
效果展示
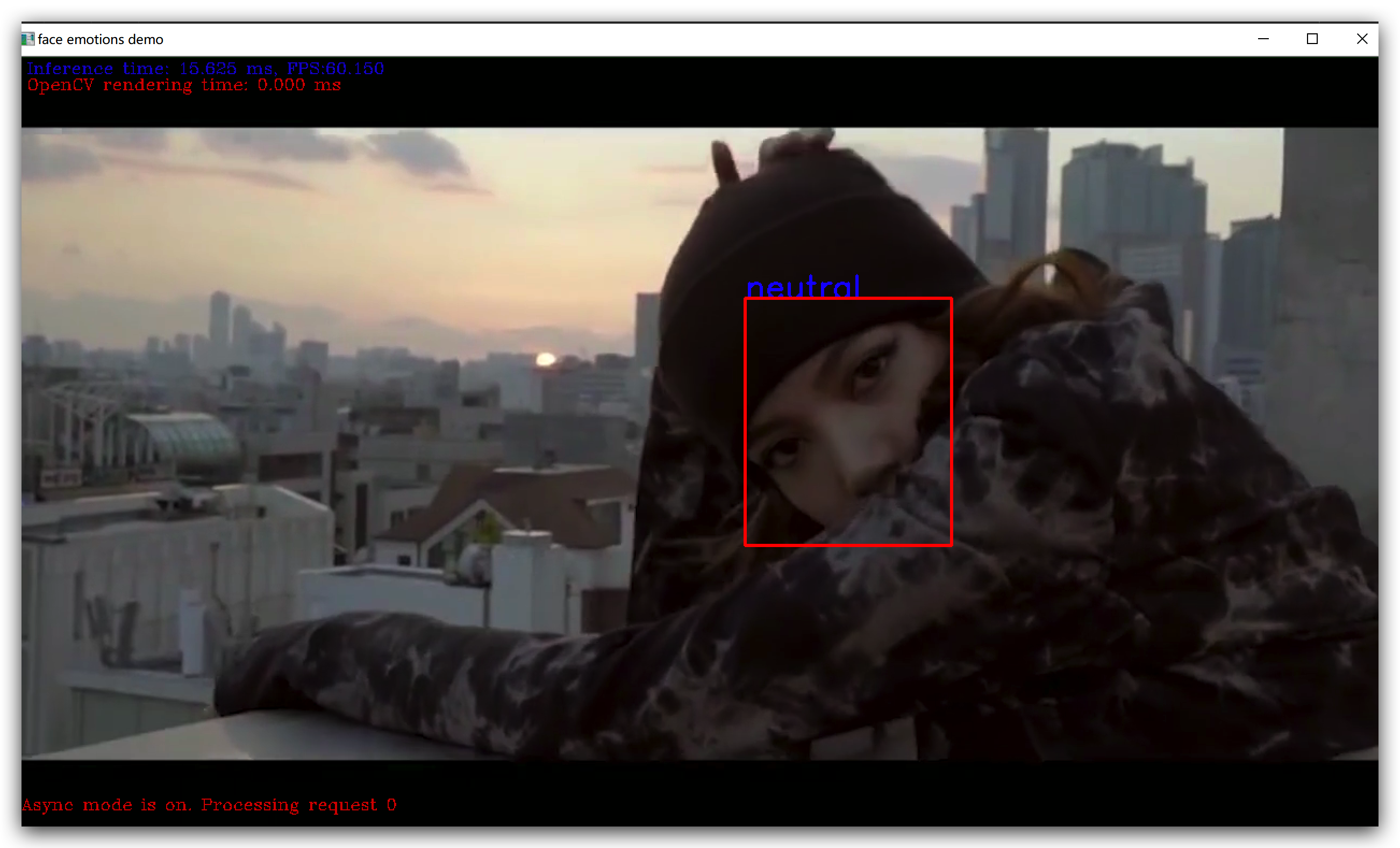
一、 准备流程:
1. 在python环境中加载openvino
打开openvino安装目录如: C:\Intel\openvino\python\python3.6
把目录下的openvino文件夹复制到
系统的python环境安装目录下如: C:\Python36\Lib\site-packages
2. 编译
C:\Intel\openvino\deployment_tools\inference_engine\samples 路径下执行:
build_samples_msvc2017.bat
执行完后在
C:\Users\kang\Documents\Intel\OpenVINO 目录
可以看到生成的
inference_engine_samples_build_2017 文件目录
在build目录中也可以找到cpu_extension:
cpu_extension = "C:\Users\kang\Documents\Intel\OpenVINO\inference_engine_samples_build_2017\intel64\Release\cpu_extension.dll"
3. 下载模型,记录路径
face-detection-adas-0001
emotions-recognition-retail-0003
model_xml = ""
model_bin = ""
二、 参数介绍:
1. emotions提取
- 基于MobileNet v1版本 · 输入格式:[1x3x384x672]= BCHW · 输出格式:[1, 1, N, 7] = [image_id, label, conf, x_min, y_min, x_max, y_max]
- 表情识别网络 – 输入-[1x3x64x64]=BCHW · 输出格式- [1, 5, 1, 1] · 检测五种表情 (‘neutral’, ‘happy’, ‘sad’, ‘surprise’, ‘anger’)
2. python版本的api介绍
- 同步调用,执行输入
- landmark_res = exec_emotions_net.infer(inputs={input_blob: [face_roi]})
3. 获取输出
- landmark_res = landmark_res[‘prob_emotion’]
- landmark_res = np.reshape(landmark_res, (5))
- landmark_res = labels[np.argmax(landmark_res)]
三、 附录代码:
import sys
import cv2
import numpy as np
import time
import logging as log
from openvino.inference_engine import IENetwork, IEPlugin
plugin_dir = "C:/Intel/openvino/deployment_tools/inference_engine/bin/intel64/Release"
cpu_extension = "C:/Users/kang/Documents/Intel/OpenVINO/inference_engine_samples_build_2017/intel64/Release/cpu_extension.dll"
# face-detection-adas-0001
model_xml = "C:/Users/kang/Downloads/openvino_sample_show/open_model_zoo/model_downloader/Transportation/object_detection/face/pruned_mobilenet_reduced_ssd_shared_weights/dldt/face-detection-adas-0001.xml"
model_bin = "C:/Users/kang/Downloads/openvino_sample_show/open_model_zoo/model_downloader/Transportation/object_detection/face/pruned_mobilenet_reduced_ssd_shared_weights/dldt/face-detection-adas-0001.bin"
