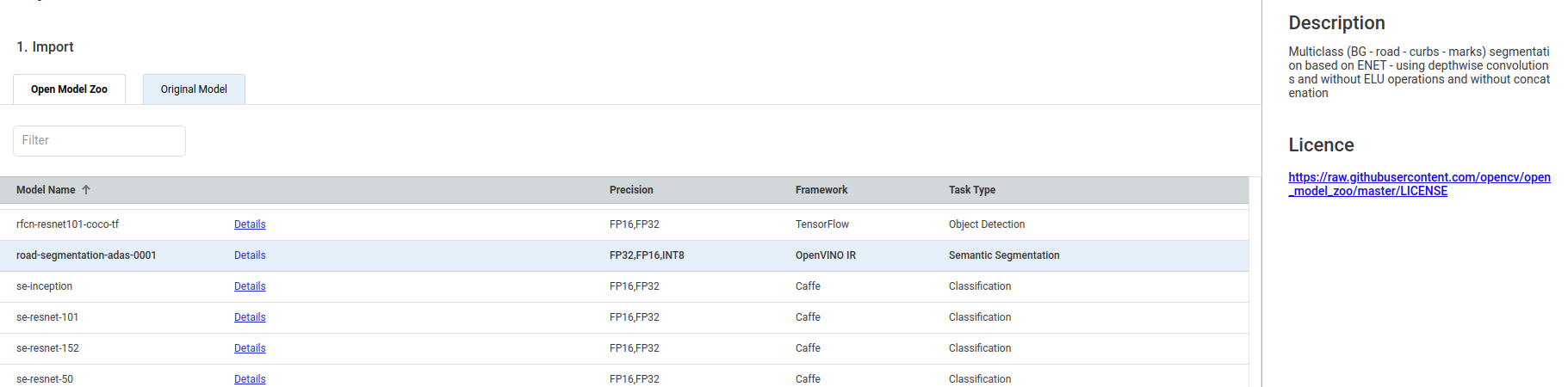
把选中的模型粘贴到框内,设置好数据格式,点击Import and Download按钮下载模型
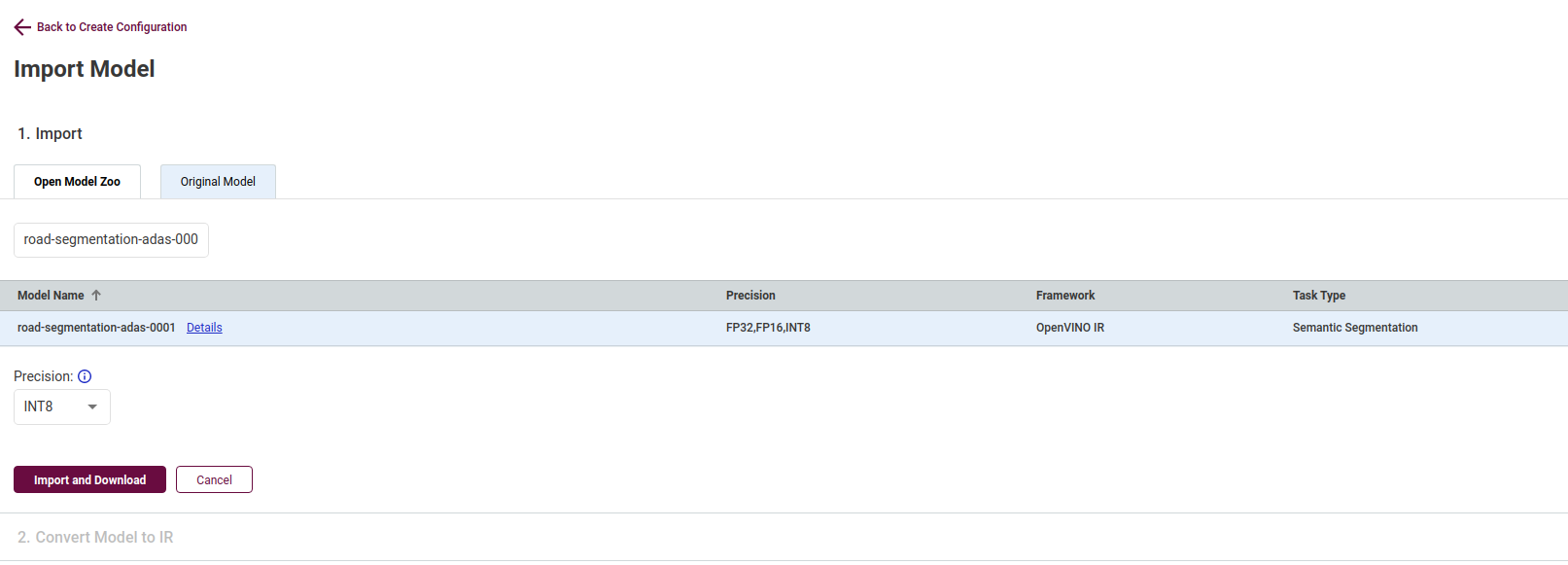
下载完成后双击将该模型添加到配置中,并配置工作台为当地工作台,运行环境为cpu,以及导入的数据集,完成后会看到页面左上角的全部配置参数。
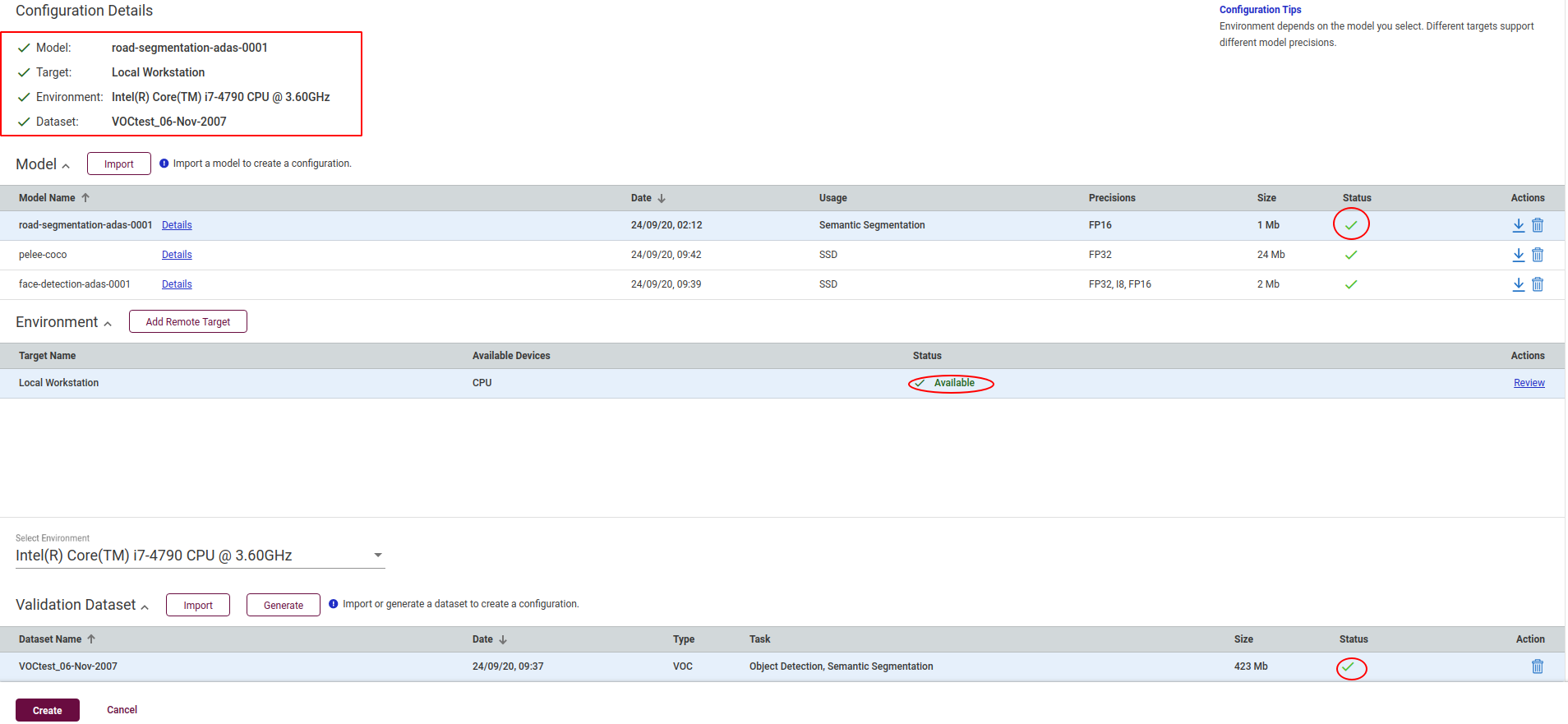
点击页面的create按钮,运行基准推理,等待性能数据的收集完成。
