
1.推理引擎介绍:
我们需要使用一个预先训练好的模型,并将其准备好给推理使用,推理引擎的起点是IR文件。推理引擎其实是一个可以整合到自己应用程序中的API,这个API适用于所有的硬件设备,在C++和python中提供了API。
模型优化器先处理原始模型,然后把基元数据或者图层映射到所支持的操作中,这一过程就构建了IR文件。在不同的设备上实施每个操作,其过程都将有所不同。我们以乘法为例,同一个操作,在CPU实施时,使用的语言是C、C++或者汇编语言,但是同样的函数在GPU上实施时,则将使用OpenCL语言编写。因此,推理引擎对于每个所支持的设备都有不同的插件,CPU插件使用MKL-DNN库(数学核心函数库),GPU插件使用clDNN库(深度神经网络计算库)。对于开发者而言,只需要指定目标设备,推理引擎就可以使用正确的插件,并在目标硬件上进行推理运行。
推理引擎是一种运行时,可提供统一的API来将推理与应用程序逻辑集成在一起:作为输入模型。该模型以Model Optimizer产生的特定形式的中间表示(IR)表示。优化目标硬件的推理执行。在嵌入式推理平台上提供减少占用空间的推理解决方案。推理引擎支持多种图像分类网络的推理,包括AlexNet,GoogLeNet,VGG和ResNet系列网络,用于图像分割的完全卷积网络(如FCN8)以及对象检测网络(如Faster R-CNN)。
针对特定执行设备对模型进行优化,这些设备具有完全不同的指令集,有的还有不同的内存、布局等。每个设备或者设备系列都有自己的实现方案。例如cpu插件负责在凌动、酷睿、至强系列的芯片执行Inference Engine。每个插件都有自己的实现库,例如cpu插件使用MKL-DNN库,MKL-DNN库会针对所有的intel cpu对应的内核、层或函数实施神经网络的优化,如果该库不支持你的层,你可以构建一个自定义层,并将其注册到推理引擎。
2.推理流程如下图:
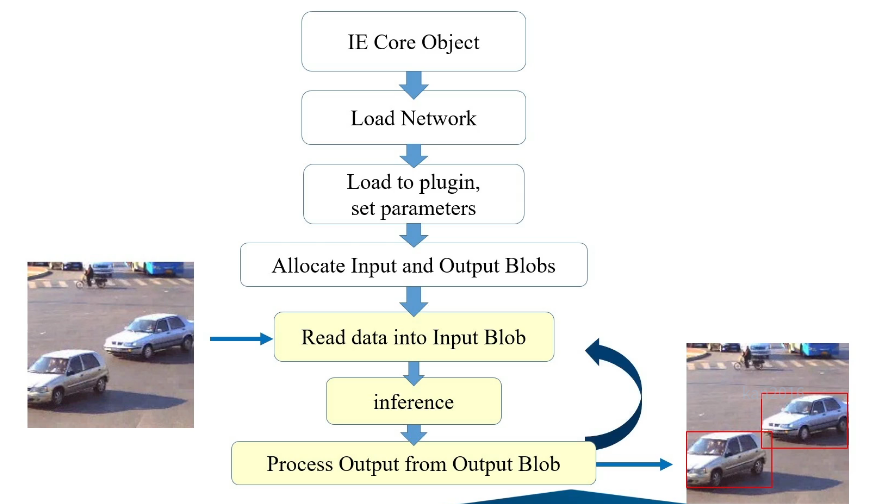
3.推理引擎是怎么优化的:
1.网络级优化,不映射到内核,而是映射到他们之间的关系。例如数据的重组,这可以提高性能,并在推理过程中最大程度的减少数据转换时间
2.内存级优化,内存中按照特定的设备的要求重组数据
3.内核级优化,推理引擎选择最适合架构指令集的正确实施方案。 此外还有两个特殊插件,HETERO和MULTI。可以通过这两个特殊插件访问所有的设备。
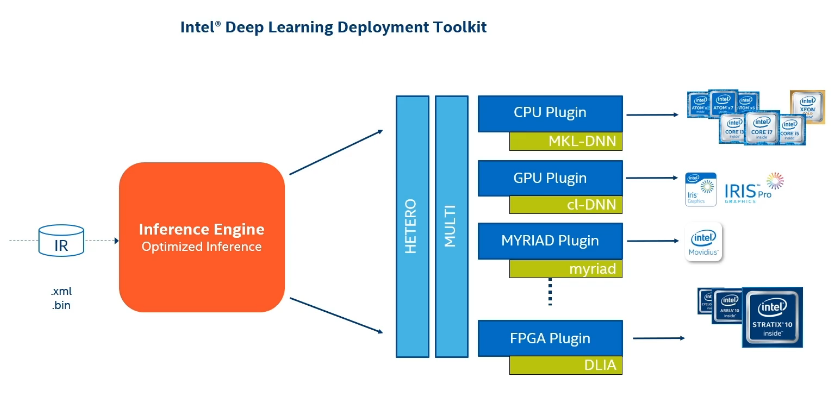
4.Inference Engine API
Inference Engine API是在所有Intel架构的硬件中实施推理的一套简单而且统一的API,正如我们所解释的,特殊的插件架构支持优化推理性能和内存使用,该API非常简单,同时具有足够的灵活性来支持所需的一切。主要使用c++实施,相对使用同样提供的python接口会快很多。
- IECore:
是Inference Engine的主要类,运行在各种不同插件的上层,并向开发者提供相同的功能。可以创建一个Core类的对象,并只有加载网络时指定设备,实际运行才会使用该设备,无需专门注册特定插件。
- InferRequest:
然后使用InferRequest进行推理
- HETERO plugin:
HETERO plugin支持在不同设备上运行不受支持的特定层。有时候目标设备不支持所有的层,HETERO plugin可以将不支持层的执行回退到其他设备。 例如: exex_net = my_ie.load_network(network=net,device_name=’HETERO:FPGA,CPU’) 表示尝试在FPGA上运行所有层,如果找不到任何层的实施方案,就在CPU设备运行相应层。
- MULTI plugin:
当程序运行时生成许多推理请求,例如在视频上运行推理,每帧都具有不同的推理调用,甚至一帧中有几个推理的调用。因此,MULTI plugin可以让你在不同的设备上运行几个推理调用,从而利用系统中的所有设备。 例如: exex_net = my_ie.load_network(network=net,device_name=’MULTI:MYRIAD,CPU’) 所有推理请求发送到MYRIAD,但是当MYRIAD充分利用时,后续的推理请求将发送到CPU,这样MYRIAD和CPU并行执行推理,并且可以提供更好的性能,该插件支持我们根据设备的实时可有性来使用他们。
5.使用推理引擎API的通用工作流程
1.创建推理引擎核心对象
创建一个InferenceEngine::Core可与不同设备一起使用的对象,所有设备插件均由该Core对象内部管理。使用自定义nGraph操作(InferenceEngine::Core::AddExtension)注册扩展名。
2.读取中间表示
使用InferenceEngine::Core该类,将中间表示文件读取到InferenceEngine::CNNNetwork该类的对象中。此类表示主机内存中的网络。
3.准备输入和输出格式
加载网络后,指定输入和输出精度以及网络上的布局。对于这些规范,请使用InferenceEngine::CNNNetwork::getInputsInfo()和InferenceEngine::CNNNetwork::getOutputsInfo()。
4.传递设备,加载配置
传递特定于此设备的每个设备加载配置(InferenceEngine::Core::SetConfig),并将扩展名注册到该设备(InferenceEngine::Core::AddExtension)。
5.编译和加载网络到设备
使用InferenceEngine::Core::LoadNetwork()与特定的设备(例如方法CPU,GPU等)来编译和加载网络在设备上。传递针对此编译和加载操作的每个目标加载配置。
6.设置输入数据
加载网络后,您将拥有一个InferenceEngine::ExecutableNetwork对象。使用此对象创建一个InferenceEngine::InferRequest,您在其中发出信号通知输入缓冲区用于输入和输出。指定设备分配的内存,然后将其直接复制到设备内存中,或者告诉设备使用您的应用程序内存来保存副本。
7.执行
现在定义了输入和输出存储器,选择执行模式:
同步- InferenceEngine::InferRequest::Infer()方法。阻塞直到推断完成。
异步- InferenceEngine::InferRequest::StartAsync()方法。使用`InferenceEngine::InferRequest::Wait()方法(0超时)检查状态,等待或指定完成回调。
8.获取输出
推断完成后,获取输出内存或读取之前提供的内存。使用InferenceEngine::IInferRequest::GetBlob()方法执行此操作。
