
1.模型优化的格式(以squeezenet1.0为例)
我们在做模型优化的时候,使用不同的数据和权重格式该怎么权衡呢?我们不能为了把权重压缩到较小的格式而不考虑模型的准确性,那将会引起量化错误。不同的设备支持的格式也不同,那么我们是如何做不同格式的模型优化呢?
- 1.下载模型
sudo -E ./downloader.py --name squeezenet1.0 -o ~/Documents/

- 2.使用
model_optimizer进行模型优化
执行下面命令,优化为FP32格式的IR文件
export model=~/Documents/public/squeezenet1.0
sudo python3 ./mo_caffe.py --input_model $model/squeezenet1.0.caffemodel --output_dir $model --model_name squeezenet1.0_FP32 --data_type FP32
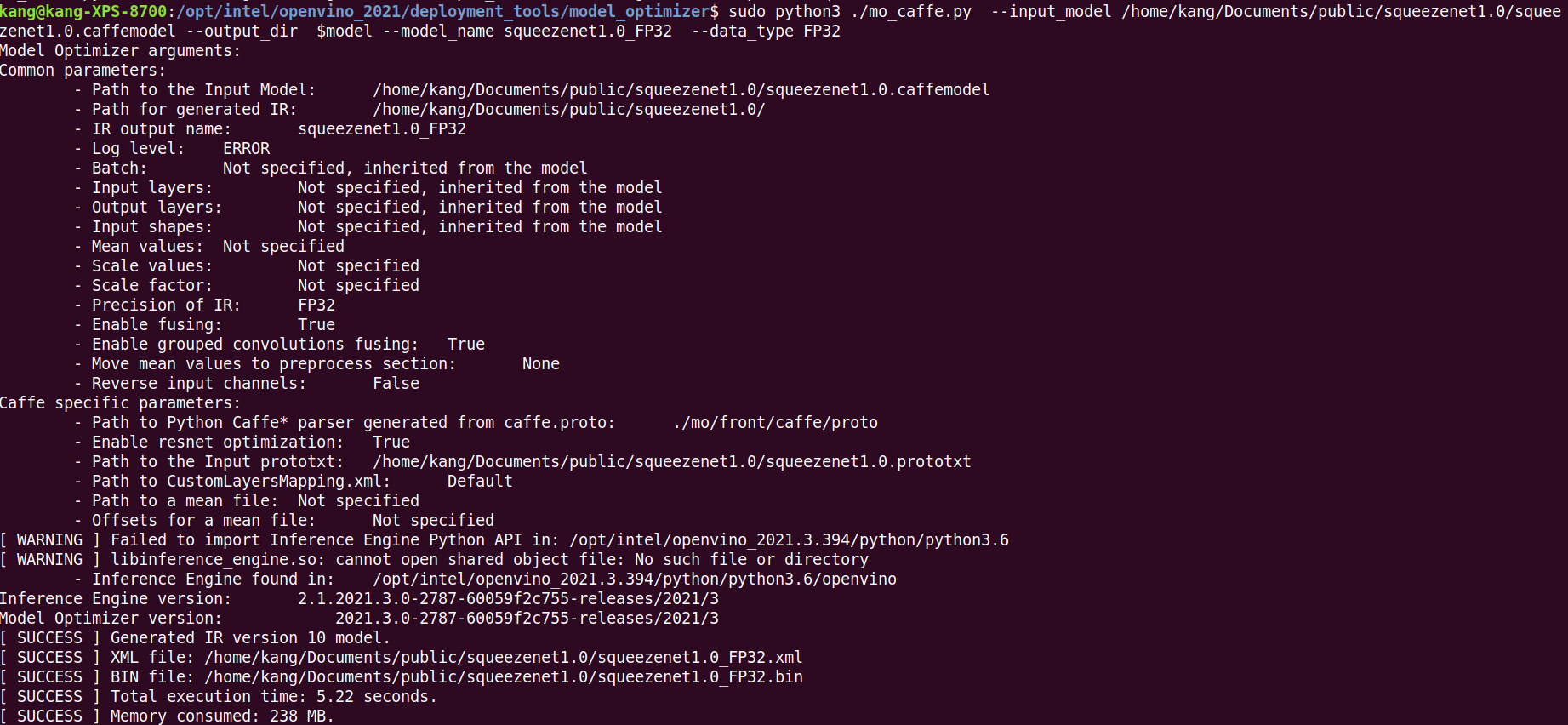
如果我们想使用GPU来加速推理,可以优化为FP16的格式。