# emotions-recognition-retail-0003
emotions_xml = "C:/Users/kang/Downloads/openvino_sample_show/open_model_zoo/model_downloader/Retail/object_attributes/emotions_recognition/0003/dldt/emotions-recognition-retail-0003.xml"
emotions_bin = "C:/Users/kang/Downloads/openvino_sample_show/open_model_zoo/model_downloader/Retail/object_attributes/emotions_recognition/0003/dldt/emotions-recognition-retail-0003.bin"
labels = ['neutral', 'happy', 'sad', 'surprise', 'anger']
def face_emotions_demo():
log.basicConfig(format="[ %(levelname)s ] %(message)s",
level=log.INFO,
stream=sys.stdout)
# Plugin initialization for specified device and load extensions library if specified
log.info("Initializing plugin for {} device...".format("CPU"))
plugin = IEPlugin(device="CPU", plugin_dirs=plugin_dir)
plugin.add_cpu_extension(cpu_extension)
# Read IR
log.info("Reading IR...")
net = IENetwork(model=model_xml, weights=model_bin)
emotions_net = IENetwork(model=emotions_xml, weights=emotions_bin)
if plugin.device == "CPU":
supported_layers = plugin.get_supported_layers(net)
not_supported_layers = [
l for l in net.layers.keys() if l not in supported_layers
]
if len(not_supported_layers) != 0:
log.error(
"Following layers are not supported by the plugin for specified device {}:\n {}"
.format(plugin.device, ', '.join(not_supported_layers)))
log.error(
"Please try to specify cpu extensions library path in demo's command line parameters using -l "
"or --cpu_extension command line argument")
sys.exit(1)
assert len(
net.inputs.keys()) == 1, "Demo supports only single input topologies"
assert len(net.outputs) == 1, "Demo supports only single output topologies"
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
em_input_blob = next(iter(emotions_net.inputs))
em_out_blob = next(iter(emotions_net.outputs))
log.info("Loading IR to the plugin...")
