
1. 什么是计算机视觉
什么是视频?
视频是一系列连续的图像,这些图像的移动速度足够快,让我们的眼睛看到了连续平滑的效果。
什么是图像?
图像是多个像素组成的阵列,每个像素都有强度级,或有 R,G,B值混合而成的色彩。我们可以操纵图像来模糊,锐化图像或者执行其他任务。
什么是OpenCV?
OpenCV是一款用于加速计算机视觉的intel软件,可以在intel硬件上加速,是计算机视觉领域最常用的工具库。可用于开发实时的图像处理、计算机视觉以及模式识别程序,并且兼容多种操作系统和平台。可以轻松对图像进行缩放、调整、过滤、查找边缘或者其他特征。除此以外还有很多高级功能,比如面部检测等等。OpenCV被包含在OpenVINO套件中,如果安装了OpenVINO,就拥有了OpenCV。
2. 视频技术概述
一张图片大概有200万个像素,1 Frame = 1920 x 1080 pixels,假设一个 像素有三个字节,1 pixel = 3 bytes (R,G,B)。那么一张图片就是6.2MB大小,1 Frame = 1920 x 1080 x 3 bytes = 6,220,800 Bytes (6.2MB),为了视频看起来自然流畅,每秒需要播放25张图片,也就是155MB大小,1 Second = 6.2 MB x 25 = 155 MB,那么一分钟就是9.3GB大小 – 1 Minute = 9.3 GB
然而我们无法传输这么庞大的数据量,所以我们网上下载的视频都是经过压缩的,以B站为例大概一分钟80MB,压缩比为100。为了压缩中我们会使用冗余来替换视频中出现的重复性数据。冗余分为空间冗余和时间冗余。
在互联网传输中我们会使用压缩和解压缩技术,这时就需要一套规则来执行压缩和解压缩,使得两边得到相同的视频,这套规则称为编解码器。常见的编解码器有 H.264 或 avc。另一个常见的编解码器为H.265 或 hevc。
我们常说的视频文件,其实是可以容纳许多文件的容器,mp4其实是个容器文件,它保存带显示的视频流,如H.264,保存带有播放的音频流,如mp3,还有原数据,如分辨率、比特率等各种信息。
3. Intel集成显卡如何加速视频处理
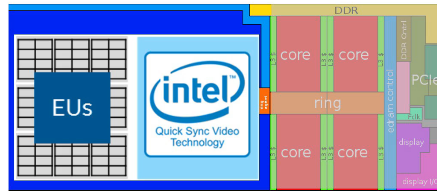
Intel CPU可以执行视频处理,但Intel 集成显卡具备专门的视频加速功能,该功能专为执行视频编解码构建,效率更高,称之为”Quick Sync Video Technology”,意为快速视频同步技术。集成显卡包含两大硬件模块:EU和Quick Sync Video Technology。