sudo python3 ./mo_caffe.py --input_model /home/kang/Documents/public/squeezenet1.0/squeezenet1.0.caffemodel --output_dir $model --model_name squeezenet1.0_FP16 --data_type FP16
现在,我们的路径下有了FP32和FP16两种格式可选。
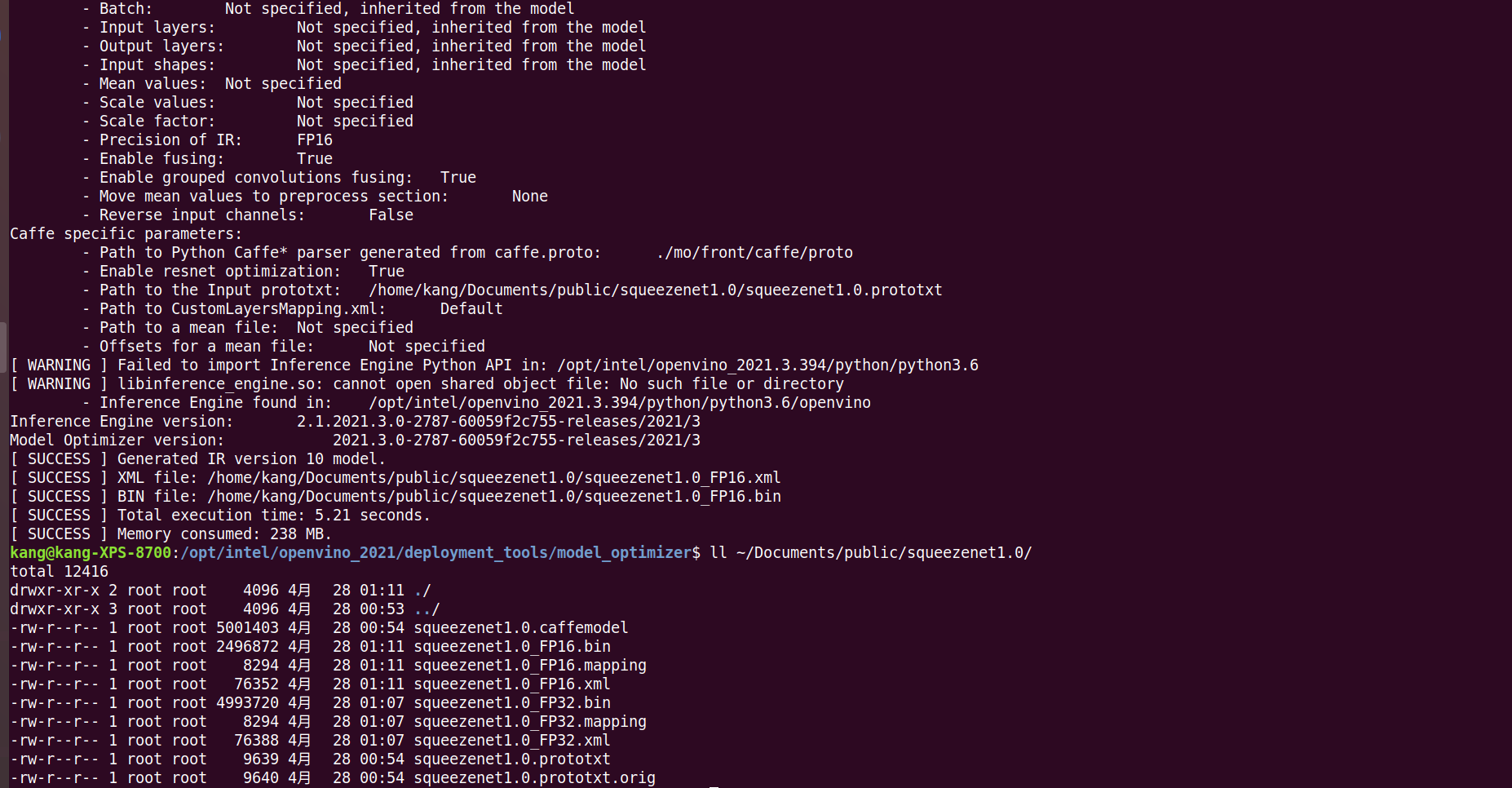
2.调整拓扑网络
Model Optimizer可以查看拓扑,调整网络的输入大小,为批处理准备模型。
查看原来的网络结构,是[1,3,227,227]
head /home/kang/Documents/public/squeezenet1.0/squeezenet1.0_FP16.xml

执行命令,我们修改为[1,3,100,100]
sudo python3 ./mo_caffe.py --input_model $model/squeezenet1.0.caffemodel --output_dir $model --model_name squeezenet1.0_FP32 --input_shape [1,3,100,100]