6.Inference Engine还可以做什么:
可以报告实际的运行时性能计数器,还可以感知哪些设备已连接并可以使用,还可以获取实际物理状况的实时指示。
7.在特定设备上影响神经网络性能的因素:
1.神经网络本身的拓扑或架构,比如各层之间的连接,内存消耗,图像输入大小等都是主要因素,因此需要选择一个合适的网络
2.目标设备的不同,也会影响神经网络性能。选择适合的设备,要综合考虑价格,功耗范围等因素
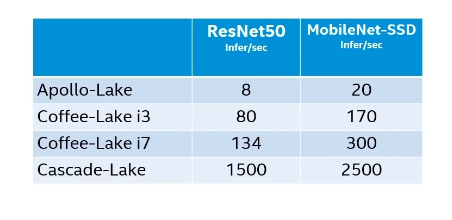
8.模型精度
- 在特定设备上选择最合适的模型精度
- 优化运行时间和图像大小
- INT8在支持“DL Boost”的系统可以提升性能
Intel指令集架构具有许多数据打包类型,因此你可以使用一种数据打包类型将许多数据打包,然后一次对所有数据移项操作,我们称之为单指令,多数据。

数据格式能带来的优势,我们要为特定设备选择最佳数据格式,并非所有的设备都支持所有的数据格式,使用较小的数据类型会占用较小的内存空间,并减少操作量和加快执行速度,支持“DL Boost”的系统可以通过“DL Boost”指令来提供额外的性能提升。

9.批处理
推理引擎可以利用批次为所有的图像只加载一次权重,并帮助提升其他方面的效率,但是大批次也会带来延迟增加和更大的内存占用,因此对于延迟更重要的更多实施用途而言,小批次通常更适合。
10.异步执行
最终我们处理的是视频或者一系列的图像,在同步模式下每个阶段等待流水线完成,这样会降低性能。
另一种方式是,我们可以发送推理请求,而不是等待完成,然后继续准备下一帧或实施其他任务,当推理请求没有阻止执行时,我们可以准备相关帧,并且实施推理操作,这样可以带来吞吐量的巨大提升。
11.cpu的吞吐量模式
吞吐量:吞吐量表示神经网络在一秒内可以处理的帧数,通过FPS每秒帧数来衡量吞吐量的大小
cpu的吞吐量模式支持推理引擎在cpu上同时高效运行多个推理请求,从而显著提高吞吐量,推理引擎可以智能分配cpu资源,并可以配置多个推理请求,当然cpu的核心越多,效率就越高。推理引擎支持通过监控并行推理请求的数量、要使用的线程数以及其他功能来控制其执行。
12.输出推理可用的设备
from __future__ import print_function
import sys
import cv2
import numpy as np
from openvino.inference_engine import IECore
def main():
model_xml = 'model.xml' #The DL model, IR format
model_bin = 'model.bin'
ie = IECore() #Inference-Engine Core object
##print available devices.
#--> Your code here
print('请将可用设备打印于下方:')
devices = ie.available_devices
print(devices) # ['CPU', 'GNA']
if __name__ == '__main__':
sys.exit(main() or 0)
13.OpenVINO的异构插件
我们可以拆分神经网络模型,并在不同的设备上执行不同的层吗?