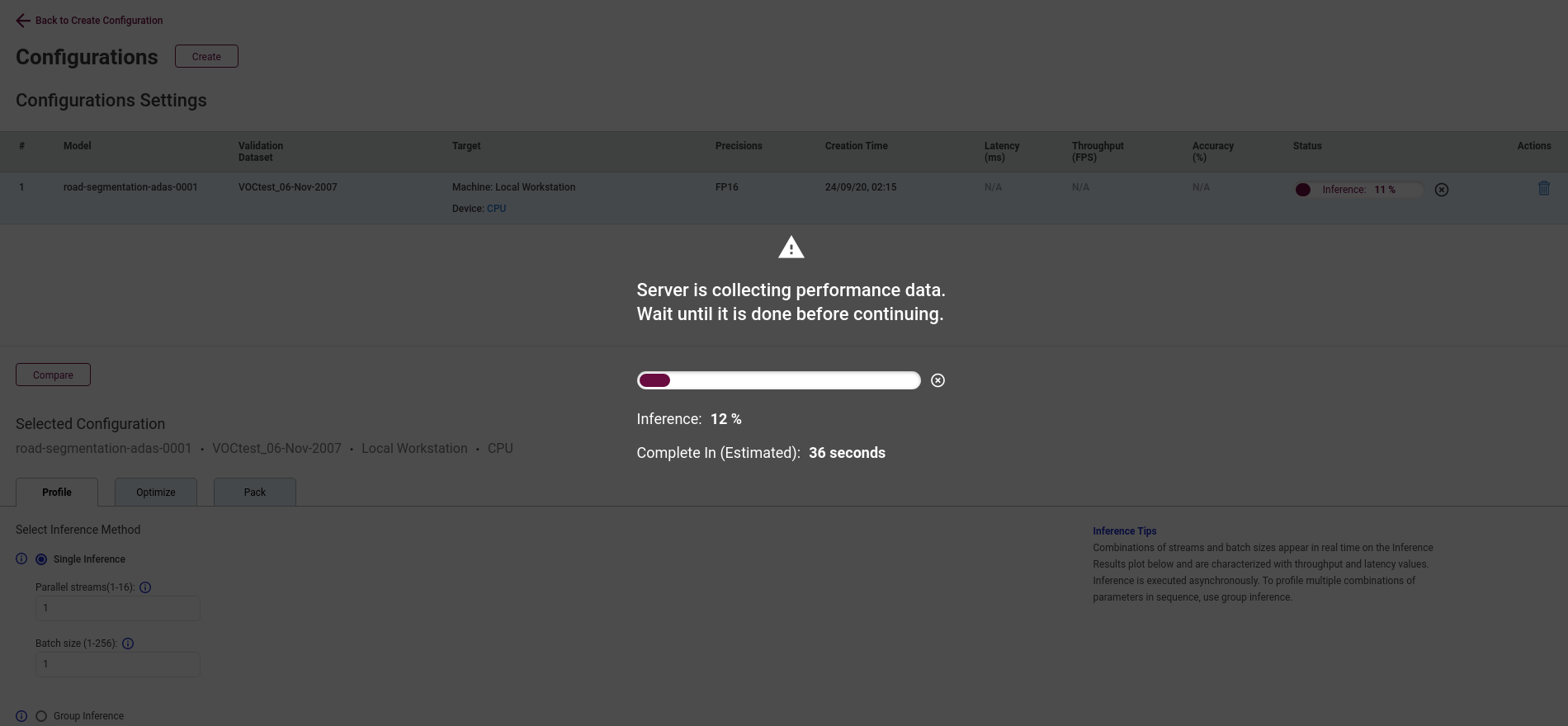
推理完成后会跳转到配置页面,会显示两大部分内容:配置设置表和模型性能摘要。
我们可以在配置设置表中查看推理结果的状态,以及吞吐量、延迟等参数信息,还可以下载该模型或者删除它。点击Details还能够查看模型参数的输入输出等信息。

也可以在模型性能摘要中查看推断结果、逐层执行时间、执行属性和层数表等详细参数信息。
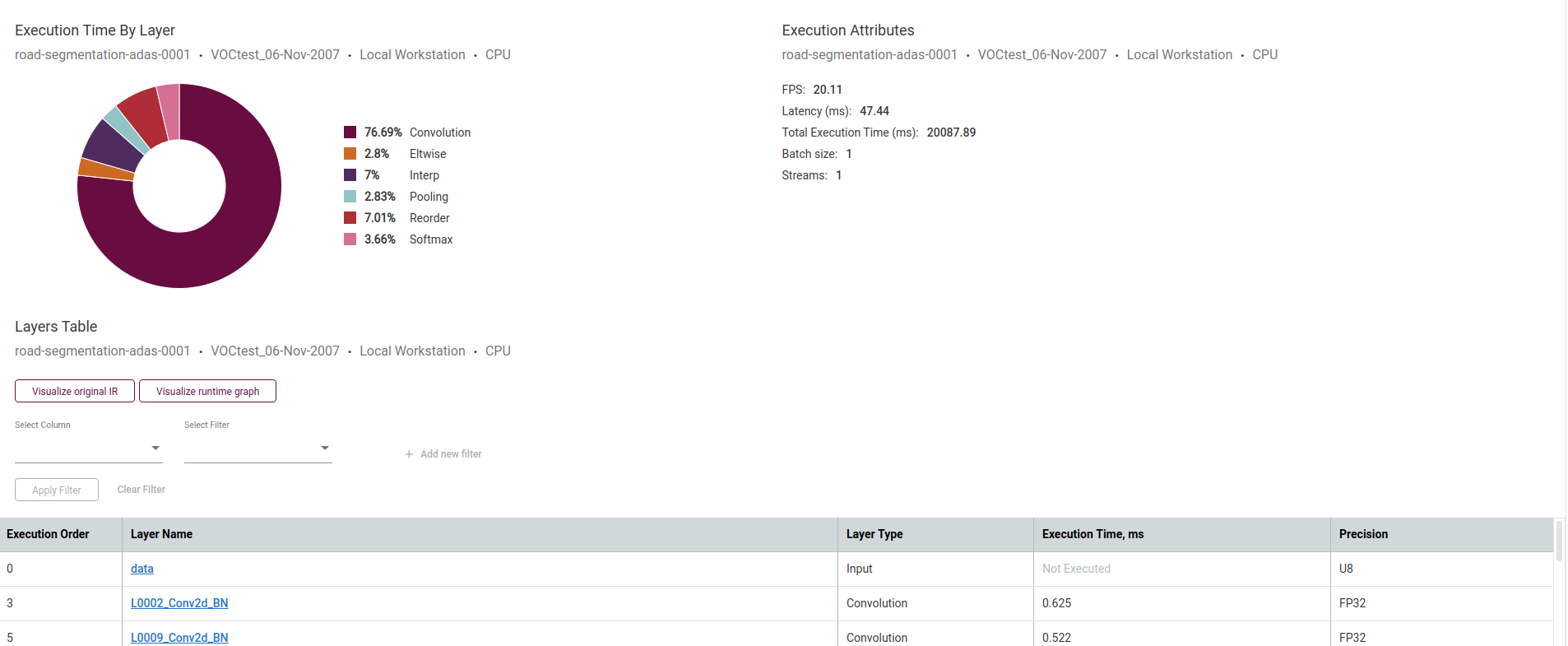
6.如何下载模型
在配置表中点击右侧的下载按钮,即可下载转换后的模型文件。