# 生成可执行网络,异步执行 num_requests=2
exec_net = plugin.load(network=net, num_requests=2)
exec_emotions_net = plugin.load(network=emotions_net)
# Read and pre-process input image
n, c, h, w = net.inputs[input_blob].shape
en, ec, eh, ew = emotions_net.inputs[em_input_blob].shape
del net
del emotions_net
cap = cv2.VideoCapture("C:/Users/kang/Downloads/openvino_sample_show/material/face_detection_demo.mp4")
cur_request_id = 0
next_request_id = 1
log.info("Starting inference in async mode...")
log.info("To switch between sync and async modes press Tab button")
log.info("To stop the demo execution press Esc button")
is_async_mode = True
render_time = 0
ret, frame = cap.read()
print(
"To close the application, press 'CTRL+C' or any key with focus on the output window"
)
while cap.isOpened():
if is_async_mode:
ret, next_frame = cap.read()
else:
ret, frame = cap.read()
if not ret:
break
initial_w = cap.get(3)
initial_h = cap.get(4)
inf_start = time.time()
if is_async_mode:
in_frame = cv2.resize(next_frame, (w, h))
in_frame = in_frame.transpose(
(2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
exec_net.start_async(request_id=next_request_id,
inputs={input_blob: in_frame})
else:
in_frame = cv2.resize(frame, (w, h))
in_frame = in_frame.transpose(
(2, 0, 1)) # Change data layout from HWC to CHW
in_frame = in_frame.reshape((n, c, h, w))
exec_net.start_async(request_id=cur_request_id,
inputs={input_blob: in_frame})
if exec_net.requests[cur_request_id].wait(-1) == 0:
res = exec_net.requests[cur_request_id].outputs[out_blob]
# 输出格式:[1,1,N,7] 从N行人脸中找到7个值 = [image_id,label,conf,x_min,y_min,x_max,y_max]
for obj in res[0][0]:
if obj[2] > 0.5:
xmin = int(obj[3] * initial_w)
ymin = int(obj[4] * initial_h)
xmax = int(obj[5] * initial_w)
ymax = int(obj[6] * initial_h)
if xmin > 0 and ymin > 0 and (xmax < initial_w) and (ymax < initial_h):
roi = frame[ymin:ymax,xmin:xmax,:]
face_roi = cv2.resize(roi,(ew,eh))
face_roi =face_roi.transpose((2, 0, 1))
face_roi= face_roi.reshape((en, ec, eh, ew))
# 解析结果
landmark_res = exec_emotions_net.infer(inputs={input_blob: [face_roi]})
landmark_res = landmark_res['prob_emotion']
landmark_res = np.reshape(landmark_res, (5))
landmark_res = labels[np.argmax(landmark_res)]
cv2.putText(frame, landmark_res, (np.int32(xmin), np.int32(ymin)), cv2.FONT_HERSHEY_SIMPLEX, 1.0,
(255, 0, 0), 2)
cv2.rectangle(frame, (np.int32(xmin), np.int32(ymin)), (np.int32(xmax), np.int32(ymax)),
(0, 0, 255), 2, 8, 0)
cv2.rectangle(frame, (xmin,ymin), (xmax,ymax), (0, 0, 255), 2, 8, 0)
inf_end = time.time()
det_time = inf_end - inf_start
# Draw performance stats
inf_time_message = "Inference time: {:.3f} ms, FPS:{:.3f}".format(det_time * 1000, 1000 / (det_time*1000 + 1))
render_time_message = "OpenCV rendering time: {:.3f} ms".format(
render_time * 1000)
async_mode_message = "Async mode is on. Processing request {}".format(cur_request_id) if is_async_mode else \
"Async mode is off. Processing request {}".format(cur_request_id)
cv2.putText(frame, inf_time_message, (15, 15),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (200, 10, 10), 1)
cv2.putText(frame, render_time_message, (15, 30),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
cv2.putText(frame, async_mode_message, (10, int(initial_h - 20)),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1)
render_start = time.time()
cv2.imshow("face emotions demo", frame)
render_end = time.time()
render_time = render_end - render_start
if is_async_mode:
cur_request_id, next_request_id = next_request_id, cur_request_id
frame = next_frame
key = cv2.waitKey(1)
if key == 27:
break
cv2.destroyAllWindows()
del exec_net
del exec_emotions_net
del plugin
if __name__ == '__main__':
sys.exit(face_emotions_demo() or 0)
转载请注明:康瑶明的博客