是的,可以。推理引擎有一个灵活的插件架构,它能够使不同的插件用于不同的设备。因此,相同的神经网络拓扑可以在不同的设备上执行。每个插件都会提供正确的库单元,并为该设备创建一个特定的执行。我们之所以会把同一个拓扑拆分并在多个设备上运行,其背后有多种原因。第一个原因是,某个设备不支持某些层,但是另一个设备支持。比如这个神经网络有一个不被FPGA支持的层,该层能被CPU支持。所以除非你能找到在FPGA上执行的正确方法,否则在CPU上执行该层就合情合理。又或者一个完整的网络无法在某个设备上正常运行,但如果分割出几层又可以的话,那么就应该在别的设备上执行分割出去的层。
OpenVINO具备这个能力,其本身的“hetero”插件可以利用多个插件来执行一个神经网络。这里有两种方法可以实现这一点,这两种方法也可以一起使用。
第一种方法,是直接给特定层指定关联设备或者目标设备,因此基本可以指定在哪个设备上执行哪个层。怎么做到呢,可以通过利用“CNNLayer::affinity”指令设置层的关联设备来实现。在下图的例子中,你可以看到我获取了“qqq”层,并将其分配给CPU执行。
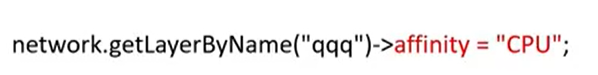
第二种方法,是让Hetero这个异构插件根据特定的优先级别,在多个设备上执行网络层。第一个执行的设备将是第一优先级设备,支持某个特定的层,那么Hetero插件会将其退回到第二优先级设备,以此类推,直到找到支持。在下图的例子中,你可以看到我请求在FPGA上执行此网络,如果遇到无法执行的层,请在CPU上执行。你也可以在这里,按照自己的优先级输入所有的插件名称:CPU、GPU、MYRIAD、FPGA。请注意,某些拓扑对某些设备上异构执行不友好,或者根本无法在这种异构模式下执行,甚至这样做在性能上没有任何意义。另外要注意的是,不同的设备使用不同的数据格式,CPU支持的数据格式是FP32和INT8,GPU支持FP32和FP16,Movidius则支持FP16等。所以在执行前请先读取文件,这样推理引擎会先对数据格式进行自动转换。如果要在GPU上优先执行拓扑,并以CPU作为后备设备,则只需使用FP16格式的IR文件。因为该拓扑的权值将通过hetero插件自动从FP16转换为FP32。它可以提供一定的灵活性,然而那些不被目前设备支持的层,可以转而利用CPU或者其他设备。
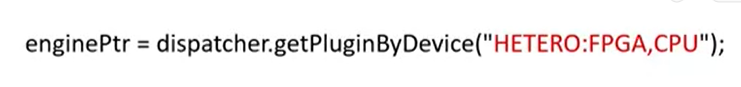
14.Inference Engine的异步操作API
视频处理的过程是逐帧进行的。下面的通道示意图很好的展示了如何进行视频序列的,先解码,然后对一帧进行推理准备,再对这一帧进行推理,然后移到下一帧。等待通道以同步模式逐个阶段地完成,会降低性能。我们其实不需要等待推理完成,而是应该在发送推理请求之后就继续准备下一帧,或者执行其他任务。当推理请求和执行没有冲突时,我们在推理进行的同时就可以准备好帧。这样下来,不需要任何额外支持就可以获得巨大的吞吐量提升。

如下图案例

同步模式下的平均吞吐量
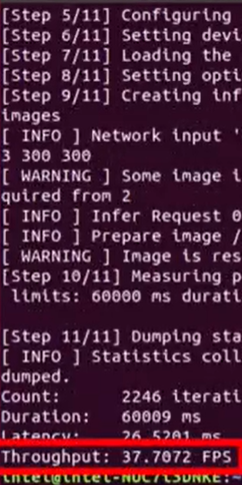
异步模式下的平均吞吐量
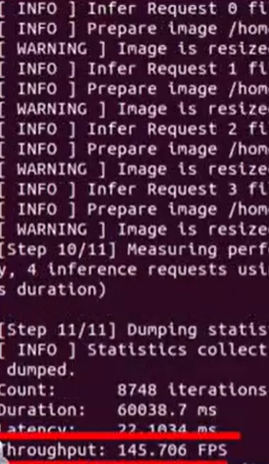
通过对比我们发现,差异挺明显。
转载请注明:康瑶明的博客