-
EU执行单元,可视为微型处理器,用于处理图形渲染等任务。
-
Quick Sync Video Technology包括了加速视频处理,编码,解码等等。如下图:
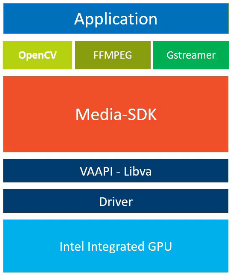
GPU的分层结构通常是,在GPU的上层,是驱动程序。驱动程序的上层,是VAAPPI-Libva,它是一个视频加速API。对集成显卡进行编程,以支持视频解码,编码和处理的一种方法是使用 Media-SDK,它位于VAAPPI-Libva的上层。它可以帮助使用c++ 和python编写的API在多个平台、多个系统上完成编解码工作。我们可以通过OpenCV、FFMPEG、Gstreamer使Media-SDK。OpenVINO软件中已经安装了 Media-SDK。下图为GPU的分层结构图:
4. 如何给视觉应用中的神经网络加速 – DLDT
比如检测一张图片是不是猫,我们要构建一个特征检测器,检测对象是否有四条腿,一条尾巴和相应的颜色,相应的大小等。需要把所有的输入特征放在一个函数中,如果组合是正确的,那么我们就找到了一只猫。
通常我们获取一张输入图片,提取特征值,每个特征值乘以一个权重,这些相乘的结果如果是1,那么就是猫。如果是0表示不是猫。取一只猫的图片,进行特征乘法运算的时候,当换成另外一只颜色完全不同的猫,这时候就需要适当的调整颜色,特征的权重,更改权重值,以便检测为猫。狗也是四条腿,一条尾巴,为了进行区分不同,就需要构建一个更复杂的函数。大量神经元按照特定的规则组成的神经网络,在一个神经网络中有很多层。我们向神经网络输入大量的图像,改进权重,降低错误率,以获得一个具有特定权重的神经网络,这一过程叫做训练。向神经网络输入一张新的猫的图像,并得到答案的过程,称为推理。
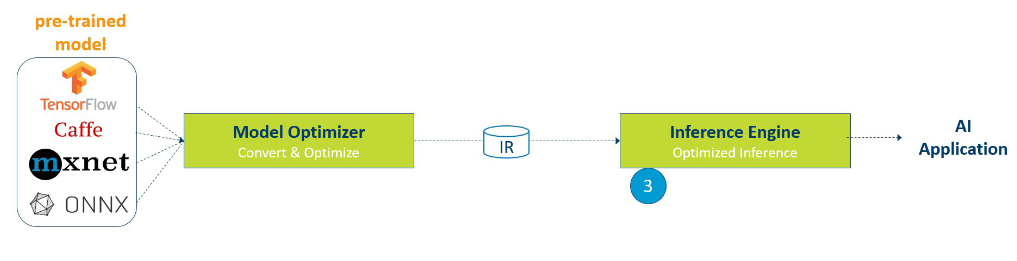
openvino中,DLDT(Deep Learning Deployment Toolkit)推理流程的运行方式,开始于一个训练好的模型,支持多种深度学习框架的模型,比如tensorflow,caffee,mxnet,onnx格式。然后使用model Optimizer转化为IR中间表示。model Optimizer是一个python脚本,不仅支持转换格式,还支持更改权重格式,优化拓扑等。之后推理引擎(Inference Engine)将读取IR文件,并在应用中进行推理。如下图:
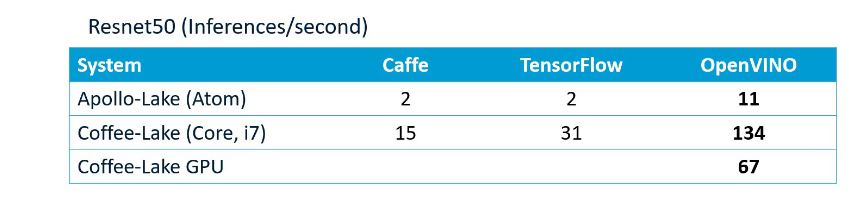
只需要做很小的代码改动,就可以在Inter的CPU、GPU、Myriad、HDDL、FPGA等多种设备上运行。推理引擎使用不同的库来实现神经网络的运算,并在各种Intel设备上执行计算,下图实例可以看到openvino的DLDT可以加速推理优势:
5. 使用AI推理对视频进行分析的流程
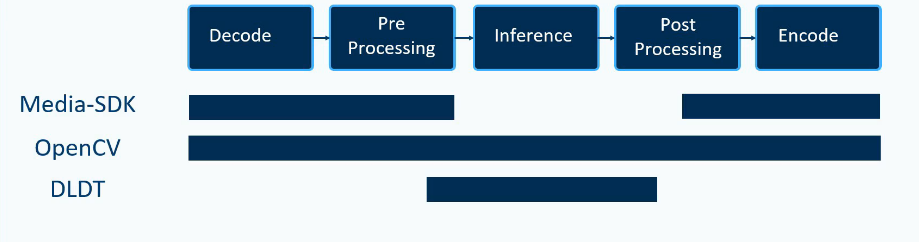
- Decode: 对压缩格式的文件或者视频流进行解码
- Pre Processing: 对图像的预处理操作,用于某些时候图像质量不够好,进行锐化、亮度等调整来改善图像。也可以用于对原有图像的缩小,或裁剪图像中我们感兴趣的部分,也可以跳过某些帧,推理所有帧的操作。
- Inference: 该阶段可能包含多个推理,可以对对象进行分类与检测,然后尝试做更多的分类。
- Post Processing: 后期处理。在获取推理结果后,有时想继续处理原始图像。
- Encode: 编码。有时想保存所有的帧,或者压缩视频,以便发送或存储视频。
- Midia-SDK: 一般用于处理视频的编解码以及图像处理。
- OpenCV: 基本可以做上图流程的所有工作,但是有时需要调用Midia-SDK或者DLDT。
- DLDT: 主要用于深度学习的推理加速。
6. OpenVINO支持的平台
- 支持的操作系统:windows、linux、mac os
- 支持的硬件:凌动、酷睿、至强、Movidius计算棒、FPGA等。
- 我们可以使用OpenCV处理计算机视觉,Midia-SDK进行视频解码、编码与处理,使用DLDT进行推理。
7. netron工具
-
功能:netron工具可以查看网络模型的层和功能
-
下载:最新ubuntu下载的版本是 Netron-4.3.8.AppImage 下载地址:https://github.com/lutzroeder/Netron
-
运行:该文件不需要安装,找到该文件,右键文件 –> 属性 –> 权限 –> 勾选允许作为程序执行文件,然后双击文件就可以运行
-
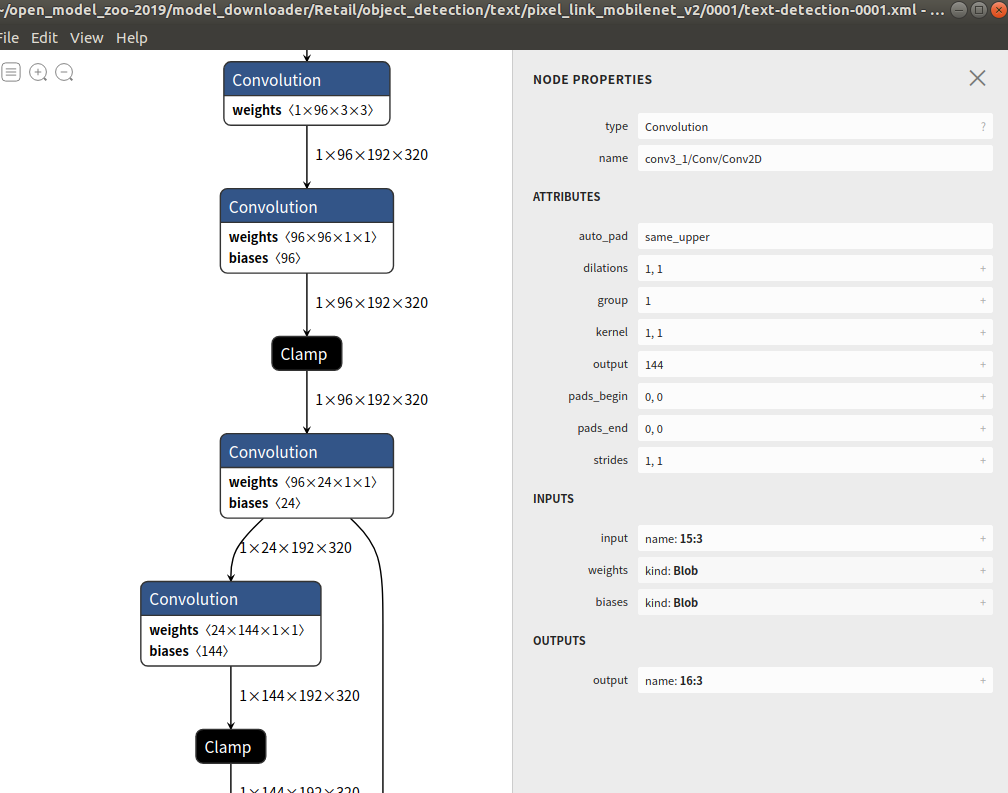