7.如何通过调整参数比较模型的性能差异
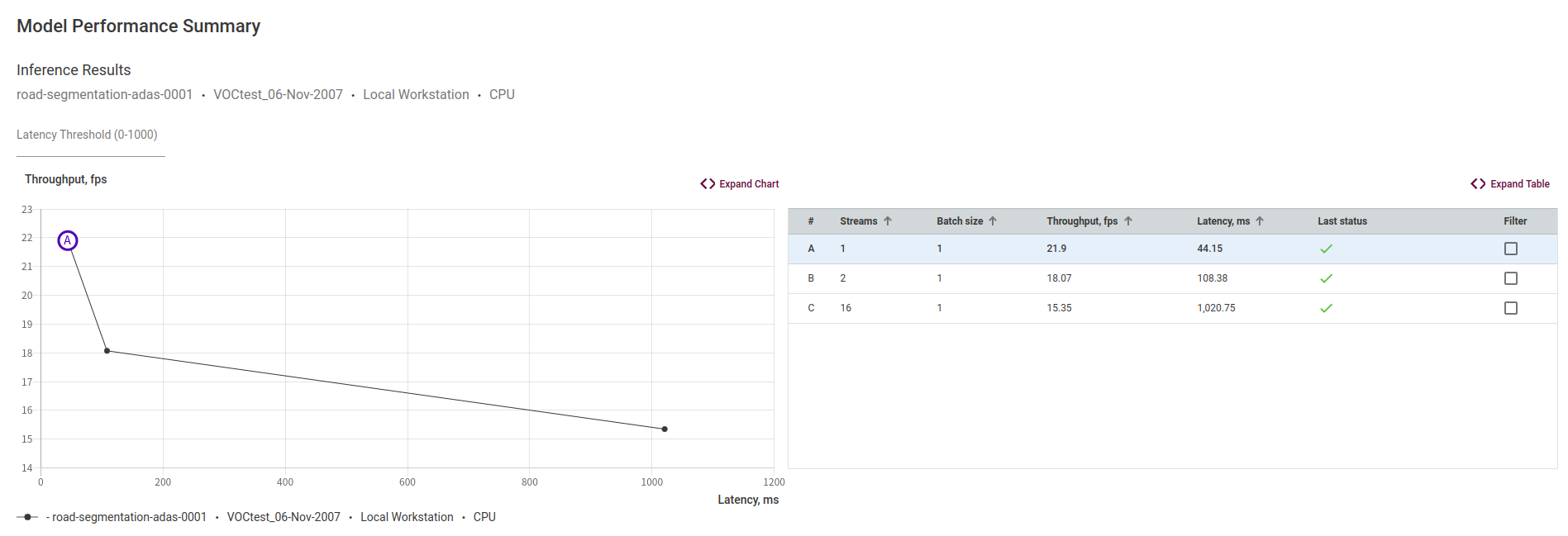
在配置表的所选配置中,我们可以选择单一流推理模式或组推理模式来比较模型的性能差异

这里我们选择单一流推理模式,批量大小保持不变,分别两次修改流处理单元数为2和16进行推理,可以发现不同的流处理单元下,模型的性能会有不同的表现。
8.如何对模型进行转换和优化
在配置表的所选配置中,我们可以通过降低计算精度来提高模型的性能,比如把FP32转换为INT8格式。
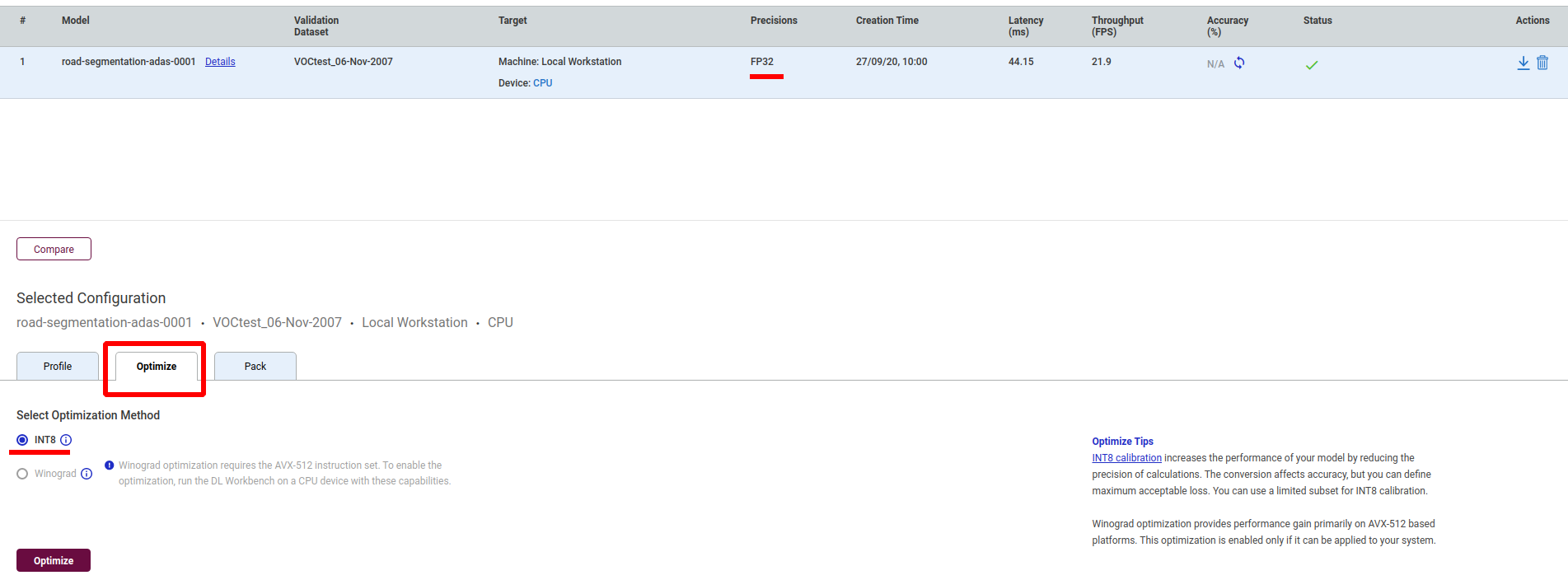