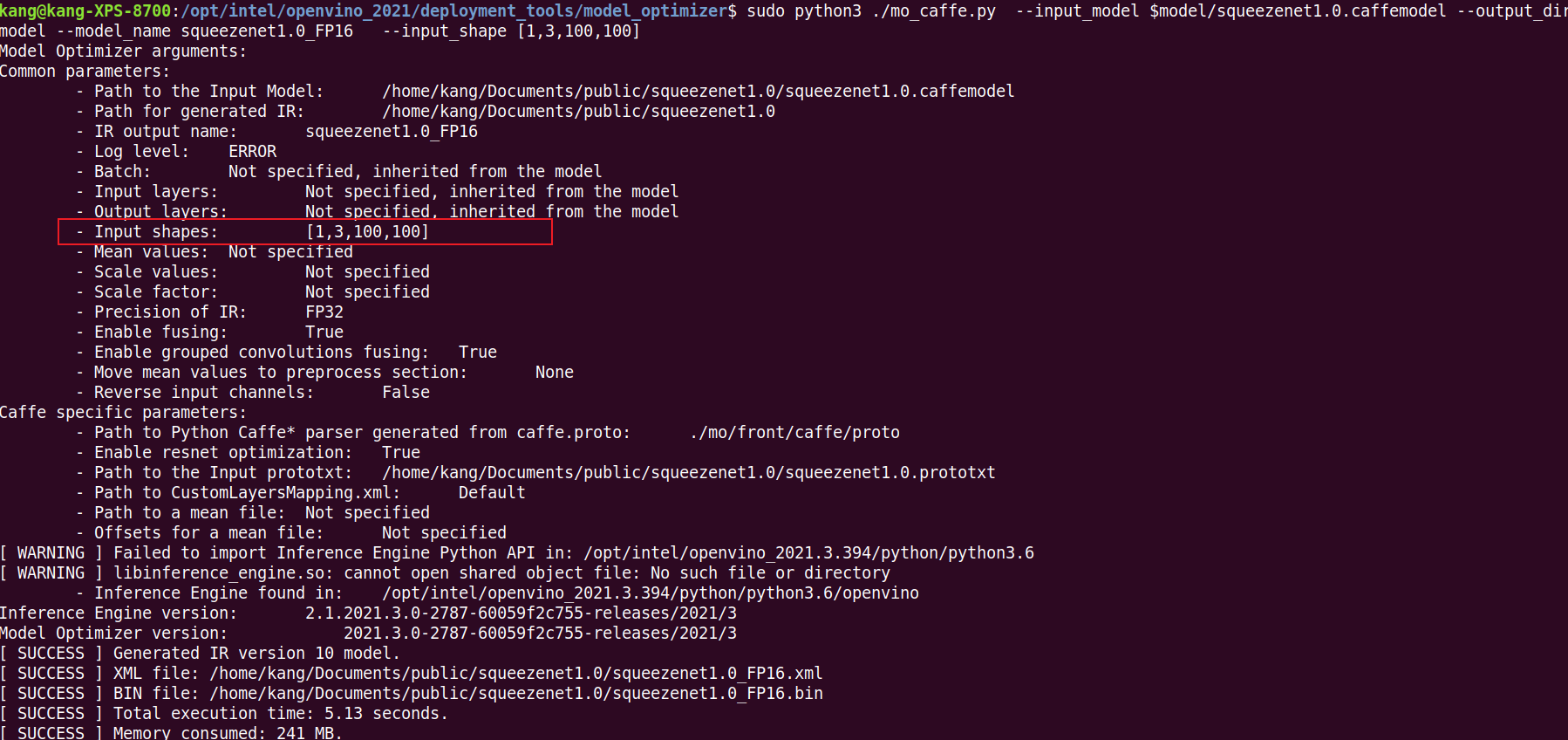
查看已经修改成功

当我们更改原来的model_name,并且添加参数--batch 4,重新模型优化
sudo python3 ./mo_caffe.py, --input_model $model/squeezenet1.0.caffemodel --output_dir $model --model_name batch4 --batch 4
可以看到网络结构修改为[4,3,227,227]

3.调整拓扑网络
- 1.剪切部分网络
- 2.预处理输入数据
4.使用Model Optimizer转换ONNX模型
Model Optimizer支持ONNX,所以我们可以将pyTorch,caffe-2和其他模型转换为ONNX模型,然后使用模型优化器进行转换为IR文件。
-
1.当我们下载一个ONNX模型后,要先了解模型优化器支持的ONNX图层列表是哪些,这个可以在官网的相关文档中查看。
-
2.确保我们具备执行ONNX的先决条件,执行下面指令
install-prerequisites-onnx.sh
-
3.通过Netron软件查看ONNX的模型拓扑
-
4.转换模型,生成IR文件