使用:这里以text-detection-0001.xml为例,用netron双击打开该文件,就可以看到模型相关的网络参数
8. 从数据采集到AI产品诞生的流程
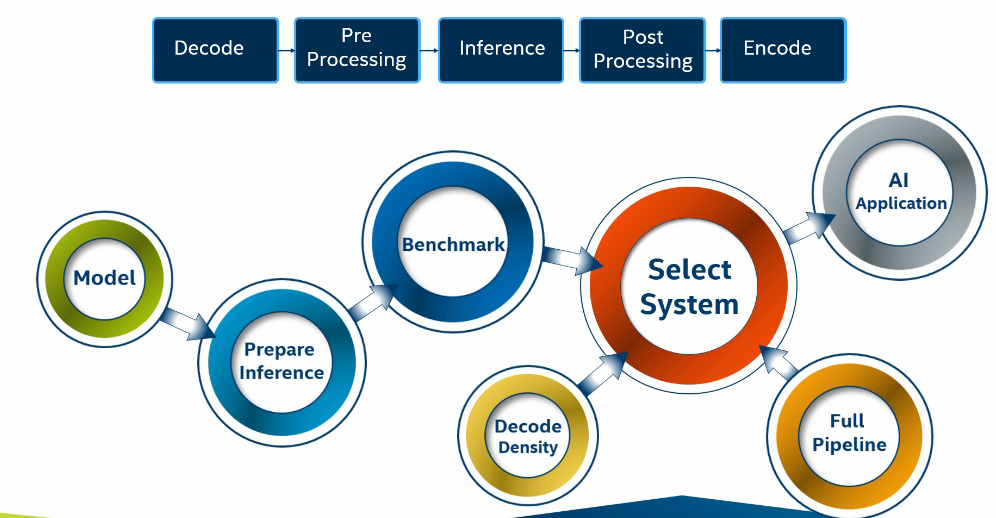
获取一个深度学习模型
可以从多种方法实现:
- 使用openvino的模型下载器open_model_zoo下载公开的模型
- 从头开始训练一个模型,首先需要收集数据,然后使用计算机视觉技术清洗数据,裁剪分离目标区域,接着对得到的图像进行标注(CVAT是一款不错的计算机视觉标注工具),然后使用训练工具例如TF对模型进行训练,训练好的模型可以用于推理。
- 别的地方下载模型。
对模型进行推理
- 把准备好的模型进行推理,模型一般在云环境运行,数据格式一般为浮点型数据。
基准性能测试Benchmark
- Benchmark可以进行性能指标的评测,比如每秒可以执行多少次推理,可以使用多种优化技术和多种数据格式对这个模型进行性能指标的评测,最终选择能够满足你要求的平台。
Media-SDK编解码
- 模型可以运行以后,我们想知道这个设备支持多少个摄像头,希望它支持尽可能多的摄像头或者视频流,从而降低成本,为此我们需要了解解码能力和编码能力。
Gstreamer+OpenVINO
- 视频流和编解码是一起运行的,一起运行时,有时候结果并不能总让我们满意。在AI开发的过程中,合理运用已经集成好的软件工具能减小的开发工作量。例如,使用Gstreamer+OpenVINO™的组合,可以完整提供图像处理流程中的包括编解码,图像处理,以及图像推理的功能。
- 要想快速方便的模拟整个系统的性能而又不构建应用,只想验证这些是否适合我们的系统,那么可以使用Gstreamer Video Analytics(GVA) Plugin 这个插件,GVA是用于构建视频处理流程的简单使用平台。该插件可以实现检测、分类、识别和可视化的若干个新元素,我们就可以用GVA构建一个视频分析流程。包含两个推理阶段:输入视频流,解码并输出结果和进行推理
9. 推理的性能评估,intel有什么工具
- Benchmark App用来直接输入模型,获取模型的FPS参数性能;
- Dev-Cloud是一个巨大的服务器,里面装载了最新的Intel®硬件,可以供开发者运行OpenVINO™在最新的设备上测试性能;
- DL Workbench是一个网页应用,可以直接通过浏览器访问一个OpenVINO™工具套件图形化的性能调优与测试平台。
转载请注明:康瑶明的博客