模型的优化的方式有两种:
默认方式和AccuracyAware方式。
默认方式又叫最大性能校准,可优化模型以获得最佳性能。适用于注释或未注释的数据集,是不可控制的模型精度下降,将支持INT8执行的所有层都转换为INT8精度。
AccuracyAware方式又叫最大精度校准,它指的是达到指定的最大可接受精度下降值时的最佳性能。只适用于带注释的数据集,是可控制的模型精度下降,仅转换了能够以INT8精度执行并且几乎不增加精度下降的那些层。
下图可以看到使用不同的优化方式对模型性能的影响

9.生成最小部署包
点击选择配置中的包下载,可以自定义最小部署包想要支持的设备类型、是否包括转换后的模型文件、python API、安装脚本等等。默认的最小部署包中不包含模型,仅包含所选的插件库。这里我们勾选模型文件、python API和安装脚本,生成最小部署包。
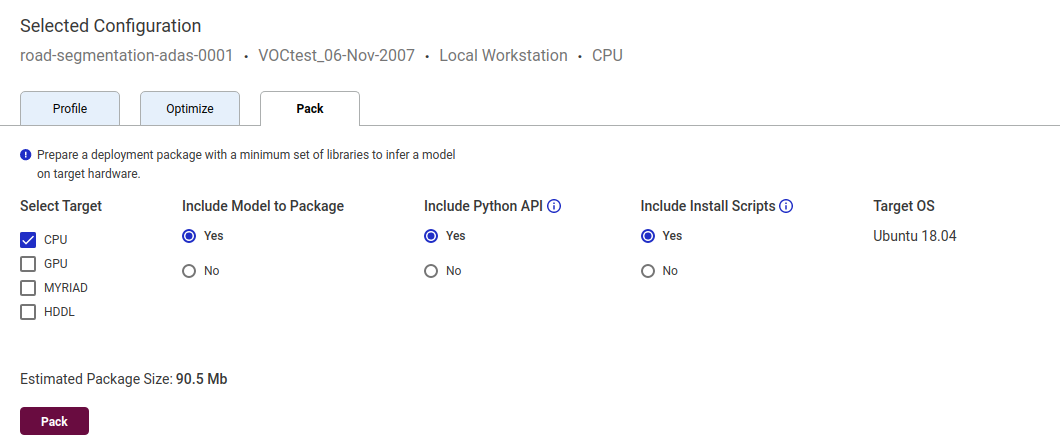
下载完成后可以看到生成的最小部署包中包含了我们勾选的内容。
10.DL_Workbench镜像的保存和导入
-
如果有在别的设备或者网络不佳的时候运行DL_Workbench的需求,下次使用的时候不必再次下载,节省时间,那么执行下面命令即可保存。
docker save -o /media/kang/openvino-workbench.tar openvino/workbench:latest -
当我们想从本地导入镜像,来运行DL_Workbench,只要系统安装好docker即可使用下面命令导入镜像包。
docker load --input /media/kang/workbench/openvino-workbench.tar -
启动服务:
./start_workbench.sh -IMAGE_NAME openvino/workbench